マイクロソフト、10万台以上のGPUを搭載した「惑星規模」のAIインフラを運用
マイクロソフトは2月22日に「Singularity」(シンギュラリティ)と名付けたAIワークロードのための惑星規模の分散スケジューリングサービスを運用していることを明らかにした。


マイクロソフトは2月22日に「Singularity」(シンギュラリティ)と名付けたAIワークロードのための惑星規模の分散スケジューリングサービスを運用していることを明らかにした。
26人のマイクロソフト社員が共著したプリプレス論文に記述されているSingularityの目的は、深層学習ワークロードの高い利用率を促進することで、ソフトウェアの巨人がコストをコントロールするのに役立つと説明されている。
Singularityは、この論文で「全世界のAIアクセラレータ(GPU、FPGAなど)の集合において、ディープラーニングワークロードの正しさや性能に影響を与えることなく、高い利用率を推進するために透過的に先取りして弾力的に拡張できる新しいワークロード認識スケジューラ」として説明されているものだ。
この論文では、Singularity自体よりもスケジューラーに多くの時間を費やしているが、システムのアーキテクチャを示すいくつかの図を提示している。Singularityの性能分析では、Xeon Platinum 8168を使用したNvidia DGX-2サーバーでのテスト実行に言及しており、各20コアの2ソケット、サーバーあたり8つのV100モデルGPU、692GBのRAM、InfiniBandでネットワーク接続されていることが示されている。SingularityのGPUは数十万個で、さらにFPGAやその他のアクセラレータを搭載している可能性もあり、マイクロソフトは少なくとも数万台のこうしたサーバーを保有していることになる。
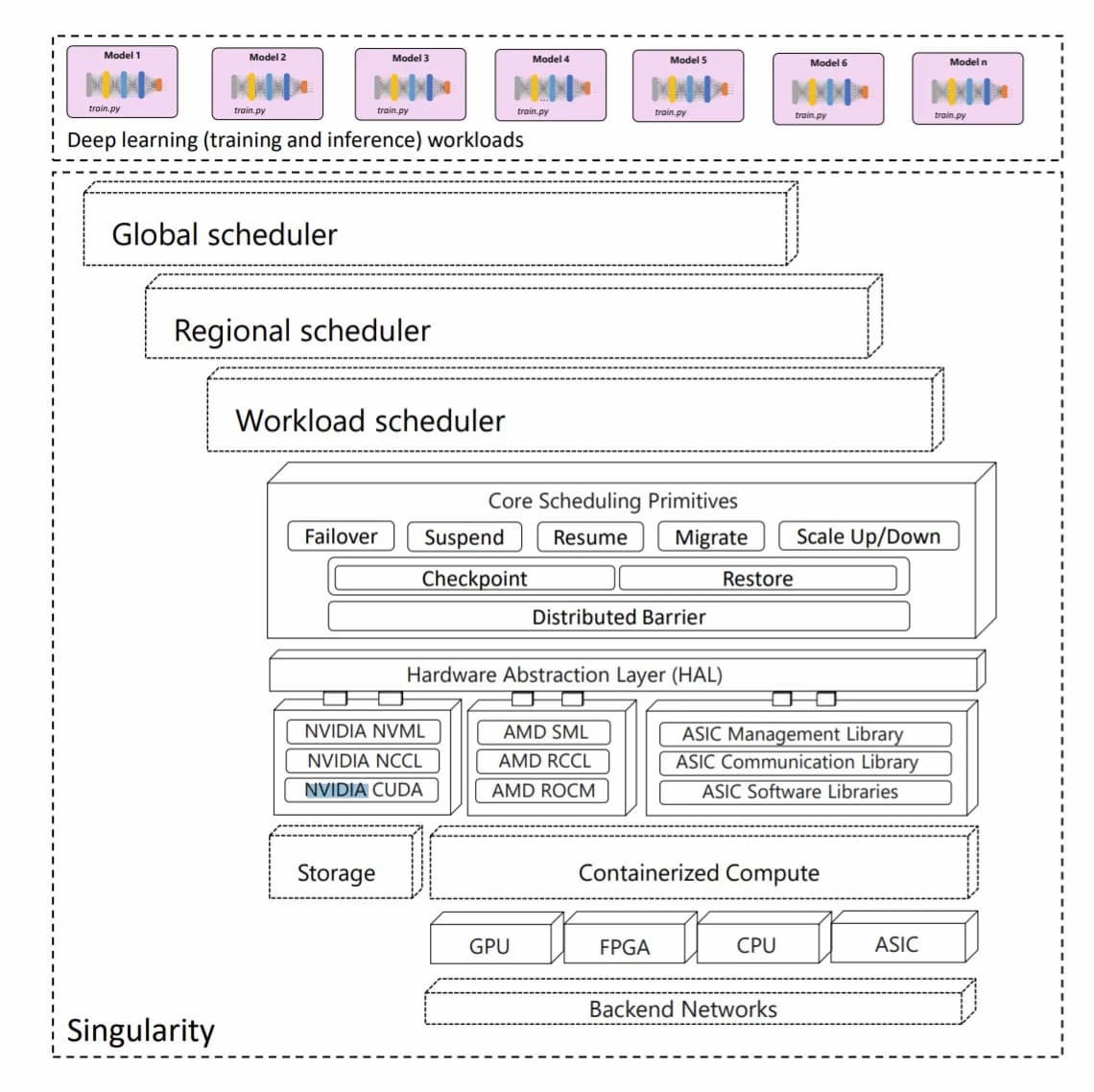
この論文では、Singularityのスケーリング技術とスケジューラーに着目しており、コスト削減と信頼性向上のために秘策であると主張している。
このソフトウェアは、ジョブとアクセラレータリソースを自動的に切り離す。つまり、ジョブがスケールアップまたはスケールダウンする際には、「ワーカーがマッピングされるデバイスの数を変更するだけで、ジョブのサイズ(すなわちワーカーの総数)は、ジョブを実行する物理デバイスの数に関係なく同じままなので、ユーザーには完全に透過的だ」。
これは、「レプリカ・スプライシング」と呼ばれる新しい技術により、各ワーカーがデバイスのメモリ全体を使用できるようにしながら、無視できるオーバーヘッドで同じデバイス上の複数のワーカーをタイムスライスすることが可能になったおかげで実現した。
これを実現するには、著者らが「デバイスプロキシ」と呼ぶ、「独自のアドレス空間で動作し、物理的なアクセラレータデバイスと一対一で対応する」ものが必要だ。ジョブワーカーがデバイスAPIを開始すると、それらはインターセプトされ、別のアドレス空間で実行され、その寿命がワーカープロセスの寿命から切り離されたデバイスプロキシプロセスに共有メモリ上で送られる。
以上により、より多くのジョブを、より効率的にスケジュールすることが可能になり、何千台ものサーバーがより長い時間サービスを受けることができるようになる。また、スケーラビリティを向上させ、中断することなく迅速に拡張することができる。
「Singularityは、深層学習ワークロードのスケジューリングにおいて大きなブレークスルーを達成し、弾力性などのニッチな機能を、スケジューラが厳しいサービスレベル合意書(SLA)を実施する際に信頼できる主流の常時稼働機能に転換した」と論文は結論付けている。
毎月70本のハイエンド記事が読み放題の有料購読が初月無料
アクシオンではクイックな情報は無料で公開していますが、より重要で死活的な情報は有料会員にのみ提供しております。有料会員は弊社オリジナルコンテンツに加え、ブルームバーグ、サイエンティフィック・アメリカン、ニューヨーク・タイムズから厳選された記事、月70本以上にアクセスができるようになります。現在、初月無料キャンペーン中。下の画像をクリックしてください。




