DeepMindとUCLがメタ強化学習向けの3Dビデオゲームを開発
DeepMindとUCLが開発した3Dゲームは、メタRLの新しいベンチマーク環境として有用なAlchemyと解析ツールを導入(オープンソース化)することで、メタ強化学習の「べンチマークタスクが不足している」という課題を解決することを目的としている。


人間は、新しいタスクに直面したとき、通常、ほとんど経験を必要とせず、驚くほどのスピードでそれに取り組むことができる。このような効率性と柔軟性は、人工エージェントにも求められている。しかし、最近では、大規模な訓練後に複雑なタスクを実行できる深層強化学習(RL)エージェントの構築に劇的な進歩が見られるが、RLエージェントが新しいタスクを迅速に習得できるようにするには、まだ未解決の問題がある。
有望なアプローチの一つとして、メタ・ラーニング(meta-learning)またはラーニング・トゥ・ラーニング(learning to learn)がある。この考え方は、学習者が多くの経験から再利用可能な知識を得て、その知識が蓄積されていくことで、学習者が新しいタスクに出会うたびに、より迅速に適応することができるようになるというものだ。深層RLの中でメタ学習のための方法を開発することへの関心が急速に高まっている。このような「メタ強化学習」に向けた研究はこれまでにも盛んに行われてきたが、ベンチマークタスクが不足していることが研究の足かせとなっていた。本研究では、メタRLの新しいベンチマーク環境として有用なAlchemyと解析ツールを導入(オープンソース化)することで、この問題を解決することを目的としている。
メタ学習を実現するためには、環境が学習者に単一のタスクを提示するのではなく、高レベルの特徴を持つ一連のタスクを提示する必要がある。このような相互に関連したタスク設定は現実世界では一般的だが(ボードゲームやキッチンのタスク、地下鉄のシステムなどを考えてみてください)、シミュレートされた環境で動作する人工エージェントのために設計するのは難しいことで知られている。理想的には、面白くてアクセスしやすいタスク分布が欲しいと考えている。現実世界のタスクに見られるような豊富な種類の共有構造が含まれているという意味で興味深いものであり、タスク分布全体について完全な知識を持っているという意味でアクセス可能なものであり、優れたメタ学習者が拾い上げるような共有構造とは何かを正確に述べることができる。これまでのメタRLの研究では、一般的に、面白くなくてもアクセス可能なタスク(盗賊タスクのような)、またはアクセスできなくても面白いタスク(アタリゲームのような)の分布に依存してきた。Alchemyはその両方の世界のベストを提供するように設計されている。
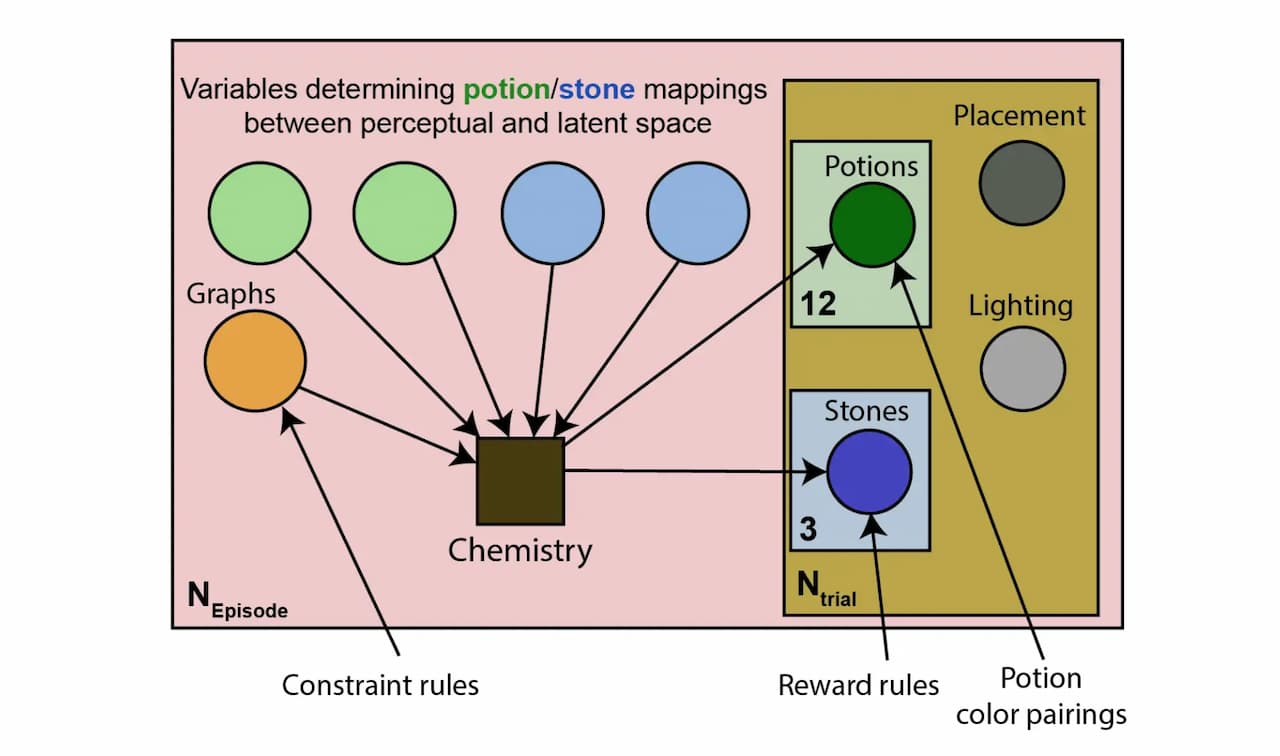
Alchemyは、Unityで実装されたシングルプレイヤーのビデオゲームだ。プレイヤーは、色のついた石のセット、色のついた薬を入れた皿のセット、中央の大釜などのオブジェクトが置かれたテーブルを一人称視点で見ることになる。石にはそれぞれポイントがあり、大釜に石を入れるとポイントが溜まる。ポーションに石を入れることで、プレイヤーは石の見た目を変化させることができ、その結果、獲得できるポイント数を増やすことができる。
しかし、Alchemyには非常に重要な要素も含まれている。それは、ポーションがどのように石に影響を与えるかを支配する「化学」が、ゲームをプレイするたびに変化するということだ。熟練したプレイヤーは、現在の化学がどのように機能するかを知るために、ターゲットを絞った一連の実験を行い、その結果を戦略的なアクションシーケンスのガイドとして使用しなければならない。Alchemyの多くのラウンドを経て、それを習得することはまさにメタRLの課題と言えるだろう。
Alchemyは、潜在的な因果関係を構成するという意味で「興味深い」構造を持っており、戦略的な実験とアクションのシーケンスを必要とする。しかし、ゲームレベルは明示的な生成プロセスに基づいて作成されるため、Alchemyの構造は「アクセスしやすい」ものでもある。
研究者らは、2つの強力な深層RLエージェント(IMPALAとV-MPO)を用いてAlchemy環境を評価した。これらのエージェントはシングルタスクのRL環境で印象的な性能を達成しているが、Alchemy環境では大規模なトレーニングを行ってもメタ学習性能が非常に劣っていた。研究チームによると、この結果はメタ学習に関与する構造学習と遅延状態推論の失敗を反映しており、AlchemyをメタRL研究の有用なベンチマークタスクとして検証しているという。
論文「Alchemy: A Structured Task Distribution for Meta-Reinforcement Learning」はarXivに掲載されている。コードやその他のリソースはオープンソース化されており、プロジェクトGitHubで公開されている。この研究はDeepMindとユニバーシティ・カレッジ・ロンドン(UCL)によって行われた。



