高精度のディープフェイク識別器を開発: スタンフォード大学とカリフォルニア大学バークレー校
スタンフォード大学教授のManeesh Agrawalaらのグループは、リップシンク技術を利用したディープフェイクの検出ツールを開発。基本的な考え方は、「口の形」と「音素」の間に矛盾がないかどうかを調べることだ。


1年前、スタンフォード大学教授(コンピュータ科学)のManeesh Agrawalaは、ビデオ編集者が話し手の言葉をほとんど気づかれずに修正できるリップシンク(口唇同期)技術の開発に協力した。このツールは、人が言ったことのない単語をシームレスに挿入したり、文の途中でも発言した単語を削除したりすることができる。肉眼では、そして多くのコンピュータベースのシステムでさえ、何も問題がないように見える。
Agrawalaらは、音声・映像の流れをシームレス(ジャンプカットなし)に保ちつつ、話者の対話内容を変更したリアルな出力映像を生成するために、音声・映像のトランスクリプトに基づいて話頭映像を編集する新しい手法を提案した。
このツールのおかげで、シーン全体を撮り直すことなく不具合を修正したり、テレビ番組や映画をさまざまな場所でさまざまな観客に合わせて調整したりすることがはるかに簡単になった。その手法は、入力されたトーキングヘッドビデオに、フレームごとに、音素、ビセーム(特定の音を説明するために使用できる一般的な顔のイメージ)、3D顔のポーズとジオメトリ、反射率、表情、シーン照明などのアノテーションを自動的に付与することだった。
「ビデオを編集するためには、ユーザはトランスクリプトを編集するだけでよくなった。最適化戦略が入力コーパスのセグメントをベース素材として選択し、選択したセグメントに対応するアノテーションされたパラメータはシームレスにつなぎ合わされ、顔の下半分がパラメトリックな顔モデルでレンダリングされる中間的なビデオ表現を生成するために使用される」と論文は説明している。
しかし、この技術は、期せずして、より精巧なディープフェイク動画の心配の種を生み出した。 例えば、最近、共和党下院議員スティーブ・スカリスがソーシャルメディアで共有したビデオでは、ジョー・バイデン副大統領とのインタビューに捏造を加えるもっとひどいテクニックを使っていた。
これらの悪用を防ぐため、Agrawalaを含むスタンフォード大学とカリフォルニア大学バークレー校の研究者はこのたび、リップシンク技術を検出するためのAIベースのアプローチを発表した。この新しいプログラムは、人が発する音と口の形の間の微細なミスマッチを認識することで、80パーセント以上の偽物を正確に見分けることができる。
ディープフェイクの仕組み
ビデオの内容の操作には正当なものもある。例えば、架空のテレビ番組や映画、CMなどを制作している人なら誰でも、デジタルツールを使ってミスを修正したり、台本を微調整したりすることで、時間とコストを節約することができる。しかし問題は、これらのツールが意図的に誤った情報を広めるために使用された場合だ。そして、そのテクニックの多くは、一般の視聴者には見えないものだ。
多くのディープフェイクビデオは、文字通り、他人のビデオに一人の人物の顔をスーパーインポーズ(画像の重ね合わせ)する「フェイススワッピング」に頼っている。しかし、顔の入れ替えツールは説得力があるが、比較的粗雑なもので、通常はコンピュータが検出できるような痕跡を残す。
一方、リップシンク技術は、より微妙なので、見破るのが難しい。この技術では、画像のはるかに小さな部分を操作して、特定の言葉を言ったときに実際に口が動いたであろう人の口の動きと密接に一致する唇の動きを合成する。Agrawalaによると、人物のイメージと声のサンプルが十分にあれば、ディープフェイクのプロデューサーは、人物に何でも「言わせる」ことができるという。
偽物を見分ける
このような技術の非倫理的な使用を心配して、Agrawalaはスタンフォード大学の博士研究員Ohad Fried、カリフォルニア大学バークレー校情報学部の教授Hany Farid、バークレー校の博士課程の学生Shruti Agarwalと共同で検出ツールを開発した。
基本的な考え方は、「口の形」と「音素」の間に矛盾がないかどうかを調べることだ。具体的には、「B」、「M」、「P」の音を出すときの人の口の形を見てみた。研究者は最初、人間の観察者がビデオのフレームを研究した純粋に手動の技術で実験した。それはうまくいったが、労働集約的で時間のかかるものだったという。
具体的には、音声の音素が発話されている間の映像を分析するためにまず、音素の位置を抽出した。Google の Speech-to-Text APIを使用して、動画に関連付けられた音声トラックを自動的に転写。転記は手動でチェックしてエラーを取り除き、音声に整列します。この整列により、入力オーディオ/ビデオの開始時刻と終了時刻を含む一連の音素が生成される。
また「口の形」の測定では、与えられたシーケンスに対して、音素発生の開始付近の6つのビデオフレームから関連する口の形が検索される。小さな音素の整列の誤差を調整するために、複数のフレームを考慮。音素が発生する前に口を閉じる必要があるため、発生開始付近のフレームのみを解析する。
研究者たちは、バラク・オバマ前大統領のビデオ上で訓練した後、同じ分析を行うために、はるかに高速であろうAIベースのニューラルネットワークをテストした。ニューラルネットワークは、オバマ自身が関与するリップシンクの90%以上を検出したが、他の話者のリップシンクを検出する際の精度は約81%にまで低下した。
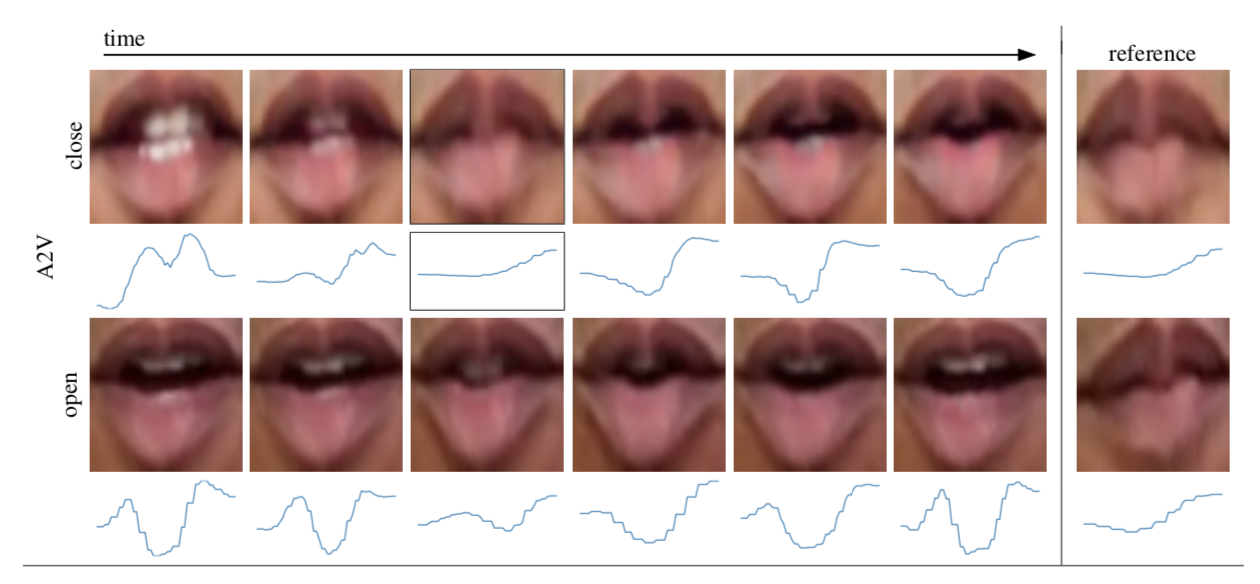
「モデルは、バラク・オバマの動画のみで学習したものだが、人物に特化しており、オバマの動画の方がはるかに良い結果が得られる傾向があった。大規模な人物のコーパスで学習されたネットワークを使えば、より良い結果が得られると期待している」と研究チームは記述している。
「このような制限があるにもかかわらず、我々の手法は、最新の口唇連動型のディープフェイクをすでに検出することができる。今後の合成技術では、音素と語素のマッチングをより慎重に考慮しながら、猫とネズミのゲームを続けていくことを期待している。私たちは、音素のミスマッチを利用したディープフェイクの検出を、フォレンジックエキスパートのツールキットの中のもう一つのツールと考えており、他の補完的な技術と一緒に開発して使用することを考えている」。
スタンフォードのブラウン・メディア・イノベーション研究所の所長であり、スタンフォード人間中心人工知能研究所(HAI)の教授でもあるAgrawalaは「動画を操作する技術が進歩するにつれ、操作を検出する技術の能力はますます低下していく。私たちは、誤情報を特定して減らすための非技術的な方法に焦点を当てる必要がある」とHAIのブログ記事の中で語った。「長い目で見ると、本当の課題は、ディープフェイク動画との戦いというよりも、偽情報との戦いである。実際、ほとんどの誤報は、人々が実際に言ったことの意味を歪めてしまうことから生じている」。
参考文献
- Maneesh Agrawala et al. Text-based Editing of Talking-head Video. ACM Transactions on Graphics. July 2019.
- Maneesh Agrawala et al. Detecting Deep-Fake Videos from Phoneme-Viseme Mismatches. Published in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 14-19 June 2020.
Eyecatch Photo by UC Berkley / Youtube via https://youtu.be/51uHNgmnLWI



