Googleは第4世代TPUが前世代より2.7倍速いと主張
MLPerfが発表した最新のメトリクスのセットによると、物体検出、画像分類、自然言語処理、機械翻訳、レコメンデーションのベンチマークにおいて、第4世代TPUのクラスタが第3世代TPU、さらには最近リリースされたNvidiaのA100の能力を上回っていることが示されている。


今日までその存在が公表されていなかったグーグルの第4世代のテンソルプロセッシングユニット(TPU)は、記録的な時間でAIや機械学習のトレーニングワークロードを完了させることができる。これは、70社以上の企業と学術機関からなるコンソーシアムであるMLPerfが発表した最新のメトリクスのセットによると、物体検出、画像分類、自然言語処理、機械翻訳、レコメンデーションのベンチマークにおいて、第4世代TPUのクラスタが第3世代TPU、さらには最近リリースされたNvidiaのA100の能力を上回っていることが示されている。
Googleによると、第4世代のTPUは、第3世代のTPUの2倍以上の行列乗算TFLOPsを提供しており、1つのTFLOPは1秒間に1兆回の浮動小数点演算に相当する。また、相互接続技術の不特定多数の進歩の恩恵を受けながら、メモリ帯域幅を「大幅に」向上させている。Googleによると、全体としては、64チップの同じ規模で、ソフトウェアに起因する改善を考慮していない場合、第4世代TPUは、昨年のMLPerfベンチマークにおいて、第3世代TPUの性能の平均2.7倍の改善を示しているという。
GoogleのTPUは、AIを高速化するために開発された特定用途向け集積回路(ASIC)。これらは水冷式で、サーバーラックにスロットインするように設計されており、最大100ペタフロップスの計算を実現し、Google検索、Google写真、Google翻訳、Googleアシスタント、Gmail、GoogleクラウドAI APIなどのGoogle製品に電力を供給する。Googleは毎年恒例のI/O開発者カンファレンスで2018年に第3世代を発表していた。
「これは、機械学習の研究とエンジニアリングを大規模に進め、オープンソースのソフトウェア、Google の製品、Google Cloud を通じて、それらの進歩をユーザーに提供するという当社のコミットメントを示しています」と、Google AI ソフトウェアエンジニアのNaveen Kumarはブログの投稿で書いている。「機械学習モデルの高速なトレーニングは、これまで手の届かなかった新製品、サービス、研究のブレークスルーを提供する研究・エンジニアリングチームにとって非常に重要だ」。
今年のMLPerfの結果は、Googleの第4世代 TPUの優秀な性能を示している。ImageNetデータセットを用いてアルゴリズム(ResNet-50 v1.5)を75.90%以上の精度でトレーニングした画像分類タスクでは、256台の第4世代TPUが1.82分で終了した。これは、768枚のNvidia A100グラフィックスカードと192枚のAMD Epyc 7742 CPUコアの組み合わせ(1.06分)や、512枚のHuaweiのAI最適化されたAscend910チップと128枚のIntel Xeon Platinum 8168コアの組み合わせ(1.56分)とほぼ同じ速さだ。第3世代のTPUは0.48分のトレーニングで第4世代のビートを持っていたが、第3世代のTPUが4096個もタンデムで使用されていたためか、第3世代のTPUは第4世代のビートを持っていた。
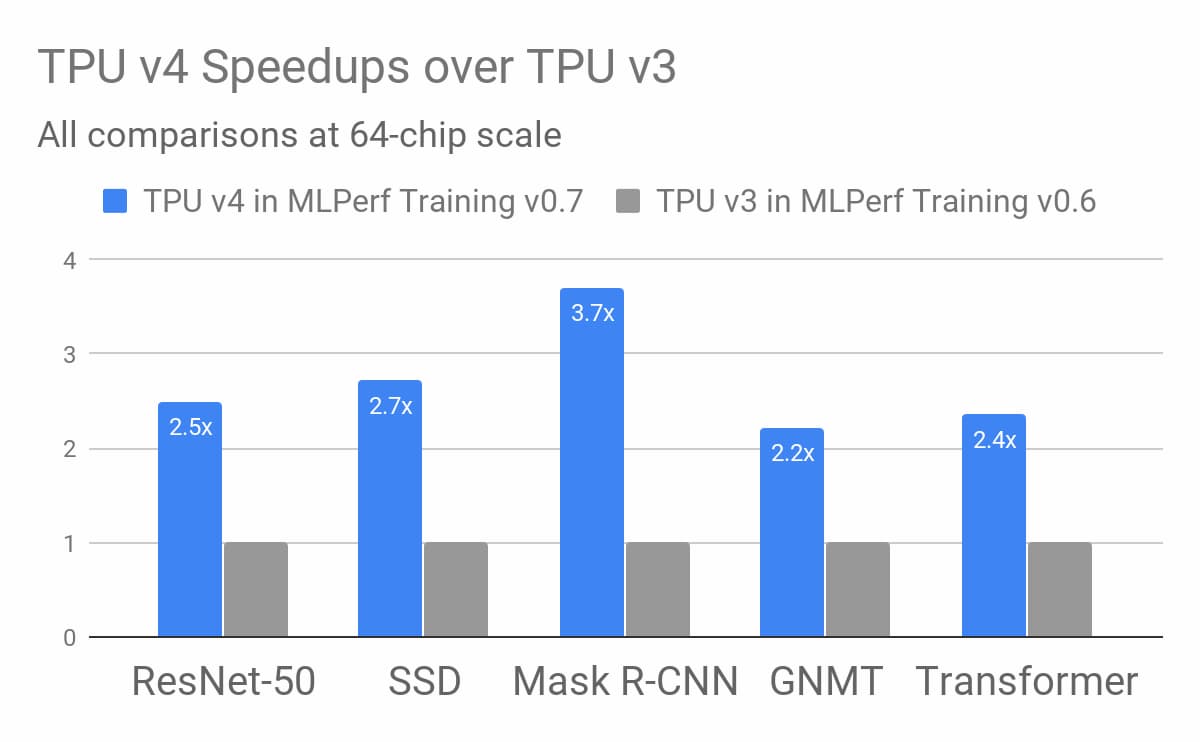
MLPerfの「重量級」の物体検出カテゴリでは,第4世代TPUがわずかにリードした.第4世代TPU256台でCOCOコーパスを用いて学習した参照モデル(Mask R-CNN)は、第3世代TPU512台(8.13分)と僅差の9.95分で学習した。また、WMT英独データセット上でTransformerモデルを学習することを含む自然言語処理作業負荷では、第4世代TPU256台で0.78分で終了した。第3世代TPUは4096台で0.35分、Nvidia A100カード480枚(+AMD Epyc 7742 CPUコア256枚)で0.62分だった。
第4世代TPUは、大規模なWikipediaコーパス上でBERTモデルを訓練するというタスクでも高いスコアを示した。第4世代TPU256台での訓練時間は1.82分で、第3世代TPU4,096台での訓練時間0.39分よりもわずかに遅くなっただけである。一方、Nvidiaハードウェアで0.81分のトレーニング時間を達成するには、2,048枚のA100カードと512枚のAMD Epyc 7742 CPUコアが必要だった。
この最新のMLPerfには、新しいベンチマークと修正されたベンチマークであるレコメンデーションと強化学習が含まれており、TPUの結果は混合していた。第4世代の64個のTPUのクラスタは勧告タスクで良好なパフォーマンスを示し、Criteo AI LabのテラバイトのCTR(Click-Through-Rate)データセットから得た1TBのログに対してモデルを訓練するのに1.12分かかった(Nvidia A100カード8枚)。8枚のNvidia A100カードと2枚のAMD Epyc 7742 CPUコアは3.33分でトレーニングを終了した。しかし、強化学習では、256枚のA100カードと64枚のAMD Epyc 7742 CPUコアを使用して、ボードゲーム「囲碁」の簡易版で勝率50%のモデルを29.7分でトレーニングすることに成功した。256枚の第4世代TPUで150.95分かかった。
注意すべき点としては、Nvidiaのハードウェアは、GoogleのTensorFlowではなく、FacebookのPyTorchフレームワークとNvidia独自のフレームワークでベンチマークが行われたことだ。このことが結果に多少の影響を与えたかもしれないが、その可能性を考慮しても、ベンチマークは第4世代TPUのパフォーマンスの強さを明確にしている。
Image via Google AI



