Google、深層学習を利用してより高速で小型のAIチップを設計
GooglerとUCバークリーの研究者が、高速で小型のチップを設計するために人工知能(AI)を使用する方法を考案した。既存の設計図と性能の数値からチップのアーキテクチャを生成する「PRIME」と呼ばれる手法だ。

GooglerとUCバークリーの研究者が、高速で小型のチップを設計するために人工知能(AI)を使用する方法を考案した。
17日に共有されたブログの中で、研究者たちは、既存の設計図と性能の数値からAIチップのアーキテクチャを生成する「PRIME」と呼ばれるディープラーニングのアプローチを開発したと述べている。彼らは、このアプローチによって、Googleの生産中のEdgeTPUアクセラレータや従来のツールを使って作られた他のデザインよりも、レイテンシーが低く、より少ないスペースを必要とするデザインを生み出すことができると主張している。
Googleはこの分野にかなり関心を持っている。昨年、同社はTPU設計の1つのレイアウトを最適化するために機械学習を利用したと発表している。
この最新の知見は、Googleのカスタムチップ設計の取り組みにとって画期的なものとなる可能性があり最新の論文で詳述されている。この論文は、今年の深層学習における世界トップレベルの国際学会ICLRに採択されている。
研究者によると、従来のシミュレーションベースのチップ設計は時間と計算コストがかかるため、より高速で効率的な設計を可能にするという点以外でも、PRIMEのアプローチは重要だという。また、シミュレーションソフトを使ったチップの設計は、低消費電力や低遅延など特定のものに最適化しようとすると、「実現不可能な」設計図になる可能性があるという。
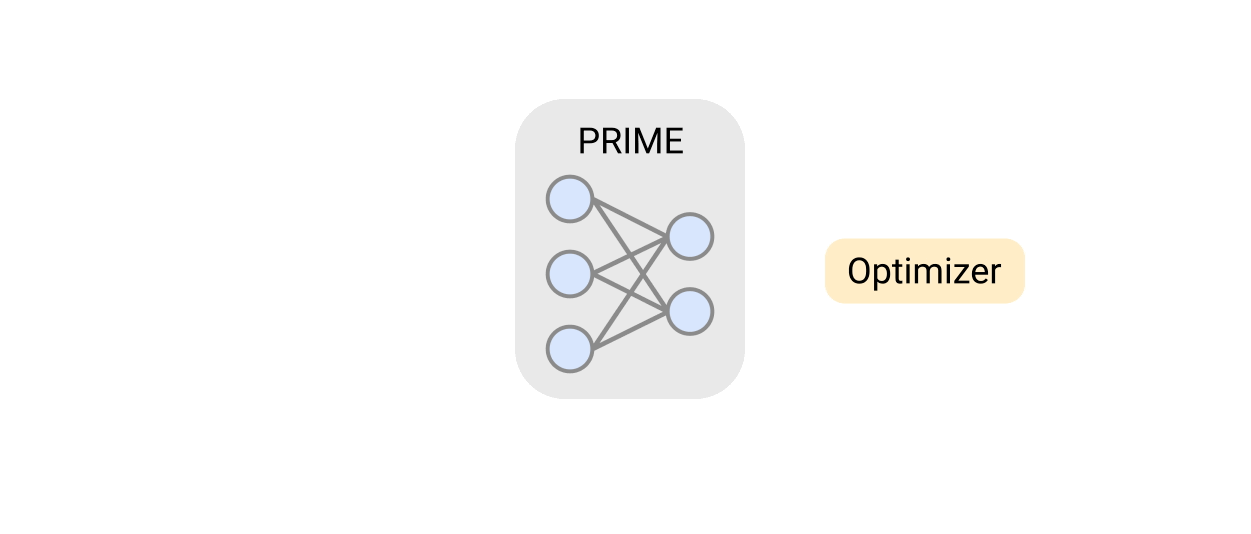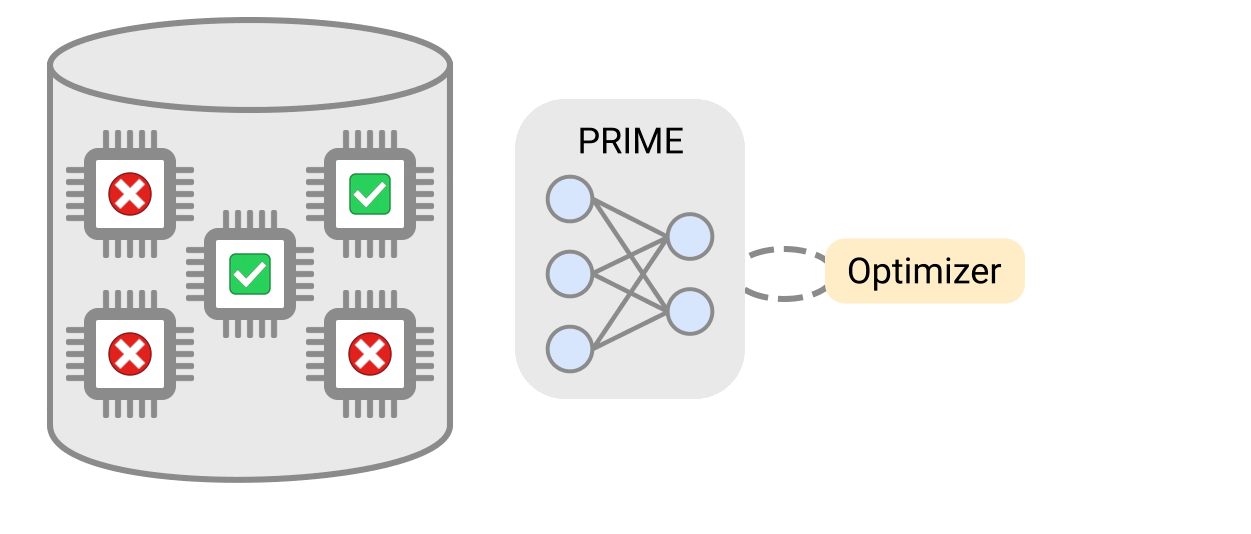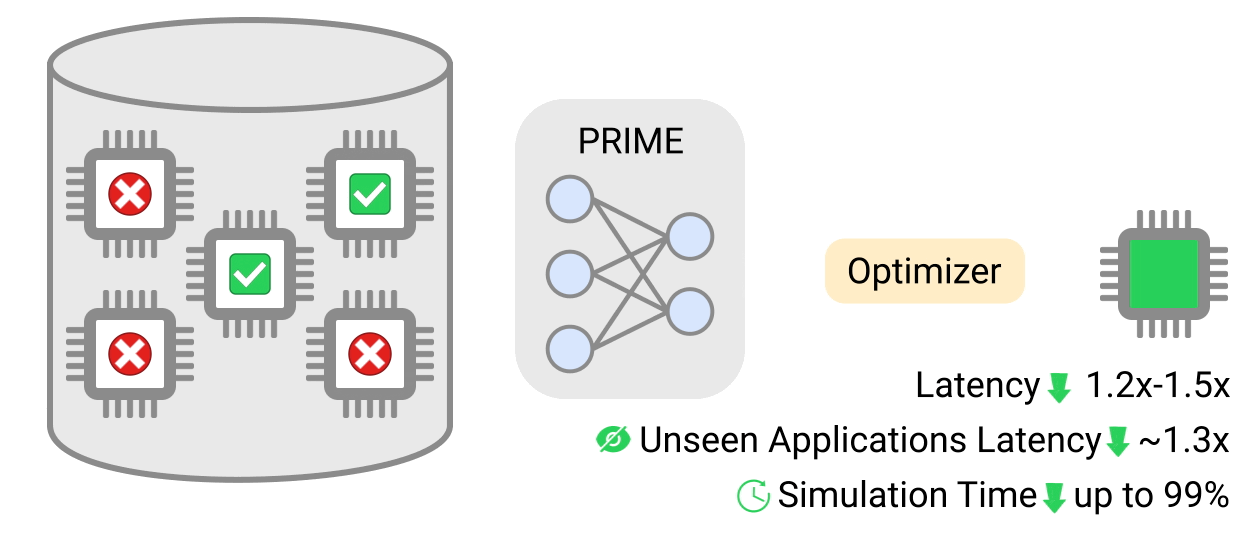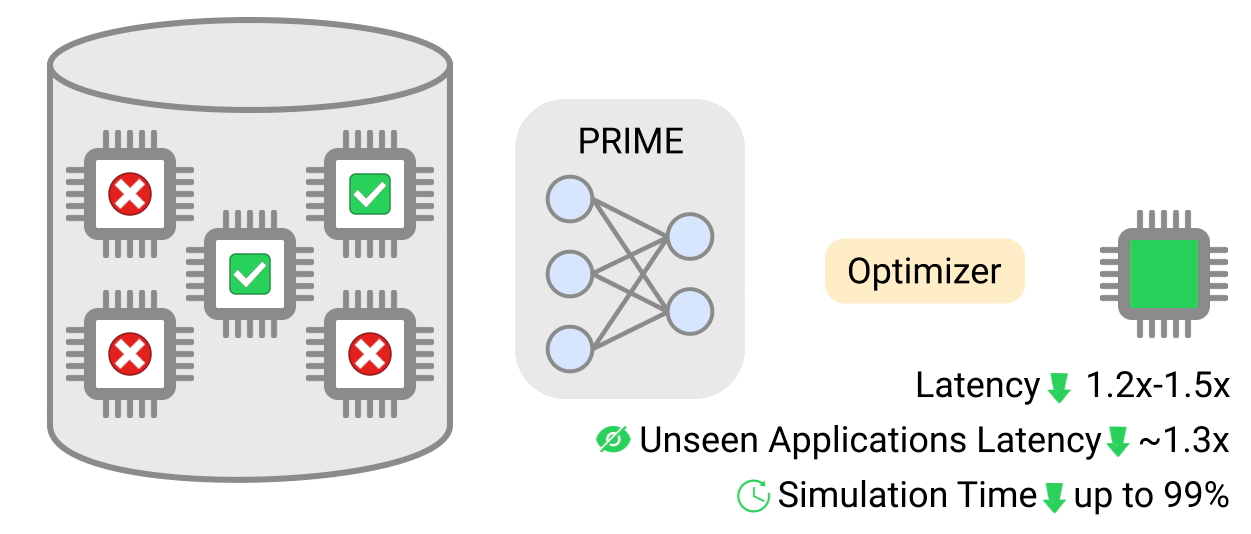
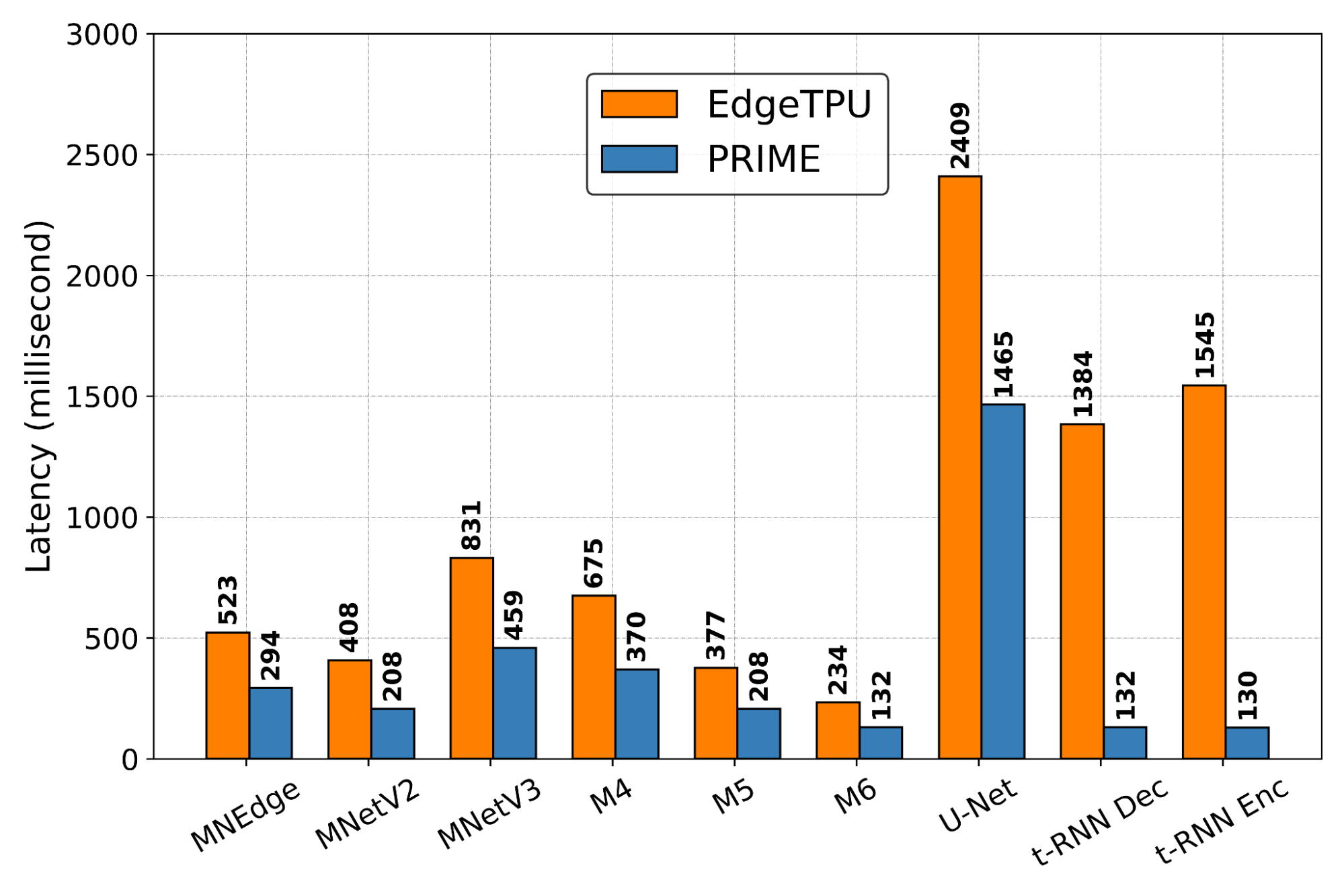
研究チームによると、PRIME方式で作成したチップの設計は、シミュレーション主導の手法で作成したチップに比べてレイテンシーが最大50%少なく、また、深層学習アプローチにより、当該設計図の生成にかかる時間も最大99%短縮されたという。
研究者らは、画像分類モデルMobileNetV2およびMobileNetEdgeを含む9つのAIアプリケーションにおいて、PRIMEで生成したチップ設計とシミュレーションで生成したEdgeTPUを比較した。重要なのは、PRIMEの設計が各アプリケーションに最適化されていることだ。
その結果、PRIMEチップの設計は全体としてレイテンシーを2.7倍改善し、ダイ面積を1.5倍削減することがわかったという。この最後の部分は、チップをより安くし、消費電力を下げることができるダイサイズを減らすためにPRIMEを訓練しなかったので、技術者たちに衝撃を与えた。ある種のモデルでは、レイテンシとダイ面積はさらに大きく改善された。

さらに研究者たちは、PRIMEを使って、複数のアプリケーションでうまく機能するように最適化したチップを設計した。その結果、PRIMEの設計は、シミュレーション主導の設計よりもやはりレイテンシが小さくなることがわかった。さらに驚くべきことに、学習データがないアプリケーションでPRIME設計を実行した場合でも、この結果は同じだった。さらに、アプリケーションの数が増えれば増えるほど、性能は向上した。
最後に、研究者たちはPRIMEを使って、前述の9つのアプリケーションで最高のパフォーマンスを発揮できるチップを設計した。PRIME設計がシミュレーション主導の設計よりもレイテンシーが高かったアプリケーションは3つしかなく、研究者はこれが、PRIMEがより大きなオンチップメモリと、その結果としてより少ない処理能力を持つ設計を好むためであることを突き止めた。
PRIMEが実際にどのように機能するかを掘り下げると、研究者は、ロバスト予測モデルと呼ばれるものを作成した。これは、AIチップの設計図のオフラインデータを与えられ、うまくいかないものも含めて、最適なチップ設計を生成する方法を学習するモデルだ。教師あり機械学習の利用に伴う典型的な落とし穴を避けるため、研究者たちは、いわゆる敵対的な事例に惑わされないようにPRIMEを考案したという。
研究者らは、このアプローチにより、ターゲットとするアプリケーションに最適化するモデルが可能になったと述べている。PRIMEは、学習データがないアプリケーションに対しても最適化することができる。これは、データがあるアプリケーション全体の設計データに対して、単一の大規模モデルを学習させることで実現される。
これによってGoogleのチップエンジニアリングのやり方が一夜にして変わることはないだろうが、研究者たちは、複数の道筋に期待できると述べている。たとえば、複雑な最適化問題を解く必要があるアプリケーション用のチップを作成したり、低性能のチップ設計図をトレーニングデータとして使用してハードウェア設計を開始するのに役立てたりすることだ。
また、PRIMEの汎用性を活かして、ハードウェアとソフトウェアの協調設計にも活用したいとしている。



