ムーアの法則は死んでいない? インテルは30年存続すると主張
ムーアの法則が死んだ、とコンピュータ業界の多くの専門家が主張していますが、IntelやTSMCはそれが遅延しているだけで、今後も法則は長期的に継続する、と主張しています。


ゴードン・ムーアの1965年の予測では、集積回路上のコンポーネントの数は、1975年までに65,000に達するまで毎年2倍になると予測されていま した。1975年に正しいことが判明したとき、彼はムーアの法則として知られるようになったものを「2年ごとにチップ上のトランジスタが2倍になる」に修正しました。
それ以来、彼の予測は技術の軌跡、そして多くの点で進歩そのものを定義してきました。
ムーアの議論は経済的なものでした。数年前にフェアチャイルドセミコンダクターのロバート・ノイスが発明したのは、小さな正方形のシリコンウェーハ上のアルミニウム金属線で相互接続された複数のトランジスタやその他の電子デバイスを備えた集積回路です。同社のR&Dディレクターだったムーアは、1965年に書いたように、これらの新しい集積回路では、「コンポーネントあたりのコストはコンポーネントの数にほぼ反比例する」ことに気付きました。理論上、追加したトランジスタが多いほど、それぞれのトランジスタが安くなります。ムーアはまた、手頃な価格で信頼性の高い方法でチップに搭載できるトランジスタの数を増やすために、技術の進歩の余地が十分にあることも知りました。
それ以来、彼の予測は技術の軌跡、そして多くの点で進歩そのものを定義してきました。
すぐにこれらの安価で強力なチップは、経済学者が汎用技術と呼ぶものになります。これは非常に基本的なものであり、他のあらゆる種類の革新や進歩を複数の産業で生み出します。また、機械学習技術が膨大な量のデータを噛み合わせて答えを見つける能力を支援することにより、人工知能における今日のブレークスルーを促進しました。
しかし、トランジスタの数に基づいた単純な予測は、なぜ長期に渡り維持されたのでしょうか。おそらく「予言の自己実現」が好ましい表現でしょう。ムーアは、1965年の「集積回路にさらに多くのコンポーネントを詰め込む」というタイトルの文書で、「ホームコンピューター、または少なくとも中央コンピューターに接続された端末」が、自動車や個人の携帯通信機器の自動制御などの驚異につながる、と記述しましました。その後の数十年間、活況を呈する産業、政府、学術研究者および産業研究者の軍隊が、ムーアの法則の支持にお金と時間を注ぎ込み、不思議な精度で進歩を続けた自己実現的な預言を生み出したのです。近年進歩のペースは落ちていますが、今日の最先端のチップには500億個近くのトランジスタがあります。
1970年代から2000年代初頭にかけて、トランジスタのクロック速度がそれぞれ1メガヘルツから爆発的に増加しました。ただし、2000年代以降、トランジスタのクロック速度の改善ではなく、シリコンアーキテクチャの革新とコンピューティングワークロードのスレッド化または並列化の両方によって、コンピューティングパフォーマンスが大幅に向上しました。CPUとGPUを開発した企業は、このソフトウェアの並列化に、アーキテクチャの革新をさらに進め、コンピューティングコアを追加することで対応しました。 計算コアが多いほど、チップが処理できるスレッドが多くなり、全体的なパフォーマンスが向上します。
個々のトランジスタのクロック速度のために計算パフォーマンスは向上していませんが、計算の問題により多くのトランジスタを投入することで計算パフォーマンスが向上しています。同じエリアでより多くのトランジスタを絞る尺度は「密度」です。 密度とは、特定の2次元領域内のトランジスタの数のことです。チップコストはチップ面積に正比例します。1965年のムーアの論文は、コンポーネントあたりの製造コストとチップ上のトランジスタの総数の間に関係があることを明らかにしたのです。
ロバート・デナードの1974年の論文に基づくデナードスケーリング(デナード則)により、それゆえ全ての技術世代でトランジスタ密度は2倍になり、回路は40%速くなり、消費電力(トランジスタ数は2倍)は変わらず、ということが明示化されました。この法則が、コンポーネント密度の改善が、計算機に性能改善もたらす魔法を裏側で支えていたのです。しかし、デナード則は2006年頃に終焉を迎えており、CPUの性能改善の継続性に一定の疑問を付与しました。ムーアの法則とデナードスケーリングの乖離は、ダークシリコン問題を生み出しています。発熱を考慮すると、一定の消費電力を超えるチップは作れないため、稼働率を上げられない回路(ダークシリコン)が増加します。
このダークシリコンを活かすには、コア数を増やし、各コア動作クロック数を低くして消費電力を抑えたり、専用回路(ドメイン固有アーキテクチャ)として利用することで、稼働率を低く抑えるが、求められる計算において高い価値を表現するチップ領域を増やすことが必要とされています。
現在、ムーアの法則が終わった、という主張は多数派を形成しつつあるかもしれません。
RISCの共同発明者である元カルフォルニア大学バークリー校元教授で、Google Distiguished Engineerのデイビッド・パターソンは、ムーアの法則が終わった、と主張しています。
パターソンは、現在、ムーアの法則の終了により、PCの性能改善は著しく鈍化している、と説明しています。2018年、パーソナルコンピューターの性能は3パーセントの向上に留まり、20年ごとに速度が2倍になるペースに陥っています。それは、コンピューターの性能改善に伴いプログラムが速くなる古き良き時代に慣れたプログラマーにとって大きな影響を与えています。コンピューターが18か月ごとにパフォーマンスを2倍にするため、プログラマーはさらに多くの機能を追加できたのですから。
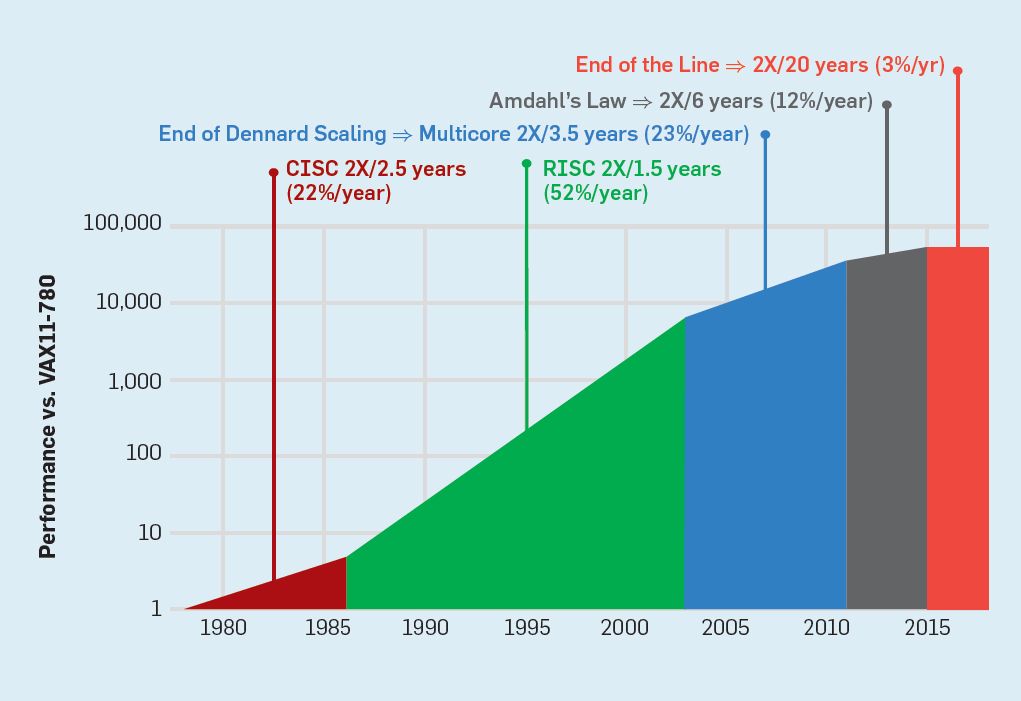
パターソンは、ムーアの法則以降の時代にはドメイン固有アーキテクチャ(DSP)が重要なフロンティアになる、と説いています。DSPを必要するもののかで現在非常に人気のある分野は機械学習です。雨後の筍のように現れたスタートアップ企業はすべて機械学習のためのドメイン固有のアクセラレーターを構築しており、彼らは何をするかを絞り込むことによって10倍以上の改善の要因を探しています。
パターソンとMIPS Computer Sytem創業者で、現在はGoogleの親会社Alphabetの会長ジョン・ヘネシーは、現在がコンピューターアーキテクチャの黄金期だ、と指摘しています。彼らのコンピューターサイエンスの教科書である『コンピューターアーキテクチャ定量的アプローチ』の最新版にはドメイン固有アーキテクチャの章が付け加えられました。パターソンはGoogleの機械学習向けDSAのチップ、テンサー・プロセッシング・ユニット(Tensor processing unit、TPU)開発チームに名を連ねています。
もうひとり、有名なムーアの法則の死の預言者がいます。それは、大手半導体メーカーNvidiaのCEO、ジェンスン・ファンです。彼は何度となく「ムーアの法則の終わり」を宣言し、「グラフィックスプロセッサは、ムーアの法則よりも優れた開発経路を通っている」と主張しています。もちろん、彼がGPUという区分を自ら設定し、その商業的成功を自己実現させた優れた経営者であることは、忘れてはいけません。彼に言わせると、GPUの性能改善のカーブには、CPUに見られるような異常は存在せず、CPUから多彩な固有アーキテクチャへと多様性の爆発が起きるコンピュータアーキテクチャのカンブリアを、業界は迎えている、ということになります。
Microsoft Research NExTのDistinguished Engineer のDoug Burgerは、ムーアの法則が「減速」している、と発言しています。「私たちはただ遅い新しいリズムに乗っているのかもしれませんし、新しい世代の半導体技術の間の時間が長くなっているかもしれません。問題は本当に、私たちは原子の限界に立ち向かっているということです」。現在、半導体は非常に複雑な3次元構造を採用しており、このサイズを縮小することでコンポーネントの密度を高めようとすると、ますます複雑になります。チップ設計者と製造者は、常に新しい手法を発見してきましたが、それはますます困難になりつつあるのです。Burgerは物理的な制約だけでなく、100億個を搭載したチップを「経済的」に構築できるか、という経済的な制約も指摘しています。極端紫外線リソグラフィ(EUV)を採用した製造過程において、どのようにして高い歩留まり率を維持するかは、今後、さらに微細化が進む中で、ファウンドリが直面する大きな課題なのです。
死んではいないが遅延している
実際のところは、それは突然の死というよりも徐々に遅延しています。何十年もの間、ムーア自身を含む一部の人々は、ますます小さなトランジスタを作ることが難しくなったため、法則に終わりが見えてくるのではないかと不安になりました。1999年、Intelの研究者は、2005年までにトランジスタを100ナノメートルよりも小さくするという業界の目標には根本的な物理的問題が存在するのではないかと心配しました。
最先端のチップを製造するファウンドリが負担する費用は非常に高価になっています。ファブのコストは年間約13%で上昇しており、2022年までに160億ドル以上に達すると予想されています。偶然ではありませんが、次世代チップの製造を計画している企業の数は今では3社に減少しています。 2010年の8社と2002年の25社から減少に歯止めがかからないのです。
しかし、Intelが抱いた懸念は杞憂に終わり、いまや5ナノメートルプロセスへの挑戦が始まろうとしています。世界最大のファンドリであるTSMC(台湾セミコンダクター・マニュファクチャリング)の5ナノメートルプロセスである「N5」は、2020年前半に投入される予定です。N5は、iPhone X プロセッサーA13 Bionicを製造するために使用される同社の7ナノメートルプロセスと比較して、15%高速または30%電力効率の高いデバイスにつながる、とTSMCは説明しています。
また、他にも性能改善の手法はある、とTSMCは説明しています。最新の高速CPU、GPU、専用AIプロセッサにデータを供給するには、処理するコアのデータの帯域幅を広くすることに加えて、レイテンシを改善するためにデータを要求しているコアに物理的に近いメモリを提供することが重要です。これは、デバイスレベルの密度が提供するものです。メモリがロジックコアの近くに配置されると、システムは低レイテンシ、低消費電力、および全体的なパフォーマンスを実現する、とTSMCは説明しています。
Intel「30-40年維持可能」
また、ムーアの法則の「本家」であるIntelは、ムーアの法則は継続する、という姿勢を2019年から外部に発信し始めました。2018年にIntelのシリコンエンジニアリングヘッドを引き継いだジム・ケラーは、それを生かし続けることに集中しています。彼は現在、Intelで約8,000人のハードウェアエンジニアとチップ設計者のチームを率いています。
彼が会社に入社したとき、多くの人がムーアの法則の終わりを予想していたと言いますが、ケラーは進歩のための十分な技術的機会を見出しました。彼は、ムーアの法則を維持するためには、おそらく100を超える変数があり、それぞれが異なる利点を提供し、独自の限界に直面している、と指摘します。 チップ上のデバイス数を倍増し続けるには、3Dアーキテクチャや新しいトランジスタ設計、さらなるマルチコア化などの方法が数多くあることを意味します。
シリコン産業のベテランであるケラーは、AppleとTeslaの半導体事業を育成するために貢献してきました。AMDが現在、IntelのPC向けチップ市場を侵食していますが、その原動力となるZenアーキテクチャは、彼が管轄するチームの元で、生まれました。Intelは長い間享受したCPU市場の独占を、長年負け犬だったAMDに解除されており、GPUという新しい市場はNvidiaの先行を許しています。また、俗に言うAIチップの領域では、Google、Microsoft等のこれまで相手にしていなかった大手企業との競争が始まっただけでなく、ベンチャーキャピタルの支援を受ける、いくつかの新興企業の台頭を目の当たりにしています。
それでも、Intelや他の残りのチップメーカーがさらに数世代のさらに高度なマイクロチップを絞り出すことができたとしても、数年ごとに高速で安価なチップを確実に信頼できる時代は終わりました。 ただし、それは計算の進歩の終わりを意味するものではありません。
参考文献
Gordon E. Moore. Cramming more components onto integrated circuits. 1965.
Karin Strauss. The end of Moore’s law? Oh, not again… Microsoft Research Blog. Sep, 2015.
Samuel K. Moore. TSMC’s 5-Nanometer Process on Track for First Half of 2020. 13 Dec 2019. IEEE Spectrum.
David Patterson. UC Berkeley’s David A. Patterson Sees the Future After Moore’s Law.
Jim Keller. Moore’s Law is Not Dead. Berkeley EECS.
Photo by Intel Newsroom.



