「安くて簡単なディープフェイク」の登場
セキュリティ会社のデータサイエンティスト、フィリップ・タリーは、ハンクスの画像をオンラインで数百枚集め、オープンソースの顔生成ソフトウェアを選んだ被写体に合わせて調整するために100ドル弱の費用をかけるだけで、画像を作ることができた。調整したソフトウェアを使って、彼はハンクスの顔を作ることは容易だった。


先週のブラックハット・コンピュータ・セキュリティ・カンファレンスで、セキュリティ会社FireEyeのデータサイエンティストであるフィリップ・タリーは、人工知能研究所のオープンソースのソフトウェアがどれだけ簡単に誤報キャンペーンに適応できるかをテストするために、トム・ハンクスのディープフェイクを作成した。彼は「経験の少ない人でも、これらの機械学習モデルを使って、かなり強力なことができる」と主張した。
フル解像度で見ると、FireEyeの偽ハンクスの画像には、不自然な首のひだや肌の質感などの欠陥がある。しかし、眉毛のしわや、見る者を冷静に見つめる緑灰色の目など、俳優の顔のお馴染みのディテールは正確に再現されている。SNSのサムネイル程度の規模であれば、AIが作った画像は簡単に本物と見間違えるほどだ。
タリーは、ハンクスの画像をオンラインで数百枚集め、オープンソースの顔生成ソフトウェアを選んだ被写体に合わせて調整するために100ドル弱の費用をかけるだけで、画像を作ることができた。調整したソフトウェアを使って、彼はハンクスの顔を作ることは容易だった。
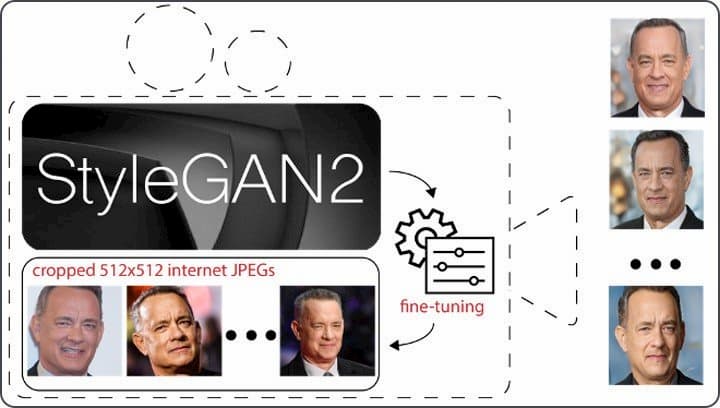
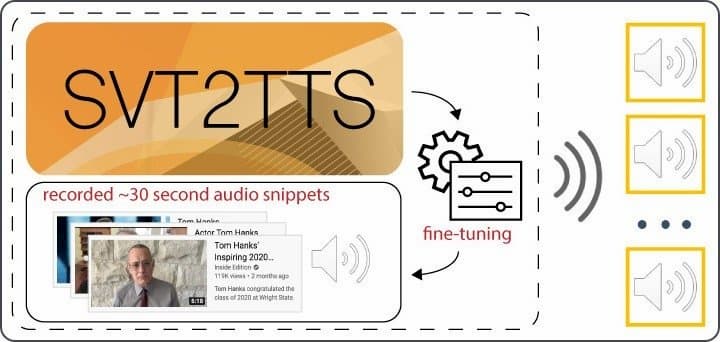
タリーは、他のオープンソースのAIソフトウェアを使用して、3つのYouTubeクリップから俳優の声を模倣することも試みたが、あまり印象的な結果は得られなかったという。
人がどれだけ安く簡単に通過可能な偽の写真を生成することができるか実証することによって、FireEyeプロジェクトは、オンラインの偽情報が通過可能な画像や音声を生成するAI 技術によって拡大される可能性があるという懸念に信憑性をもたせている。これらの技術とその出力は、しばしば「ディープフェイク」と呼ばれている。この呼び方は、2017年後半にハリウッド女優の顔を含むように変更されたポルノ動画を投稿したRedditアカウントの名前から取られた。
インターネットの荒野で観察されるディープフェイクのほとんどは低品質で、ポルノや娯楽目的で作成されている。これまでのところ、ディープフェイクの悪質な利用として最も多くの記録が残っているのは、女性への嫌がらせです。企業のプロジェクトやメディア制作では、より大きな予算で、動画を含むより洗練された出力を作成することができる。FireEyeの研究者は、最小限のリソースやAIの専門知識で、誰かが洗練されたAIの研究におんぶに抱っこになる方法を示したかった。
タリーのディープフェイク実験は、学術や企業のAI研究グループが最新の進歩を公然と公開し、しばしばコードを公開する方法(オープンソース)を利用したものだ。彼は「ファインチューニング」として知られている技術を使った。これは、大規模なデータセットの例を使って多額の費用をかけて構築された機械学習モデルを、はるかに小さな例のプールを使って特定のタスクに適応させるものだ。
偽トム・ハンクスを作るために、タリーは昨年、Nvidiaが公開した顔生成モデルを適応させた。Nvidiaは、強力なグラフィック・プロセッサのクラスタ上で数日かけて数百万の例題の顔を処理することで、そのソフトウェアを作った。タリーは、それをクラウドでレンタルした1台のGPU上で、1日もかからずにハンクス・ジェネレーターに適応させた。別の方法として、彼は自分のラップトップと30秒の音声クリップ3つ、そして大学院生がGoogleの音声合成プロジェクトをオープンソースで再現したものだけを使って、数分でハンクスの声を複製した。
AI研究者間の競争がさらなる進歩を促し、それらの結果が共有されると、ディープフェイクの生成コストはもっと低くなる可能性が高い。「このままでは、社会全体に悪影響を及ぼす可能性がある」とタリーはカンファレンスで発言した。タリーは以前、インターンと協力して、AIテキスト生成ソフトウェアが、2016年の大統領選挙を操作しようとしたロシアのインターネット諜報部が作成したものと同じようなコンテンツを作成できることを示したこともある。
FireEyeのプロジェクトは、最小限のリソースとオープンソースのAI研究の成果で何が実現できるかを示すことで、実用的な詳細を明らかにしている。Hwangは、こうした情報と、誤情報組織がどのように活動しているかについて知られていることを組み合わせることは、最悪のシナリオを考えるよりも、ディープフェイクの脅威を評価するためのより良い方法だと指摘した。
Facebookは最近、10万のディープフェイクのデータセットを公開し、その上で訓練された最も性能の高いディープフェイク検出器に50万ドルを提供した。優勝者は、Facebookのデータセットからディープフェイクを65%検出したが、これでは不十分だ。
参考文献
Philip Tully, Lee Foster. "Repurposing Neural Networks to Generate Synthetic Media for Information Operations". August 05, 2020.
Photo: このオバマはディープフェイクです。



