AMDがエヌビディアの背中に取りついた 詰まるAIチップの性能差
AMDはAIチップにおける性能差を大幅に縮めた可能性がある。しかし、ソフトウェアの面ではまだNVIDIAに匹敵していないと考えられる。


AMDはAIチップにおける性能差を大幅に縮めた可能性がある。しかし、ソフトウェアの面ではまだNVIDIAに匹敵していないと考えられる。
AMDとNVIDIAは、それぞれのAI半導体、「Instinct MI300X」とH100の性能をめぐって技術的な論争を繰り広げている。この論争は、性能をテストする際に使用された方法とデータタイプを中心に展開されている。
AMDは、「一般的なテスト方法」を使用した場合、自社のMI300XがNVIDIAのH100よりも高速であると主張した。リサ・スー最高経営責任者(CEO)らはプレゼンテーションの中で、メタのオープンソースLLMである「Llama 2」を使用したNVIDIA H100の推論性能と比較した。同社は8台のMI300Xで構成されるAMDのサーバー1台が、H100のサーバーより1.6倍高速に動作した、と主張した。
一方、NVIDIAは、AMDのテストはNVIDIAの「TensorRT-LLM」システムに特化した最適化を使用しておらず、NVIDIAはFP8と呼ばれる別のデータ型に最適化されているため、不公平であると反論。NVIDIAは、H100のようなAIに特化したチップは、NVIDIA独自のTensorRT-LLMで最適に動作するように特別に設計されていると説明している。NVIDIAによると、広く使用されているオープンソースの「vLLM」を使用すると、これらのチップのパフォーマンスが低下するという。
NVIDIAは、TensorRT-LLMを使用してMI300XとH100の性能比較を行い、それぞれが1秒間に処理できるクエリの数に着目した。その結果、この指標では、H100がMI300Xを大きく上回った。AMDが使用する標準的なレイテンシ(遅延)の基準を適用すると、NVIDIAは、MI300を14倍も上回るという驚くべき結果を示した。
 Dave Salvator
Dave Salvator
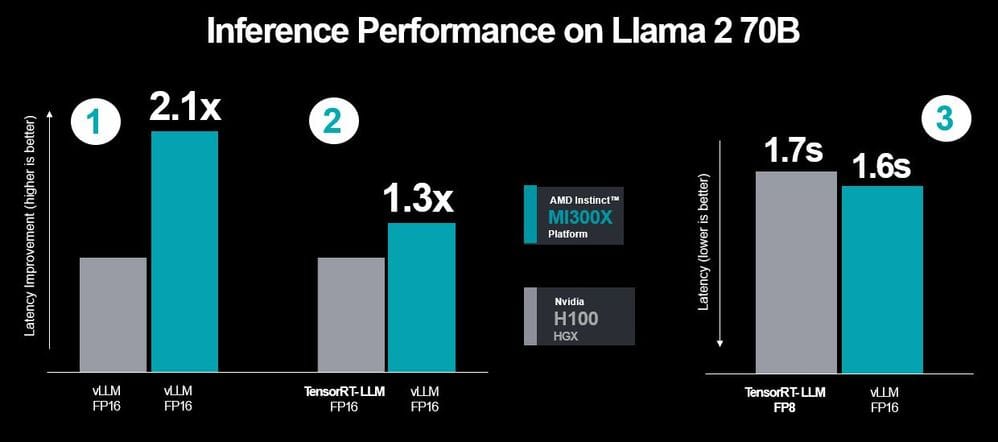
しかし、AMDはさらに反論した。AMDはNVIDIAの主張を汲み取った新たな性能比較を発表したのだ。AMDの発表によると、両者がvLLMを使用しFP8データ型で性能を比較した際、MI300XはH100を約2.1倍上回るスコアを達成した。また、H100がTensorRT-LLMを利用し、MI300XがvLLMを使用した場合でも、MI300XはH100より約1.3倍高いスコアを記録した。さらに、H100の「TensorRT-LLM利用、FP8」とMI300Xの「vLLM利用、FP16」を比較した結果、MI300Xの方がレイテンシが約0.1秒低いことが確認された(下図)。
議論の核心は、これらのテストがどのように実施され、どのような基準が使用されているかということだ。AMDは、NVIDIAのテストはサーバーの待ち時間など特定の要因を無視しており、あまり一般的でないテスト方法を使用しているため、実際の状況を反映していないと主張した。NVIDIAは、自社のH100が独自のテスト条件下でより優れた性能を発揮すると主張した。
ソフトウェアの大差は残る
AMDはAIチップの性能差を一気に詰めた可能性がある。ただ、まだ、ソフトウェアではNVIDIAに追いついていないだろう。NVIDIAは、市場を成長させるためのツールやアプリケーションの必要性を常に認識している。彼らは、NVIDIAハードウェア用のソフトウェアツール(例えば、CUDA)や最適化されたライブラリ(例えば、cuDNN)を入手するための障壁を非常に低くしている。
NVIDIAは自社のハードウェアを取り囲むように、強力なソフトウェアの構築を行っている。CUDAは自由に使用可能である一方、NVIDIAによって厳格に管理されるプロプライエタリ・ソフトウェアだ。この戦略はNVIDIAにとって利益をもたらしているが、他のハードウェアを使用してAI市場の一部を獲得しようとする他の企業やユーザーには障壁を生じさせている。
インテルらは後塵を拝する
チップ大手2社だけでなく、セレブラス・システムズやインテルといった他の企業も、この市場で頭角を現そうとしている。インテルのパット・ゲルシンガー最高経営責任者(CEO)は、最近の「AI Everywhere」イベントでAIチップ「Gaudi3」を予告したが、それについて明らかにされたことはほとんどなかった。Core Ultraのようなインテルがリリースした他の製品は、最新のものではなく、自信のなさの表れか、AMDの前世代と比較されていた。



