オープンソースのゲリラ勢がAI開発競争でGoogleとOpenAIを圧倒する?
コンサルティング会社SemiAnalysisが手に入れたGoogleの社内文書が波紋を広げている。文書は、GoogleとOpenAI/Microsoftの双方が、オープンソース陣営の「ゲリラ兵」に圧倒される可能性を示唆している。


コンサルティング会社SemiAnalysisが手に入れたGoogleの社内文書が波紋を広げている。文書は、GoogleとOpenAI/Microsoftの双方が、AI開発競争において、オープンソース陣営の「ゲリラ兵」に圧倒される可能性を示唆している。
社内文書の内容は、大規模言語モデル(LLM)の製品化はすでに驚異的なレベルまで民主化されていることを意味している。LLMが大手企業しか参加できないハイステークゲームだという前提はすでに過去のもののようだ。
この転覆を生んだのは、Metaが2月に発表したオープンソースのLLMであるLLaMAである。LLaMAは部分的にオープンソースで開発されているものの、非営利の研究目的でのみ利用可能で、重み付けのデータは一般公開されていない。
LLaMAを用いれば、研究者は微調整という軽いコストを負担するだけで、参入することができる。「トレーニングや実験への参入障壁は、大手研究機関の総生産量から、一人の人間、一晩、そして頑丈なラップトップにまで低下した」と社内文書には書かれている。


3月に公開された、LLaMAをベースとした2つのオープンソースモデル(VicunaとAlpaca)は、AIコミュニティの注目を集めることに成功し、どちらも無数の応用例を生み出している。
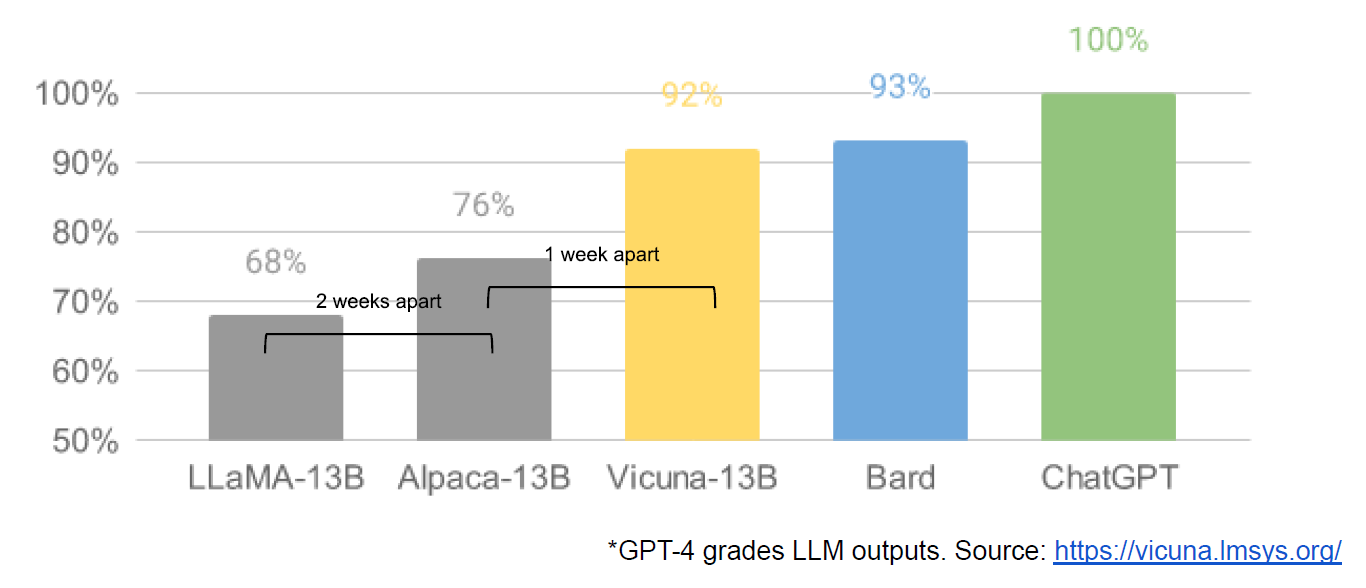
LLaMAを微調整したオープンソースのチャットボットであるVicunaは、OpenAI ChatGPTやGoogle Bardの90%以上の品質を達成する一方、LLaMAやAlpacaといったモデルを90%以上のケースで凌駕した、とカリフォルニア大学バークリー校、サンディエゴ校、カーネギーメロン大学の研究者らは発表している。
Vicunaの70億パラメータ版と130億パラメータ版のトレーニング費用はそれぞれ約70ドルと約300ドルに留まる。コードと重みは、オンラインデモとともに、非商用で利用できるよう公開されている。

 lm-sys
lm-sys下の図は、Vicunaの研究チームによる図表に、流出文書の中でGoogle社員が「2週間しか離れていない」などと書き加えた図だ。LLaMAの登場以降、それを基にしたオープンソースモデルが、GoogleのBardとOpenAIのChatGPTにあっという間に追いつく様を描いたものだ。TransformerのようなLLMの中核技術を研究開発してきたGoogleにとっては、オープンソース勢の驚異的な追走は相当イライラするものなのかもしれない。
同じくLLaMAを基にした70億パラメータのLLMであるAlpacaでは、iPhone 14でローカルで動作するよう微調整するまでにオープンソースの人々が要した時間は、たったの3週間だった。構築費用は「600ドル以下」であったと報告されている。

AlpacaのiPhoneでの動作は、エッジデバイスにLLMが移植される未来を予見させるのに十分である。ただ、まだ改良の余地は大きいようだ。Alpacaの回答は通常ChatGPTより短く、幻覚、毒性、ステレオタイプなど、言語モデルによくある問題を示している。
モデルの小型化とドメイン固有化は重要なトレンドの1つである。より良いデータで再調整された小さなモデルは、より多くのデータで完全に再調整された大きなモデルよりも、特定のタスクでは勝るかもしれない。これは世界中のソフトウェアエンジニアの参加を募れるオープンソース側に有利なのかもしれない。
ドメイン固有が安く済む証拠はある。Microsoftが生み出した「LoRA(Low Rank Adaptation)」と呼ばれる技術では、基本的には、ドメイン固有のモデルを作る場合、すべてのモデルパラメータを再学習するのではなく、変更する必要があるパラメータを見つけるだけでよい。これによって計算コストを大幅に削減できることを同社のチームは示している。
また、LLaMAを基にGoogleやOpenAIを追走しようとするプロジェクトも活気づいている。RedPajamaは、完全にオープンソース化された大規模言語モデルを開発するプロジェクトで、AIスタートアップのTogether、Ontocord.ai、チューリッヒ工科大学のETH DS3Lab、スタンフォード大学のStanford CRFM、Hazy Research、MILA Québec AI Instituteによる共同研究プロジェクトとして進められている。RedPajamaはその第一段階として、1兆2千億以上のトークンを含むLLaMAトレーニングデータセットを公開した。
 Together
Together



