DeepMindのAgent57はアタリのゲームで人間のベンチマークを上回る
Atari57のゲームは、幅広いタスクでエージェントのパフォーマンスを評価するための長年のベンチマークだ。DeepMindの研究者らはAgent57を開発した。Agent57は、57のAtari 2600ゲームすべてにおいて、人間のベースラインを上回るスコアを得た初の深層強化学習エージェントだ。Agent57は、効率的な探索のためのアルゴリズムと、探索とエージェントの長期対短期の行動を適応させるメタコントローラを組み合わせている。


要点
Atari57のゲームは、幅広いタスクでエージェントのパフォーマンスを評価するための長年のベンチマークだ。DeepMindの研究者らはAgent57を開発した。Agent57は、57のAtari 2600ゲームすべてにおいて、人間のベースラインを上回るスコアを得た初の深層強化学習エージェントだ。Agent57は、効率的な探索のためのアルゴリズムと、探索とエージェントの長期対短期の行動を適応させるメタコントローラを組み合わせている。
エージェント57の先祖
2012年には、アーケード学習環境のAtari57が、タスクのベンチマークセットとして提案された。これらの標準的なAtariゲームは、エージェントがマスターするための幅広い課題を提供する。研究者コミュニティでは、このベンチマークを一般的に使用して、より知的なエージェントの構築の進捗状況を測定している。 広範囲のタスクに対するエージェントの性能を一つの数値としてまとめることが望ましい場合が多いため、Atari57ベンチマークの平均性能(全ゲームの平均値または中央値)は、エージェントの能力をまとめるためによく使われる。平均スコアは時間の経過とともに徐々に上昇している。
残念ながら、平均性能は、エージェントがどれだけ多くのタスクでうまくやっているかを捉えることができず、エージェントがどれだけ一般的かを判断するのに良い統計量ではない。それは、エージェントが十分にうまくやっていることは捉えるが、十分に広いタスクのセットで十分にうまくやっているということを意味しない。だから、平均スコアは増加しているが、今までのところ、人間以上のプレイを達成したゲーム数は増加していない。
例として、20個のタスクからなるベンチマークを考えてみると、エージェントAが8つのタスクで500%、4つのタスクで200%、8つのタスクで0%(平均=240%、中央値=200%)のスコアを得ているのに対し、エージェントBは全てのタスクで150%(平均=中央値=150%)のスコアを得ているとする。平均的には、エージェントAはエージェントBよりも優れたパフォーマンスを発揮するが、エージェントBはより一般的な能力を持っている。
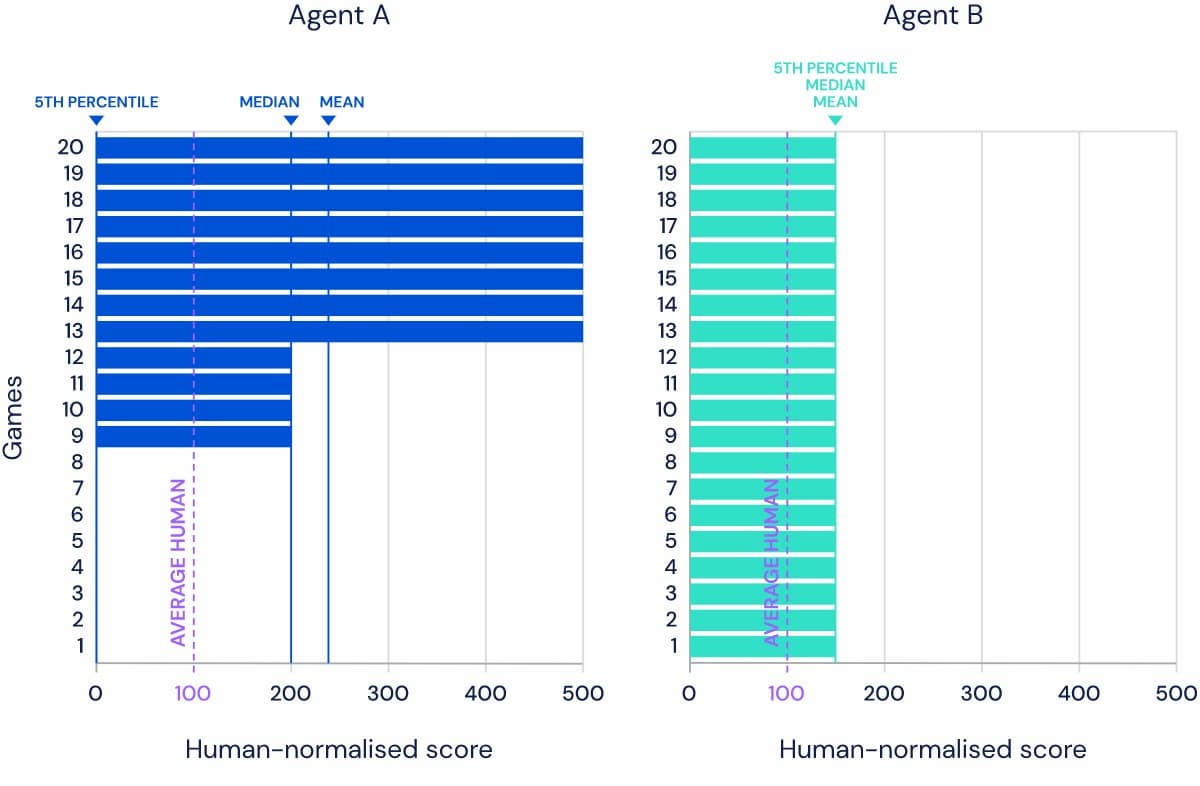
この問題は、いくつかのタスクが他のタスクよりもはるかに簡単な場合に悪化する。非常に簡単なタスクで非常に良いパフォーマンスを発揮することで、エージェントAは簡単なタスクと難しいタスクの両方で良いパフォーマンスを発揮するエージェントBを明らかに上回ることができる。
中央値は、いくつかの簡単なゲームでの例外的なパフォーマンスによって歪められることが少なく、分布の中心を示す平均値よりも頑健な統計量だ。しかし、汎用性を測定する場合、特にタスクの数が多くなるにつれて、分布の尾部がより適切になる。例えば、ゲームの中で最も難しい5パーセンタイルでのパフォーマンスの測定値は、エージェントの汎用性の程度をより代表することができる。
研究者は、Atari57ベンチマークの開始以来、エージェントの平均性能を最大化することに焦点を当てており、平均性能は過去8年間で大幅に上昇している。しかし、上記の例示的な例のように、すべてのAtariゲームが同じというわけではなく、他のゲームよりもはるかに簡単なゲームもあります。平均性能を調べるのではなく、下位5%のゲームでのエージェントの性能を調べると、2012年からあまり変わっていないことがわかる。実際、2019年に公開されたエージェントは、2012年に公開されたエージェントが苦戦していたゲームと同じゲームで苦戦していた。 Agent57はこれを変え、ベンチマーク開始以来のどのエージェントよりもAtari57の中では一般的なエージェントとなっている。Agent57は、ベンチマークセットの中で最も難しいゲームだけでなく、最も簡単なゲームでも、最終的に人間レベル以上の性能を獲得したとDeepMindの研究者は説明している。
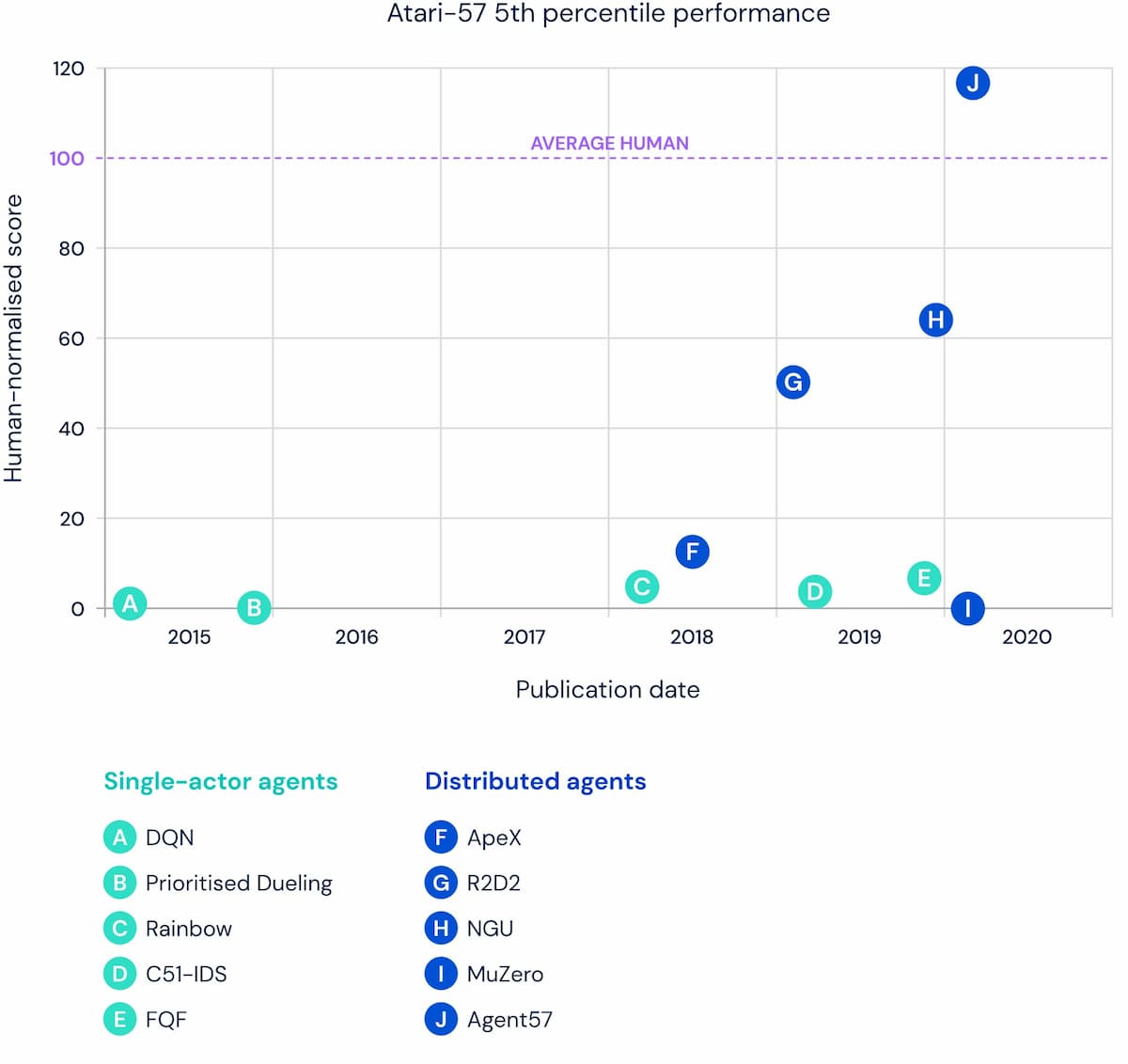
2012年、DeepMindはAtari57スイートに取り組むためにDeep Q-networkエージェント(DQN)を開発した。それ以来、研究コミュニティはDQNの多くの拡張機能や代替機能を開発してきた。しかし、これらの進歩にもかかわらず、すべての深層強化学習エージェントは、4つのゲームで一貫してスコアを出すことができませんでした。モンテズマの復讐」、「ピットフォール」、「ソラリス」、「スキー」だ。
Montezuma's RevengeとPitfallでは、良好なパフォーマンスを得るために広範な探索が必要だ。学習における中心的なジレンマは、探索と探索の問題である。例えば、地元のレストランでいつも同じお気に入りの料理を注文するべきか、それとも昔からのお気に入りを上回るかもしれない何か新しいものを試すべきか。探索には、最終的により強力な行動を発見するために必要な情報を収集するために、多くの最適でない行動を取ることが含まれる。
SolarisとSkiingは長期的な信用割り当ての問題である。これらのゲームでは、エージェントの行動の結果とそれが受け取る報酬を一致させることが困難である。エージェントは学習に必要なフィードバックを得るために、長い時間スケールで情報を収集しなければならない。
Agent57が他のAtari57のゲームに加えて、これら4つのチャレンジングなゲームに取り組むためには、DQNにいくつかの変更を加える必要があった。
DQNの改善
DQNの初期の改良では、ダブルDQN、経験の優先再生、決闘アーキテクチャなど、学習効率と安定性が向上しました。これらの変更により、エージェントは経験をより効率的かつ効果的に利用できるようになった。
分散エージェント
次に、研究者たちは、多くのコンピュータ上で同時に実行できる分散型のDQN、Gorila DQN、ApeXを導入しました。これにより、エージェントはより迅速に経験を獲得し、経験から学ぶことができ、研究者はアイデアを迅速に反復することができるようになった。また、Agent57は、データ収集と学習プロセスを切り離した分散型RLエージェントである。多くのアクターが環境の独立したコピーと相互作用し、優先順位付けされたリプレイバッファの形で中央の「メモリバンク」にデータを供給する。図4に示すように、学習者はこのリプレイ・バッファからトレーニング・データをサンプリングする。 学習者は、これらのリプレイ経験を使って損失関数を構築し、行動やイベントのコストを推定する。そして、損失を最小化することでニューラルネットワークのパラメータを更新する。最後に、各アクターは学習者と同じネットワーク・アーキテクチャを共有しますが、重みの独自のコピーを持ちます。学習者の重みはアクターに頻繁に送られ、後述するように、アクターは個々の優先順位によって決定された方法で自分の重みを更新することができる。
短期記憶
エージェントは、過去の観察を考慮に入れて意思決定を行うために、記憶を持つ必要がある。これにより、エージェントは、現在の観察(通常は部分的な観察、つまり、エージェントは自分の世界の一部しか見ていない)だけでなく、環境全体についてのより多くの情報を明らかにすることができる過去の観察に基づいて意思決定を行うことができるようになる。例えば、ある建物内の椅子の数を数えるために、エージェントが部屋から部屋へと移動するタスクを想像してみてください。記憶がなければ、エージェントはある部屋の観察にしか頼ることができない。記憶があれば、エージェントは前の部屋の椅子の数を記憶し、現在の部屋で観察している椅子の数を足すだけでタスクを解くことができる。したがって、記憶の役割は、過去の観察から得られた情報を集約して意思決定プロセスを改善することである。ディープRLやディープラーニングでは、短期記憶としてLSTM(Long-Short Term Memory)などのリカレントニューラルネットワークが用いられる。
記憶と行動とのインターフェースは、自己学習するシステムを構築する上で極めて重要である。強化学習では、エージェントは、その直接的な行動の価値のみを学習することができるオンポリシー学習者になることができ、または、それらの行動を実行していなくても最適な行動について学習することができるオフポリシー学習者になることができる。例えば、ランダムな行動を取っているかもしれないが、可能な限り最高の行動が何であるかを学習することができる。
したがって、オフポリシー学習はエージェントにとって望ましい特性であり、エージェントが自分の環境を徹底的に探索しながら、取るべき最善の行動のコースを学ぶのを助ける。方針外学習と記憶を組み合わせるのは難しいが、異なる行動を実行するときに何を覚えているかを知る必要があるからである。例えば、リンゴを探しているときに覚えていること(例えば、リンゴがどこにあるか)は、オレンジを探しているときに覚えていることとは異なります。しかし、オレンジを探していたとしても、将来的にリンゴを探す必要が出てきた場合に備えて、偶然リンゴに出くわしたとしても、リンゴを探す方法を覚えることができます。メモリとオフポリシー学習を組み合わせた最初のディープRLエージェントは、ディープリカレントQ-Network (DRQN) でした。さらに最近になって、短期記憶のニューラルネットワークモデルとオフポリシー学習と分散学習を組み合わせたRecurrent Replay Distributed DQN (R2D2) でAgent57の系譜に大きなスペシエーションが発生し、Atari57で非常に強い平均性能を達成した。 R2D2は、過去の経験からの学習のためのリプレイの仕組みを短期記憶に働きかけるように修正している。以上のことから、R2D2は収益性の高い行動を効率的に学習し、報酬を得るためにそれを利用することができた。
エピソード記憶
私たちは、R2D2を別の記憶形態であるエピソード記憶で補強するために、Never Give Up (NGU)を設計した。これにより、NGUはゲームの新しい部分に遭遇したときにそれを検出することができ、それが報酬をもたらす場合には、エージェントはゲームのこれらの新しい部分を探索することができるようになる。これにより、エージェントの行動(探索)は、エージェントが学習しようとしている方針(ゲームで高得点を得ること)から大きく逸脱してしまいます。NGUは、Atari57ベンチマークが導入されて以来、誰もポイントを獲得していないゲームであるPitfallや、他の難解なAtariゲームで、ドメイン知識なしで、ポジティブな報酬を獲得した最初のエージェントだった。残念なことに、NGUは、歴史的に「より簡単な」ゲームでパフォーマンスを犠牲にしているため、平均的には、R2D2と比較して低いパフォーマンスとなっている。
直接的な探索を促すための本能的動機づけの方法
最も成功した戦略を発見するためには、エージェントは環境を探索しなければならないが、探索戦略の中には他の戦略よりも効率的なものもある。DQNでは、イプシロン・グリーディとして知られる無方向探索戦略を用いて探索問題を解決しようとした。一定の確率(イプシロン)でランダムな行動をとり、そうでなければ現在の最良の行動を選ぶ。報酬がない場合、大きな状態行動空間を探索するのに膨大な時間を必要とする。この限界を克服するために、多くの有向探索戦略が提案されてきた。
これらの中で、ある分野では、新規性を求める行動に対してより密な「内部」報酬を提供することで、エージェントが可能な限り多くの状態を探索し、訪問することを促す内発的動機報酬の開発に焦点を当ててきた。その中で、我々は2つのタイプの報酬を区別している。第一に、長期的なノベルティ報酬は、訓練期間中、多くのエピソードに渡って多くの状態を訪問することを促す。第二に、短期的なノベルティ報酬は、短期間(例えば、ゲームの1エピソード内)に多くの状態を訪問することを促すものである。
長期的な目新しさを求める
長期的な新奇性報酬は、以前に見たことのない状態がエージェントの生涯で遭遇したときのシグナルであり、訓練中にこれまでに見た状態の密度の関数である。密度が高い場合(その状態がよく知られていることを示す)、長期的な新規性報酬は低く、その逆もまた然りだ。すべての状態が見慣れた状態であれば、エージェントは無方向の探索戦略に頼ることになる。しかし、高次元空間の密度モデルの学習は、 「次元の呪い」のために問題が多い。実際には、エージェントが深層学習モデルを用いて密度モデルを学習する場合、壊滅的な忘却(新しい経験に遭遇すると以前に見た情報を忘れる)や、すべての入力に対して正確な出力を生成することができないことに悩まされる。
たとえば、Montezuma's Revengeでは、指向性のない探索戦略とは異なり、長期的な新規性の報酬により、エージェントは人間のベースラインを超えることができる。しかし、モンテズマの復讐で最高のパフォーマンスを発揮する方法であっても、密度モデルを適切な速度で注意深く訓練する必要がある。密度モデルが最初の部屋の状態が馴染みのあるものであることを示すとき、エージェントは一貫して馴染みのない領域に到達することができるはずだ。
Never Give Up (NGU)は、制御可能な状態に基づく短期ノベルティ報酬を、ランダムネットワーク蒸留を用いて長期ノベルティ報酬と混合して使用した。これは、長期的な新規性が制限されている場合に、両方の報酬を掛け合わせることで実現された。このようにして、短期的な目新しさの報酬の効果は維持されるが、 エージェントが生涯にわたってゲームに慣れてくると、その効果はダウンモディ ュールされる可能性がある。NGUのもう一つのコアアイデアは、純粋に搾取的なものから高度に探索的なものまで、ポリシーのファミリーを学習するということだ。R2D2の上に構築することで、アクターは総新規性報酬の重要度の重み付けに基づいて、異なるポリシーでの経験を生成する。この経験は、ファミリー内の各重み付けに関して一様に生成される。
メタコントローラ:探索と搾取のバランスを学ぶ
エージェント57は、次のような観察に基づいて構築されています:もしエージェントが、いつ搾取するのが良いのか、いつ探索するのが良いのかを学習できるとしたらどうでしょうか? 我々は、探索と探索のトレードオフを適応させるメタコントローラの概念と、より長い時間的なクレジット割り当てを必要とするゲームのために調整可能な時間地平線を導入した。この変更により、Agent57は、簡単なゲームでもハードなゲームでも人間レベル以上のパフォーマン スを得ることができるようになった。
具体的には、内在的動機付けの方法には2つの欠点がある。
- 探索。多くのゲームは、特にゲームが完全に探索された後に、純粋に搾取的な方針に従順である。このことは、ネバーギブアップでの探索的なポリシーによって生成される経験の多くは、エージェントが関連するすべての状態を探索した後に、最終的には無駄になることを意味する。
- 時間の地平線。スキーやSolarisのように、遠い将来に得られる報酬を評価することは、最終的に良い搾取的政策を学ぶために、あるいは良い政策を全く学ぶために重要かもしれない。同時に、将来の報酬が過度に重み付けされている場合、他のタスクは学習に時間がかかり、不安定になる可能性がある。このトレードオフは強化学習における割引率によって一般的に制御されており、割引率が高いほど長い時間軸での学習が可能になる。このことが、可変長の時間水平線と新規性の重要性を考慮して、異なるポリシーで生成される経験の量を制御するオンライン適応メカニズムの使用を動機づけた。研究者たちは、異なるハイパーパラメータの値を持つエージェントの集団を訓練する、勾配降下によってハイパーパラメータの値を直接学習する、ハイパーパラメータの値を学習するために中央集権型バンディットを使用するなど、複数の方法でこれに取り組むことを試みてきた。
研究者らはバンディットアルゴリズムを使用して、経験を生成するためにエージェントが使用すべきポリシーを選択した。具体的には、各アクターに対してスライドウィンドウ型UCBバンディットを訓練し、そのポリシーが持つべき探索への選好度と時間軸を選択した。
エージェント57:すべてをまとめる
エージェント57を達成するために、我々は以前に開発した探索エージェントNever Give Upをメタコントローラと組み合わせた。このエージェントは、ポリシーのファミリーを探索して学習するために、長期と短期の内在的動機を混合したものを計算する。メタコントローラは、エージェントの各アクタ ーが、新しい状態を探索するか、すでに知られていることを利用するかの違いと同様に、 近い期間と長期のパフォーマンスの間で異なるトレードオフを選択することを可能にする。強化学習はフィードバックループです:選択されたアクションが訓練データを決定します。したがって、メタコントローラはまた、エージェントがどのようなデータから学習するかを決定する。

結論と今後の展開
エージェント57では、Atari57ベンチマークのすべてのタスクにおいて人間以上の性能を持つ、より一般的なインテリジェント・エージェントを構築することに成功した。このエージェントは、以前のエージェントNever Give Upをベースに構築されており、適応的なメタコントローラをインスタンス化している。広範囲のタスクは当然、これらのトレードオフの両方の異なる選択を必要とするので、 メタコントローラはそのような選択を動的に適応させる方法を提供する。
Agent57は計算量の増加に伴ってスケーリングすることができた。これによりAgent57は強力な一般性能を達成することができたが、多くの計算量と時間を必要とし、データ効率は確実に改善することができる。さらに、このエージェントはAtari57のゲームのセットで5パーセンタイルのより良い性能を示した。これは、データ効率の面だけでなく、一般的な性能の面でも、決してアタリの研究の終わりを意味するものではない。第一に、パーセンタイル間の性能を分析することで、一般的なアルゴリズムがどのようなものであるかについて新たな洞察を得ることができる。第一に、パーセンタイル間の性能を分析することで、一般的な アルゴリズムがどのようなものであるかを知ることができる。第二に、現在のアルゴリズムはすべて、いくつかのゲームで最適なパフォーマンスを達成するには程遠いということだ。そのためには、Agent57が探索、計画、およびクレジット割り当てのために使用する表現を強化することが、使用するための重要な改善点になるかもしれない。
※本稿はDeepMindの「How to measure Artificial General Intelligence?」の抄訳です。



