AIに対する「大きければ大きいほどいい」アプローチが行き詰まりつつある[英エコノミスト]

![AIに対する「大きければ大きいほどいい」アプローチが行き詰まりつつある[英エコノミスト]](/content/images/size/w1200/2023/06/google-deepmind-ggeXPf_ykAU-unsplash-1.jpg)
アメリカの研究機関OpenAIが作った人気チャットボットChatGPTを動かすGPTのような「大規模言語モデル(LLM)」に関して言えば、そのヒントは名前にある。現代のAIシステムは、生物の脳を大雑把にモデル化したソフトウェアの断片である巨大な人工ニューラルネットワークによって動いている。ニューロン間の接続をシミュレートしたもので、1,750億個の「パラメータ」を持っていた。GPT-3は、何千ものGPU(AI作業を得意とする特殊なチップ)に数週間かけて何千億ワードものテキストを読み込ませることで訓練された。そのために少なくとも460万ドルの費用がかかったと考えられている。
しかし、現代のAI研究の最も一貫した結果は、大きいことは良いことだが、より大きいことはより良いことだということだ。3月にリリースされたGPT-4は、前作の6倍近い約1兆個のパラメータを持つと考えられている。同社のボスであるサム・アルトマンは、その開発費を1億ドル以上としている。同様の傾向は業界全体に見られる。調査会社のEpoch AIは2022年、最先端のモデルを訓練するのに必要なコンピューティングパワーは、6ヶ月から10ヶ月ごとに倍増していると推定している(図表参照)。
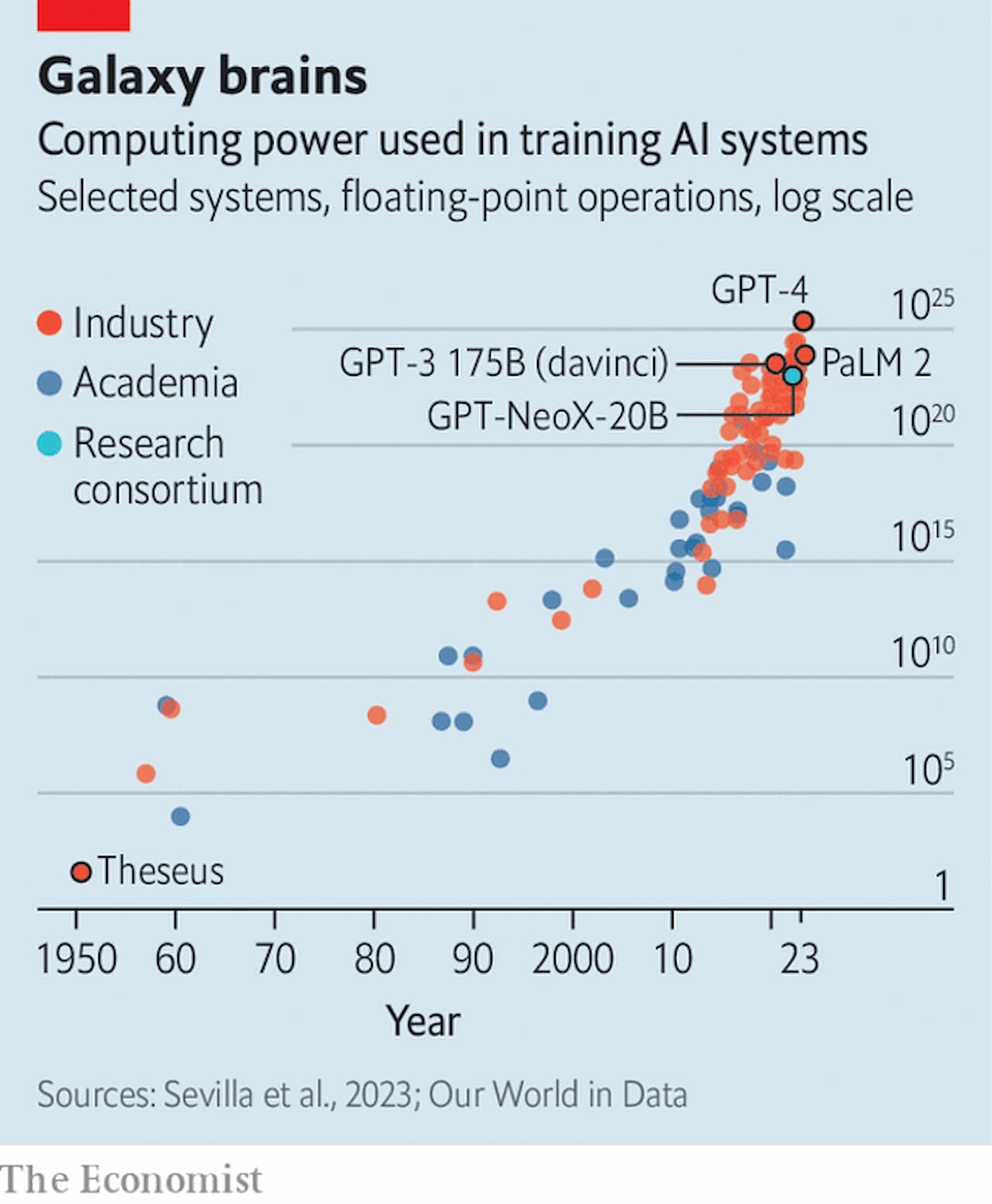
この巨大化が問題になっている。もしEpoch AIの10ヶ月ごとに倍増するという数字が正しければ、トレーニングコストは2026年までに10億ドルを超える可能性がある。2022年10月に発表された分析によると、トレーニング用の高品質なテキストのストックは、同じ時期に枯渇する可能性が高いと予測されている。また、トレーニングが完了した後でも、出来上がったモデルを実際に使用するにはコストがかかる。モデルの規模が大きくなればなるほど、実行コストは高くなる。今年初め、銀行のモルガン・スタンレーは、Googleの検索の半分を現在のGPTスタイルのプログラムで処理した場合、年間60億ドルの追加コストがかかると推測した。モデルが大きくなればなるほど、この数字はおそらく上昇するだろう。
したがって、この分野の多くの人々は、「大きければ大きいほど良い」というアプローチはもう限界だと考えている。もしAIモデルが改良を続け、現在ハイテク業界を席巻しているAI関連の夢を実現するのであれば、AIモデルの開発者は、より少ないリソースでより高いパフォーマンスを得る方法を見つけ出す必要がある。アルトマン氏は4月、巨大なAIの歴史を振り返り、次のように述べた。
量的強化
その代わりに、研究者たちはモデルを単に大きくするのではなく、より効率的にすることに目を向け始めている。ひとつのアプローチは、パラメーターの数を減らしつつ、より多くのデータでモデルをトレーニングするというトレードオフを行うことだ。2022年、グーグルの一部門であるディープマインドの研究者たちは、700億個のパラメータを持つllmであるChinchillaを14億語のコーパスで訓練した。このモデルは、3,000億語で訓練された1,750億パラメータを持つGPT-3を凌駕した。より小さなllmに多くのデータを与えることは、訓練に時間がかかることを意味する。しかし、その結果、より小さく、より速く、より安く使えるモデルができる。
もうひとつの選択肢は、計算をより曖昧にすることだ。モデル内の各数値の小数点以下の桁数を少なくする、つまり四捨五入することで、ハードウェアの要件を大幅に削減することができる。オーストリアの科学技術研究所の研究者たちは3月、四捨五入によってGPT-3と同様のモデルが消費するメモリ量を削減できることを示し、ハイエンドのGPU5台ではなく1台で動作させることを可能にした。
法律文書の生成やフェイクニュースの検出など、特定のタスクに集中するために汎用llmsを微調整するユーザーもいる。そもそもllmを訓練するほど面倒ではないが、それでもコストと時間がかかる。フェイスブックの親会社であるメタ社が構築した、650億ものパラメーターを持つオープンソースのモデルであるllamaの微調整には、複数のGpusが数時間から数日かかる。
ワシントン大学の研究者たちは、より効率的な方法を考案し、性能をほとんど犠牲にすることなく、1台のGPUで1日でllamaから新しいモデルGuanacoを作成することを可能にした。そのトリックの一つは、オーストリア人と同様の丸め技術を使うことだった。これは、モデルの既存のパラメーターを凍結し、その間に新しい、より小さなパラメーターのセットを追加するというものだ。微調整は、新しい変数のみを変更することで行われる。これなら、スマートフォンのような比較的弱々しいコンピューターでも十分可能だろう。現在のような巨大なデータセンターではなく、ユーザーのデバイス上で動作するようにすることで、よりパーソナライズされ、よりプライバシーが守られるようになる。
一方、グーグルのあるチームは、より小さなモデルでやっていける人たちのために、別の選択肢を考え出した。このアプローチは、大きな汎用モデルから必要な特定の知識を小さな専門モデルに抽出することに焦点を当てている。大きなモデルは教師の役割を果たし、小さなモデルは生徒の役割を果たす。研究者は先生に質問に答えてもらい、どのように結論に至ったかを示す。その答えと教師の推論の両方が、生徒モデルの訓練に使われる。研究チームは、わずか7億7,000万個のパラメータを持つ生徒モデルを訓練することができ、特殊な推論タスクにおいて5億4,000万個のパラメータを持つ教師モデルを上回った。
モデルが何をしているかに注目するのではなく、モデルの作り方を変えるというアプローチもある。AIのプログラミングの多くは、Pythonと呼ばれる言語で行われている。Pythonは使いやすく設計されており、チップ上でプログラムがどのように動作するかを厳密に考える必要からコーダーを解放してくれる。そのような詳細を抽象化する代償として、コードが遅くなる。このような実装の細部にもっと注意を払えば、大きな利益をもたらすことができる。オープンソースのAI企業であるHugging Faceの最高科学責任者、トーマス・ウルフは、これは「現在のゲームの大きな部分」だと言う。
コードを学ぶ
例えば2022年、スタンフォード大学の研究者たちは「アテンション・アルゴリズム」の改良版を発表した。そのアイデアは、コードを実行しているチップ上で何が起こっているかを考慮し、特に与えられた情報の断片がいつ検索または保存される必要があるかを追跡するようにコードを修正することだった。彼らのアルゴリズムは、古いLLMであるGPT-2の学習を3倍高速化することができた。また、より長いクエリにも対応できるようになった。
より洗練されたコードは、より優れたツールからも得ることができる。今年初め、MetaはAIプログラミングフレームワークであるPyTorchのアップデート版をリリースした。コーダーが実際のチップ上でどのように計算が配置されるかをより深く考えられるようにすることで、たった1行のコードを追加するだけで、モデルの学習速度を2倍にすることができる。AppleとGoogleの元エンジニアが設立した新興企業Modularは先月、PythonをベースにしたMojoと呼ばれるAIに特化した新しいプログラミング言語をリリースした。この言語もまた、以前は隠されていたあらゆる種類の細かいディテールをコーダーにコントロールさせる。場合によっては、Mojoで書かれたコードはPythonで書かれた同じコードよりも数千倍速く実行できる。
最後の選択肢は、そのコードが動作するチップを改良することだ。GPUはAIソフトウェアを実行するのに偶発的に優れているに過ぎない。特に、Metaのハードウェア研究者によれば、GPUは「推論」作業(一度学習させたモデルを実際に動かすこと)には不完全な設計だという。そのため、より特殊なハードウェアを独自に設計している企業もある。Googleはすでに、AIプロジェクトのほとんどを社内の「TPU」チップで実行している。MTIAを持つMetaや、AWS Inferentiaチップを持つAmazonも同様の道を追求している。
概算やプログラミング言語の切り替えといった比較的単純な変更で、これほど大きな性能向上が可能なのは意外に思えるかもしれない。しかし、これはLLMが猛烈なスピードで開発されてきたことを反映している。長い間、研究プロジェクトであったLLMは、エレガントにすることよりも、単にうまく動作させることの方が重要であった。最近になってようやく、商業的な大衆向け製品へと発展してきたのだ。ほとんどの専門家は、まだまだ改良の余地があると考えている。スタンフォード大学のコンピューター科学者、クリス・マニングはこう言う。「『これが究極のニューラル・アーキテクチャであり、これ以上のものが見つかることはない』と信じる理由はまったくない」。■
From "The bigger-is-better approach to AI is running out of road", published under licence. The original content, in English, can be found on https://www.economist.com/science-and-technology/2023/06/21/the-bigger-is-better-approach-to-ai-is-running-out-of-road
©2023 The Economist Newspaper Limited. All rights reserved.
翻訳:吉田拓史、株式会社アクシオンテクノロジーズ



