メタの自己教師あり学習モデルは「1つですべて兼ねる」への一歩か
メタの研究者は、音声、画像、テキストを処理できる単一のAIモデルを訓練したと発表した。このマルチモーダルシステムが将来的に同社の拡張現実やメタバース製品を動かすことが期待されている。


メタの研究者は音声、画像、テキストを処理できる単一のAIモデルを訓練したと発表した。このマルチモーダルシステムが将来的に同社の拡張現実やメタバース製品を動かすことが期待されている。
このモデルは「data2vec」と呼ばれ、さまざまなタスクを実行できる。多くの機械は、ラベル付きのデータからのみ学習する。しかし、自己教師あり学習により、機械は世界を観察するだけで、画像、音声、テキストの構造を把握して学習することができる
「これは、より多くの音声言語のテキストを理解するなど、機械が新しい複雑なタスクに取り組むための、よりスケーラブルで効率的なアプローチだ」とメタの研究者は語っている。
AIのアルゴリズムは通常、1種類のデータで学習するが、data2vecは3つの異なるモダリティで学習する。ただし、音声、画像、テキストなど、それぞれの形式を個別に処理することに変わりはない。
メタは、このようなマルチモーダルなモデルがあれば、メタバースのようなデジタル空間の中で、AIエージェントをその環境に順応させることができると考えているようだ。
data2vecを使えば、ラベル付きデータに頼らずに、「世界のさまざまな側面を学習する機械」を作ることができるようになる。これにより、より一般的な自己教師付き学習への道が開かれ、AIが動画や記事、音声記録を使って、サッカーの試合やパンの焼き方の違いなど、複雑なテーマについて学習する世界に近づくことができる。また、Data2vecは、より適応性の高いAIを開発することを可能にし、現在可能な範囲を超えたタスクをこなすことができるようになると研究者らは考えている。
Data2vecは、Transformerベースのニューラルネットワークで、自自己教師あり学習を用いて、オーディオ、コンピュータビジョン、自然言語処理の共通パターンを学習する。このモデルは、与えられたデータの表現方法を予測する方法を学習することで、さまざまな種類のデータを扱うことを学ぶ。モデルは画像が与えられた場合は次のピクセルを、音声の場合は次の発話を、文章の場合は単語を埋めることを推測しなければならないことを知っている。
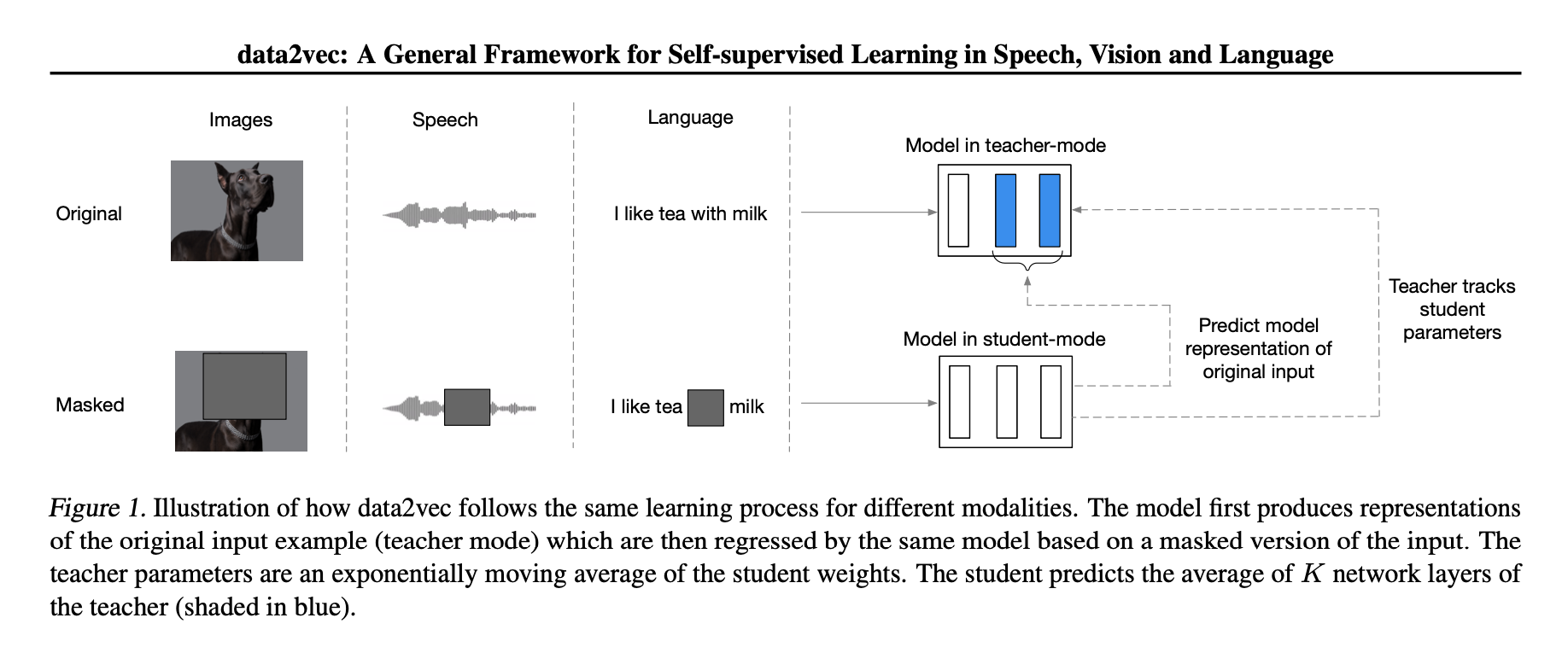
研究者たちは、16個のNvidia V100およびA100 GPUを組み合わせて、960時間の音声、書籍やWikipediaのページにある数百万の単語、ImageNet-1Kの画像を使ってdata2vecを学習させた。
Meta AIのリサーチエンジニアであるAlexei Baevskiは、英テクノロジーメディアThe Registerに次のように述べている。「モダリティごとに別々のモデルをトレーニングしているが、モデルが学習するプロセスは同じだ。将来的には、モダリティを組み合わせて、特化したモデルよりも効果的な高性能の自己教師付きモデルを構築することが可能になると期待している。異なるモダリティは、同じコンテンツに付加的な情報を加えることができる。例えば、動画のボディランゲージ、音声の韻律情報、テキストを組み合わせることで、より豊かな対話の表現が可能になる。現在、マルチモーダルな情報を組み合わせようとするアルゴリズムは存在するが、専門的なアルゴリズムに取って代わるほどの性能はまだない」。
Baevskiは、将来的にマルチモーダルシステムは、匂い、3Dオブジェクト、ビデオなどの概念をモデル化するために、より広範囲のデータを取り込むことができると述べている。
彼は、ARグラスをかけて料理をするというアイデアを紹介した。「様々なレストランやシェフの何千時間にも及ぶ料理の記録をもとに学習されたモデルがあるとする。このモデルにアクセスできるARグラスを装着してキッチンで料理をすると、次に何をすべきかを示す視覚的な合図がオーバーレイされ、潜在的なミスを指摘したり、特定の食材を加えることで料理の味にどのような影響があるかを説明したりすることができる」とThe Registerに対し語っている。
マルチモーダルシステムに関するこれまでの研究では、敵対的な攻撃を受けやすいことが指摘されている。例えば、OpenAIのCLIPモデルは、画像とテキストを学習しており、リンゴの画像に「iPod」という文字があると、誤ってiPodと認識してしまう。しかし、data2vecに同じような弱点があるかどうかは不明だ。
「しかし、現在のモデルはモダリティごとに個別に学習されているため、モダリティごとの敵対的攻撃の分析に関する既存の研究は、私たちの研究にも適用できると考えている」とBaevskiはThe Registerに対し述べている。
「将来的には、今回の研究を利用して、モダリティを1つのモデルにまとめた高性能なアルゴリズムを実現し、それらが敵対的攻撃に対してどのような影響を受けるかを研究する予定だ」
メタの研究者らがdata2vecをテストしたところ、特定のデータタイプのみで訓練された上位モデルのいくつかを、異なるタイプのタスクで凌駕した。この予備的な結果は論文に記載されており、コードはGitHubで公開されている。
「Data2vecは、同じ自己教師付きアルゴリズムが異なるモダリティでもうまく機能すること、そしてしばしば既存の最良のアルゴリズムよりもうまく機能することを示している。これは、より一般的な自己教師付き学習への道を開くものであり、AIが動画、記事、音声記録を使って、サッカーの試合やパンの焼き方などの複雑なテーマについて学習する世界に近づくものだ。また、data2vecによって、コンピュータがラベル付きのデータをほとんど必要とせずにタスクをこなせる世界に近づくことを期待している」とBaevskiはThe Registerに対し述べている。
毎月70本のハイエンド記事が読み放題の有料購読が初月無料
アクシオンではクイックな情報は無料で公開していますが、より重要で死活的な情報は有料会員にのみ提供しております。有料会員は弊社オリジナルコンテンツに加え、ブルームバーグ、サイエンティフィック・アメリカン、ニューヨーク・タイムズから厳選された記事、月70本以上にアクセスができるようになります。現在、初月無料キャンペーン中。下の画像をクリックしてください。




