DeepMind、言語モデルの大規模化は引き続き効果的と判断
DeepMindはさまざまなサイズの変換言語モデルを学習させた。その結果、読解力、ファクトチェック、有害言語の識別など、モデルの規模を大きくすることで継続的にパフォーマンスが向上する分野が明らかになった。


Googleの検索エンジンの改良から翻訳アプリケーションの構築まで、「大規模マルチタスク言語モデル」(MMLU)と呼ばれる一群のシステムが使用されている。しかし、これらのプログラムには、性差別的な言葉や人種差別的な言葉を再生したり、論理的推論のテストに失敗するなど、深刻な問題もある。
これらの弱点は、データやコンピューティングパワー、そしてモデルの規模を増やすだけで改善できるのか、それとも、技術の限界に達しているのか、という大きな問いを投げかけている。
これは、Alphabetの人工知能(AI)研究所であるDeepMindが、12月初旬に発表した3つの研究論文が扱ったテーマでもある。同社の結論は、これらのシステムをさらにスケールアップすることで、多くの改善が得られるはずだというものだ。「この論文の重要な発見のひとつは、大規模な言語モデルの進歩と能力が依然として向上している」とDeepMindのリサーチサイエンティストで論文の著者の一人であるJack Raeはブリーフィングで記者団にこう語ったという。
過去20年間で、言語モデルは、言語の構造を暗黙的に捉えるニューラルネットワークへと進歩してきた。進歩は、規模とネットワークアーキテクチャの両方によってもたらされている。経験的に予測されたスケールメリットは、Open AIのGPT-3(2020年)によって実際に実現された。GPT-3は、3,000億トークンのテキストを学習した1,750億パラメータのTransformerで、多くの自然言語処理(NLP)タスクにおいて、前例のない生成品質とジェネラリスト能力を示した。
学習データ、モデルサイズ(パラメータで測定)、学習計算量の組み合わせをスケーリングして、学術的および産業的なベンチマークで性能が向上したモデルを得るという傾向がある。この傾向に沿った注目すべきモデルとしては、3億4,500万パラメータのBERT(Devlinら、2019年)が幅広いベンチマークの言語分類タスクで強力なパフォーマンスを発揮し、15億パラメータのGPT-2(Radfordら、2018年)および83億パラメータのMegatron(Shoeybiら、2019年)がゼロショット言語モデルのパフォーマンスを徐々に向上させ、110億パラメータのT5(Raffelら、2020a)が伝達学習を進め、いくつかのクローズドブックの質問応答タスクでパフォーマンスを発揮し、前述の1,750億パラメータのGPT-3が挙げられる。
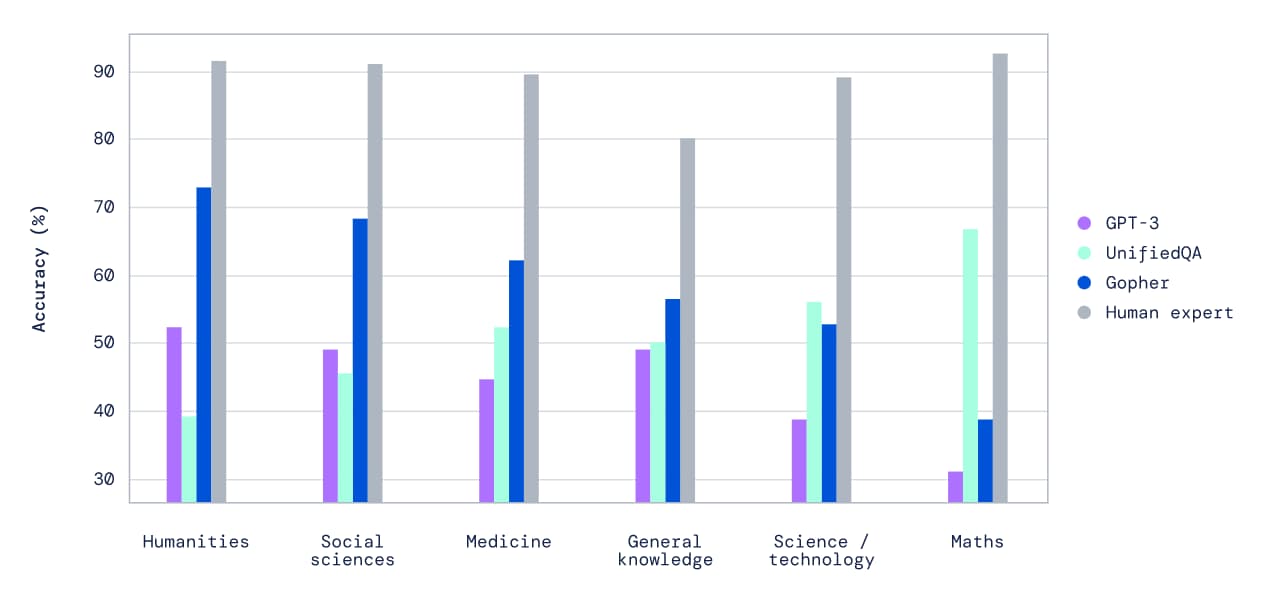
DeepMindは「Gopher」と名付けられた2,800億個のパラメータを持つ言語モデルを構築することで、このMMLUの能力を探っている。パラメータとは言語モデルの大きさや複雑さを表す簡単な尺度で、GopherはOpenAIのGPT-3(パラメータ数1,750億)よりは大きいが、MicrosoftとNVIDIAのMegatronモデル(パラメータ数5,300億)のような実験的なシステムには及ばないことを意味している。
DeepMindは4,400万パラメータから2,800億パラメータまでのさまざまなサイズの変換言語モデルを学習させた(最大のモデルをGopherと名付けた)。その結果、読解力、ファクトチェック、有害言語の識別など、モデルの規模を大きくすることで継続的にパフォーマンスが向上する分野が明らかになった。また、研究者らはモデルのサイズを大きくしても結果が大きく変わらない分野、例えば、論理的な推論や常識的なタスクなどの結果も明らかにした。
これらの結論を得るために、DeepMindの研究者たちは、152の言語タスクまたはベンチマークにおいて、さまざまなサイズの言語モデルを評価した。Gopherは、比較可能な結果を含むタスクの約81%において、現在の最先端の言語モデルよりも性能を向上させており、特にファクトチェックや一般的な知識などの知識集約型の領域で顕著であるようだ。
研究者らはGopherを定量的に評価するだけでなく、私たちはこのモデルを直接対話によって検証した。主な発見は、Gopherが(チャットのような)対話型のインタラクションに促されたとき、モデルが驚くべき一貫性を提供することがあるということだ。
「例えば、Gopherは細胞生物学について議論し、特に対話を微調整していないにもかかわらず、正しい引用を行うことができる。しかし、私たちの研究では、モデルのサイズを超えて存続するいくつかの失敗モードについても明らかにした。その中には、繰り返しの傾向、ステレオタイプのバイアスの反映、誤った情報の確信的な伝播などがある」と共著者の一人Jack Raeはブログに書いている。
言語モデルの巨大化傾向は続いており、DeepMindの研究は、この傾向を裏付けるものであり、MMLUの規模を拡大することで、感情分析や要約などをテストする最も一般的なベンチマークにおいて性能が向上することを示唆している。
また、DeepMindの研究者は別の論文で、MMLUの導入に伴う様々な潜在的弊害についても調査している。これには、システムが有害な言語を使用すること、誤った情報を共有する能力、スパムやプロパガンダを共有するような悪意のある目的に使用される可能性などが含まれている。これらの問題は、AI言語モデルがチャットボットや販売代理店など、より広く展開されるようになれば、ますます重要になるだろう。
最後の論文では、Gopherの基礎と倫理的・社会的リスクの分類法をもとに、学習のエネルギーコストを削減し、モデルの出力を学習コーパス内のソースに容易にトレースできる改良された言語モデルアーキテクチャRetrieval-Enhanced Transformer (RETRO)を提案している。
参考文献
- Scaling Language Models: Methods, Analysis & Insights from Training Gopher
- Ethical and social risks of harm from Language Models
- Sebastian Borgeaud et al. Improving language models by retrieving from trillions of tokens. arXiv:2112.04426cs.CL.
- Inioluwa Deborah Raji et al. AI and the Everything in the Whole Wide World Benchmark. arXiv:2111.15366 cs.LG



