FacebookのチャットボットBlenderが世界最高を主張
Facebookのリサーチエンジニア、スティーブン・ローラーらのチームは4月、新しいチャットボット「Blender」をオープンソース化した。Blenderは、バーチャルアシスタントの欠点の多くを解決するのに役立つだけでなく、AI研究の多くの原動力である「知性の複製」という大きな野望に向けた進展を示している。

要点
Facebookのリサーチエンジニア、スティーブン・ローラーらのチームは4月、新しいチャットボット「Blender」をオープンソース化した。Blenderは、バーチャルアシスタントの欠点の多くを解決するのに役立つだけでなく、AI研究の多くの原動力となっている「知性の複製」という大きな野望に向けた進展を示している、とローラーらは主張している。
モデルはGoogleのチャットボットの3.6倍のサイズ
Blenderの能力は、そのトレーニングデータの膨大なスケールから来ている。最初に15億件のRedditの一般公開されている会話でトレーニングを行い、対話の中で反応を生成するための基礎を与えた。その後、3つのスキルごとに追加のデータセットで微調整した。共感性を教えるために、ある種の感情を含む会話(例えば、ユーザーが「昇進したよ」と言った場合、「おめでとう!」と言うことができる)、知識を教えるために専門家との情報量の多い会話、個性を教えるためにペルソナの異なる人々の間の会話だ。このモデルは、1月に発表されたGoogleのチャットボット「Meena」の3.6倍の大きさだ。
今日の他の自然言語処理研究に共通していることだが、チャットボットを作成するための最初のステップは、大規模なトレーニングだ。チームは、大量の会話データを用いて大規模(最大94億)なトランスフォーマーニューラルネットワークの事前訓練を行った。抽出された会話の15億個のトレーニング例を含む、以前に公開されていたパブリックドメインの会話を使用した。我々のニューラルネットワークは単一のデバイスに収めるには大きすぎるため、カラム単位のモデル並列化などの技術を利用した。このように慎重にニューラルネットワークを構成することで、テラバイトサイズのデータセットにスケールするのに必要な高い効率を維持しながら、従来よりも大きなネットワークを扱うことが可能になった、と研究に関するFacebookのブログは説明している。
もちろん、大規模での学習は重要ですが、最高の会話主義者を作るために必要な唯一の成分ではない。大規模な公開訓練セットで平均的な会話を模倣するように学習したからといって、必ずしもエージェントが最高の会話家の特徴を学習するとは限らない。実際には、慎重に行われなければ、モデルに質の悪い、あるいは有害な行動を模倣させる可能性がある。研究チームはチームは最近、これらの望ましいスキルを訓練し評価するためのBlended Skill Talk (BST)と呼ばれる新しいタスクを導入した。
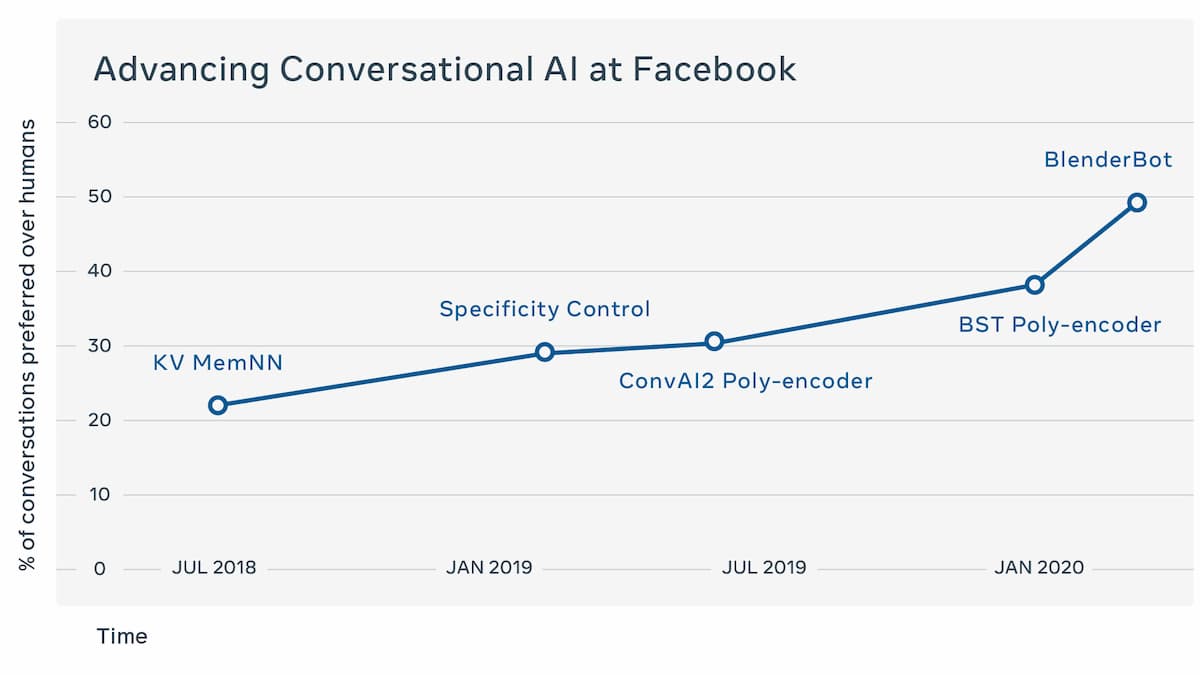
Googleは当時、Meenaが世界最高のチャットボットであると宣言していた。しかし、このFacebook独自のテストでは、人間の評価者の75%がBlenderの方がMeenaよりも魅力的であり、67%がBlenderの方が人間のように聞こえると判断した。また、チャットボットは人間の評価者の49%を騙して、その会話ログの方が実際の人間の会話ログよりも人間らしいと思わせていたが、つまり、両者の間にはあまり質的な違いはなかった。
ニューラルモデルの訓練は通常、モデルがどれだけうまく次の単語を予測して生成できるかを測定する「錯乱度」(perplexity)を最小化することによって行われる。しかし、会話エージェントが自分自身を繰り返したり、他の欠点を示さないようにするために、研究者は通常、モデルが訓練された後に、ビームサーチ、トークンサンプリング、およびn-gramブロッキングを含む多くの可能性のある生成戦略を使用している。彼らは、人間の評価者とより良い結果を得るためには、エージェントの発言の長さが重要であることを発見した。発言の長さが短すぎると反応が鈍くなり、興味のなさが伝わりますが、逆に長すぎると、チャットボットは人の話を聞かずに、何も言わないように見えてしまう。最近の研究では、サンプリングがビーム探索よりも優れているという結果が出ているが、このトレードオフを制御することで、探索のハイパーパラメータを慎重に選択することで強い結果が得られることを示している。
依然としてつきまとうチャットボットの課題
しかし、これらの印象的な結果にもかかわらず、Blenderのスキルはまだ人間のそれには遠く及ばない。これまでのところ、チームはこのチャットボットを14ターンの短い会話でしか評価していない。もしそれ以上の会話を続けていたら、すぐに意味がなくなってしまうのではないかと研究チームは推測している。
Blenderはまた、知識を「幻覚化」したり、事実をでっち上げたりする傾向がある。これは、知識のデータベースではなく、統計的な相関関係から最終的に文章を生成していることになる。その結果、例えば有名な有名人についての詳細で首尾一貫した説明を、完全に間違った情報を使ってまとめることができる。チームは、知識データベースをチャットボットの応答生成に組み込む実験を計画している。

オープンエンドのチャットボットシステムのもう一つの大きな課題は、有害なことや偏ったことを言わないようにすることだ。そのようなシステムは最終的にソーシャルメディア上で訓練されているため、インターネット上での暴言をそのまま口にしてしまうことになりかねない。これは2016年にマイクロソフトのチャットボットTayに起こった。チームは、微調整に使用した3つのデータセットから有害な言葉をフィルタリングするようクラウドワーカーに依頼することで、この問題に対処しようとしたが、Redditのデータセットはサイズが大きいため、同じことをしなかった。Redditを利用したことがある人なら、なぜそれが問題になるかは誰でも知っているだろう。
研究チームは、チャットボットの反応をダブルチェックできる「毒性言語分類器」など、より安全性の高いメカニズムを実験したいと考えている。しかし、研究者たちは、このアプローチが包括的なものではないことを認めている。「そうですね、それは素晴らしいですね」というような文章は問題ないように見えることもあるが、人種差別的なコメントへの反応のような微妙な文脈の中では、有害な意味を持つこともある。
参考文献
Stephen Roller. Recipes for building an open-domain chatbot. arXiv:2004.13637
Image by Manfred Steger from Pixabay



