GPT-3が1750億パラメータで構成される理由
OpenAIの研究者たちはこのほど、1750億個のパラメータで構成された最先端の言語モデル「GPT-3」の開発について説明した論文を発表した。これまでの研究では、より大きなモデルが解決策になる可能性があることが示されており、GPT-3はいくつかの不備を含みながらもそれを実証した。


要点
OpenAIの研究者たちはこのほど、1750億個のパラメータで構成された最先端の言語モデル「GPT-3」の開発について説明した論文を発表した。これまでの研究では、より大きなモデルが解決策になる可能性があることが示されており、GPT-3はいくつかの不備を含みながらもそれを実証した。
arXivに公開された論文では、30人以上の共著者からなるチームがモデルといくつかの実験について説明している。研究者たちの目標は、微調整をほとんど、あるいは全く行わずに、さまざまなタスクで高い性能を発揮するNLPシステムを作ることであり、これまでの研究では、より大きなモデルが解決策になる可能性があることが示されていた。
この仮説を検証するために、研究チームは以前のモデルであるGPT-2のパラメータを15億個からGPT-3では、1750億個に増やした。トレーニングのために、チームはCommon CrawlデータセットとWikipedia英語版を含むいくつかのデータセットを収集した。このモデルはいくつかのNLPベンチマークで評価され、「クローズドブック」の質問応答タスクで最先端の性能にマッチし、LAMBADA言語モデリングタスクで新記録を樹立した。
OpenAIは昨年、GPT-2について、「技術の悪意のある応用に関する懸念」のために、訓練されたモデルの15億パラメータのバージョンをリリースしないという決定をしたことで注目を集めた。
GPT-2は、Transformerアーキテクチャをベースにした多くの大規模NLPモデルの1つである。これらのモデルは、ウィキペディアのコンテンツのような大規模なテキストコーパス上で、自己教師付き学習を用いて事前に訓練されている。このシナリオでは、期待される出力と対になった入力を含むデータセットを使用する代わりに、モデルは「マスクされた」単語を含むテキストのシーケンスを与えられ、周囲の文脈に基づいてマスクされた単語を予測することを学習しなければならない。この事前学習の後、モデルは、質問応答などの特定のNLPタスクのために、ラベル付きのベンチマークデータセットで微調整される。
しかし、研究者たちは、特に大規模なデータセットで事前に訓練された大規模なモデルでは、微調整を行わなくても、事前に訓練されたモデルがかなり良いパフォーマンスを発揮することを発見している。今年の初め、OpenAIはTransformerモデルについて「スケーリングの法則」を提唱する論文を発表した。いくつかの異なるTransformerベースのモデルの性能データに基づいて、OpenAIは、モデルの性能(この場合、テストデータセットでの交差エントロピー誤差)は、モデルパラメータの数、データセットのサイズ、トレーニングに使用される計算量と力の法則的な関係があると結論づけた。これら3つの変数のいずれかを増やすことで、性能が向上する。
事前学習のために、チームはCommon Crawl、WebText、英語版Wikipedia、2つの書籍コーパスで構成されたデータセットを収集した。データの品質を向上させるために、研究者たちはCommon Crawlをフィルタリングして冗長性を除去した。Common Crawlはインターネットからスクレイプされているため、ベンチマーク評価のための実際のテストデータが含まれている可能性があり、これがトレーニングを「汚す」ことになる。チームはこの汚染を除去しようと試みた。しかし、彼らは「残念ながら、フィルタリングのバグにより、いくつかの重複を無視することができず、トレーニングのコストのためにモデルを再トレーニングすることができなかった」と認めている。
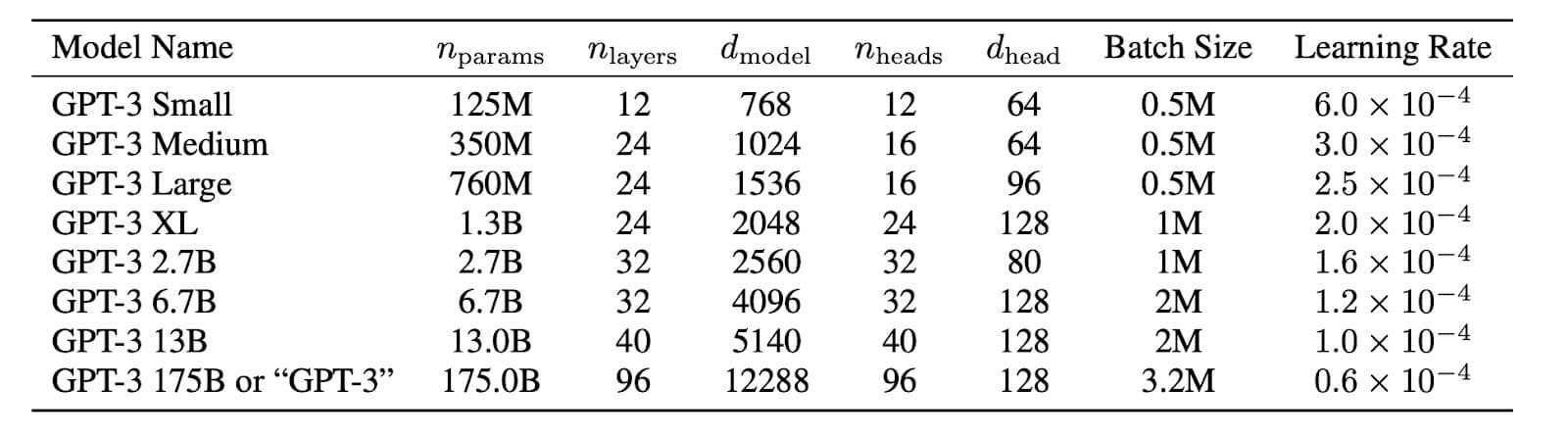
チームはこのデータを用いて、1億2500万個のパラメータから1750億個のパラメータまでの8つのバージョンのモデルを訓練した(下図)。これらのモデルは、幅広いカテゴリの数十種類のNLPベンチマークで評価され、多くの場合、最先端に近い、あるいはそれ以上の性能を示した。
ニュース記事生成タスクでモデルを評価するために、研究チームはAmazon Mechanical Turkを使用して人間の判定員を雇い、一対の記事のうちどちらが本物でどちらがGPT-3で生成されたものかを推測させた。人間が本物の記事を選んだのは52%であり、要するに、人間はコインをひっくり返しても本物の記事を選ぶことはできないということである。チームはまた、モデルの弱点についても議論した。例えば、テキスト合成については、「GPT-3のサンプルは、まだ時々、文書レベルで意味的に繰り返し、十分に長い文章の間に一貫性を失い始め、矛盾し、時折、非論理的な文章や段落を含む」としている。このモデルはまた、「チーズを冷蔵庫に入れたら溶けるか」というような「常識的な物理学」の質問にも対応できない。
NLP研究コミュニティの何人かのメンバーが、このモデルの大きさについてTwitterでコメントしている。Alchemy APIの創設者であるElliot Turnerは、最大のモデルを訓練するためのコストはほぼ1200万ドルになるだろうと推測している。ジョージア技術大学のMark Riedl教授は、モデルサイズとパフォーマンスの関連性についての説明を提案している。彼は「1つの仮説は、GPT-3は非常に多くのパラメータ(訓練されたトークンの数の半分)を持っているので、記憶ネットワークのように動作し始めているということです」と大胆な仮説を唱えている。
計算環境
「各モデルの正確なアーキテクチャパラメータは、GPU間のモデルレイアウトにおける計算効率と負荷分散に基づいて選択されている」とOpen AIは述べている。「すべてのモデルは、Microsoftが提供する高帯域幅クラスタの一部である「NVIDIA V100 GPU」上で訓練された」。
OpenAIは、すべてのAIモデルをディープニューラルネットワークのためのGPUアクセラレーションライブラリcuDNNで加速されたPyTorchディープラーニングフレームワーク上で訓練している。
7月初め、マイクロソフトとOpenAIは、同社専用に構築された新しいGPUアクセラレーティッドスーパーコンピュータを発表した。OpenAIのために開発されたスーパーコンピュータは、28万5000個以上のCPUコア、1万個以上のGPU、各GPUサーバーのための毎秒400ギガビットのネットワーク接続性を備えた単一システムとマイクロソフトのブログは説明している。
参考文献
- Tom B. Brown, et al. Language Models are Few-Shot Learners. arXiv 2005.14165.
- Jared Kaplan et al. Scaling Laws for Neural Language Models. arXiv 2001.08361.



