グラフコアの機械学習用コンピュータは1ペタフロップを達成したと主張
英国を拠点にAIワークロード用アクセラレータを開発しているGraphcore(グラフコア)は7月15日、同社のインテリジェンス・プロセッシング・ユニット(IPU)「M2000」の第2世代を[発表](https://www.graphcore.ai/posts/introducing-second-generation-ipu-systems-for-ai-at-scale)した。グラフコア社は、この新しいGC200チップにより、M2000は1ペタフロップの処理能力を達成できるようになると主張している。


英国を拠点にAIワークロード用アクセラレータを開発しているGraphcore(グラフコア)は今朝、同社のインテリジェンス・プロセッシング・ユニット(IPU)「M2000」の第2世代を発表した。グラフコア社は、この新しいGC200チップにより、M2000は1ペタフロップの処理能力を達成できるようになると主張している。
GC200のようなAIアクセラレータは、AIアプリケーション、特に人工ニューラルネットワーク、ディープラーニング、機械学習を高速化するために設計された特殊なハードウェアの一種である。これらは多くの場合、設計上マルチコアであり、低精度の演算やインメモリ・コンピューティングに重点を置いているが、これらはいずれも大規模なAIアルゴリズムの性能を向上させ、自然言語処理やコンピュータ・ビジョンなどの分野で最先端の結果をもたらすと信じられている。
M2000は、1つのダイに1,472個のプロセッサコア(8,832スレッド)と594億個のトランジスタを搭載した7ナノメートルGC200チップを4個搭載しており、グラフコア社の既存のIPU製品の8倍以上の処理性能を実現している。ベンチマークテストでは、4台のGC200 M2000は、8,800万個のパラメータを持つ画像分類モデル(GoogleのEfficientNet B4)を実行し、Nvidia V100ベースのシステムの32倍以上、最新の7ナノメートルグラフィックスカードの16倍以上の速度を実現したとしている。
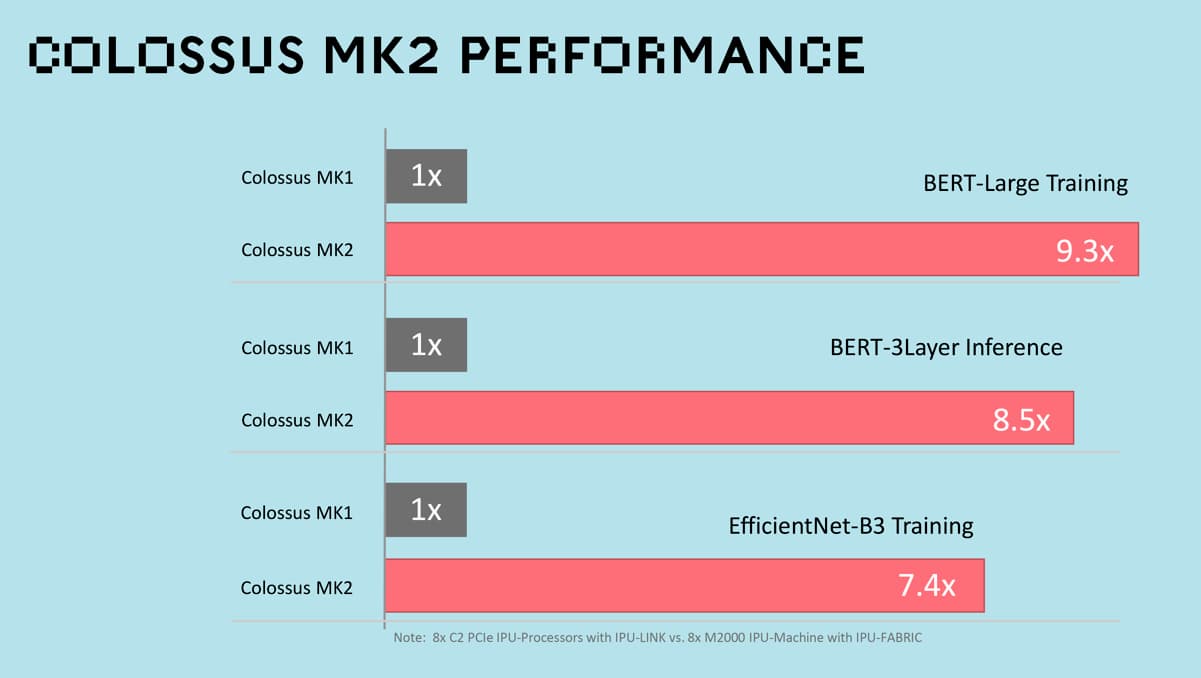
第一世代のグラフコア IPU製品と比較すると、パフォーマンスが8倍も向上している(下図)。
GC200とM2000は、AIと機械学習のために最適化されたグラフツールチェインであるグラフコアの特注のPoplarと連携するように設計されている。GC200とM2000は、GoogleのTensorFlowフレームワークとOpen Neural Network Exchange(交換可能なAIモデルのためのエコシステム)と統合されており、後者の場合は完全なトレーニングランタイムを提供する。FacebookのPyTorchとの予備的な互換性は2019年第4四半期に到着し、完全な機能のサポートは2020年初頭に続く。Poplarの最新バージョンは、メモリとデータアクセスに関してGC200のユニークなハードウェアとアーキテクチャ設計を活用することを目的とした交換メモリ管理機能を導入した。
「M2000の設計により、最大64,000 IPUのデータセンター規模のシステムをIPU-POD™構成で構築することができ、16 ExaFlopsの計算を実現する。M2000は、最も過酷な機械学習トレーニングや大規模な展開ワークロードにも対応できる」とCEOのナイジェル・トゥーンは声明で説明している。
既存のCPUサーバの1台に直接接続したM2000ボックス1台から始めることも、この1台のサーバに接続したIPU-Machine M2000を最大8台まで追加することもできる。大規模なシステムには、16台のM2000を標準の19インチ・ラックに組み込んだラックスケールのIPU-POD64を使用し、これらのラックをスケールアウトして、データセンター・スケールの機械学習のための計算を提供することができる。
M2000の心臓部にあるGC200は、TSMCの最新の7nmプロセス技術を用いて開発され、単一の823sqmmダイに594億個以上のトランジスタを搭載しており、これまでに製造された中で最も複雑なプロセッサとなっている。
GC200は、1,472個のIPUコアを統合し、8,832個の並列計算スレッドを実行することができる。各IPUプロセッサコアは、グラフコアが開発したAI-Floatと呼ばれる一連の新しい浮動小数点技術によって性能を向上させている。GC200は、1台で最大250TFLOPS、つまり1秒間に1兆回の浮動小数点演算を実現する。深層学習の計算のエネルギーとパフォーマンスのためにチューニングすることで、GC200を4つ積んだ1つのM2000で1ペタフロップのAI計算を実行することができる。

Graphcore
サイモン・ノウルズとナイジェル・トゥーンによって2016年に設立されたグラフコアは、ロバート・ボッシュ・ベンチャーキャピタル、サムスン、デル・テクノロジーズ・キャピタル、BMW、マイクロソフト、Armの共同創業者ヘルマン・ハウザー、そしてAIの著名人であるディープマインドの共同創業者デミス・ハサビスから、これまでに4億5,000万ドル以上の資金を19億5,000万ドルの評価額で調達してきた。その最初の商用製品は、2018年に発売された16ナノメートルのPCI Expressカード「C2」で、2019年11月にMicrosoft Azure上で発売されたのはこのパッケージだ(マイクロソフトは社内でもグラフコアの製品を様々なAIの取り組みに使用している)。
今年の初め、グラフコアはDellとの提携によるDSS8440 IPUサーバーの提供を発表し、クラウド・プロバイダーのCirrascaleが提供するIPUベースのマネージド・サービスであるCirrascale IPU-Bare Metal Cloudを開始した。さらに最近、グラフコアは、Citadel Securities、Carmot Capital、オックスフォード大学、J.P. Morgan、ローレンス・バークレー国立研究所、欧州の検索エンジン会社Qwantなどの初期の顧客の一部を明らかにし、IPU上でアプリを構築して実行するためのライブラリをGitHub上でオープンソース化した。
グラフコアには勢いがあるかもしれないが、2025年までに911億8000万ドルに達すると予想される市場では競争相手がいる。3月には、エッジでのAI推論を高速化するハードウェアを開発する新興企業Hailoがベンチャーキャピタルから6000万ドルを調達した。カリフォルニアを拠点とするMythicは、カスタム独自のインメモリアーキテクチャを開発するために8520万ドルを調達した。マウンテンビューに本拠を置くFlex Logixは4月に、既存のシリコンの最大10倍のスループットを実現すると主張する推論コプロセッサを発売した。そして昨年11月には、Esperanto Technologies社が7ナノメートルのAIチップ技術のために5,800万ドルを確保した。
グラフコアのシステムを使用している企業、組織、研究機関の数は急速に増加しており、Microsoft、Oxford Nanopore、EspresoMedia、オックスフォード大学、Citadel、Qwantなどが含まれている。
グラフコアの技術は、J.P.モルガンでも評価されており、そのソリューションが銀行のAI、特に自然言語処理と音声認識の進歩を加速させることができるかどうかを検証している。
Photo: IPU-Machine M2000 by Graphcore.



