新しいトレーニング技術でエッジデバイス上の言語モデルを高速化
MITコンピュータサイエンス・人工知能研究所(CSAIL)とMIT-IBMワトソンAIラボの研究者はこのほど、GoogleのTransformerアーキテクチャを組み込んだAIモデルトレーニング技術であるHardware-Aware Transformers(HAT)を提案しました。


MITコンピュータサイエンス・人工知能研究所(CSAIL)とMIT-IBMワトソンAIラボの研究者はこのほど、GoogleのTransformerアーキテクチャを組み込んだAIモデルトレーニング技術であるHardware-Aware Transformers(HAT)を提案しました。彼らは、HATはRaspberry Pi 4のようなデバイス上で、ベースラインと比較してモデルサイズを3.7倍に縮小しながら、推論速度を3倍に向上させることができると主張しています。
GoogleのTransformerは、その最先端の性能により、自然言語処理(そして一部のコンピュータビジョン)のタスクに広く使用されています。それにもかかわらず、Transformerはその計算コストのためにエッジデバイスへの展開が困難なままです。Raspberry Piでは、たった30語の文を翻訳するには13ギガフロップス(1秒間に10億回の浮動小数点演算)が必要で、20秒かかります。これでは、言語AIをモバイルアプリやサービスに統合する開発者や企業にとって、アーキテクチャの有用性が明らかに制限されてしまいます。
研究者のソリューションは、AIモデル設計を自動化するための手法であるニューラル・アーキテクチャ・サーチ(NAS)を採用しています。HATは、多数のサブトランスフォーマーを含むトランスフォーマー「スーパーネット」(SuperTransformer)を最初に訓練することで、エッジデバイスに最適化されたトランスフォーマーの探索を実行します。次に、これらのサブトランスは同時に訓練され、1つのトランスの性能が、ゼロから訓練された異なるアーキテクチャの相対的な性能の近似値を提供するようになります。最後のステップでは、HATは、ハードウェアのレイテンシ制約を与えられた場合に、最適なサブトランスフォーマを見つけるための進化的探索を行います。
HATの効率をテストするために、16万から4,300万組の訓練文からなる4つの機械翻訳タスクで実験を行った。各モデルについて、待ち時間を300回測定し、最も速いものと遅いものの10%を除去した後、残りの80%の平均を取り、Raspberry Pi 4、Intel Xeon E2-2640、Nvidia Titan XPグラフィックスカードで実行しました。
研究チームによると、HATによって特定されたモデルは、従来から訓練されたTransformerよりもすべてのハードウェアで低いレイテンシを達成しただけでなく、1台のNvidia V100グラフィックスカードで184時間から200時間の訓練を行った後、一般的なBLEU言語ベンチマークで高いスコアを獲得しました。Googleが最近提案したEvolved Transformerと比較すると、モデルは3.6倍も小さく、計算コストは12,041倍も低く、パフォーマンスの低下はありませんでした。
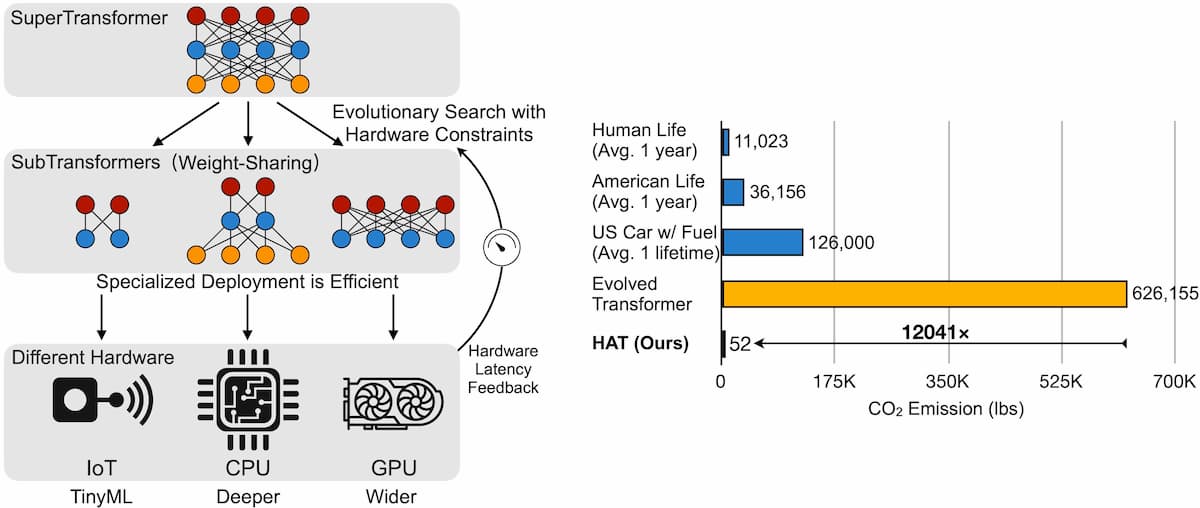
「リソースに制約のあるハードウェアプラットフォーム上で低レイテンシ推論を可能にするために、我々はニューラルアーキテクチャ探索を用いてHATを設計することを提案します」と共著者は書いています。HATはGitHub上でオープンソースとして公開されています。「我々は、HATが実世界のアプリケーションのための効率的なTransformer導入の道を開くことを期待しています」
参考文献
- David R.So et al. The Evolved Transformer. arXiv:1901.11117.
- Hanurui Wang et al. HAT: Hardware-Aware Transformers for Efficient Natural Language Processing. arXiv:2005.14187. [Submitted on 28 May 2020]
Photo by Harrison Broadbent on Unsplash



