GPT-2がピクセルで学習し表現する画像生成器に変身した
OpenAIはフィクションの画像を生成しているAIの開発に成功した。GPT-2を自然言語の代わりにピクセルで学習させることで、モデルは半分の画像を受け入れ、それをどのように完成させるかを予測することができる。iGPTと名付けられた新しいモデルは、視覚世界の2次元構造を把握することができる。


要約
OpenAIはフィクションの画像を生成しているAIの開発に成功した。GPT-2を自然言語の代わりにピクセルで学習させることで、モデルは半分の画像を受け入れ、それをどのように完成させるかを予測することができる。iGPTと名付けられた新しいモデルは、視覚世界の2次元構造を把握することができる。
「視覚世界の2次元構造を把握する」
2019年2月、サンフランシスコに拠点を置く研究機関OpenAIは、そのAIシステムが説得力のある英文を書くことができるようになったと発表した。文章や段落の冒頭をGPT-2と呼ばれるものに送り込むことで、ほぼ人間のような一貫性を持ったエッセイのように長く思考を続けることができるようになった。
いま、OpenAIの研究室では、同じアルゴリズムに画像の一部を入力した場合に何が起こるかを調べている。機械学習国際会議ICMLで最優秀論文賞に選ばれた研究結果は、多くの研究者の注目を集めている。
GPT-2は強力な予測エンジンだ。GPT-2は、インターネットの片隅から切り取られた何十億もの単語、文章、段落の例を見ることで、英語の構造を把握することを学んだ。その構造を利用して、単語の出現順序を統計的に予測することで、単語を操作して新しい文章を作ることができる。
そこでOpenAIの研究者たちは、単語をピクセルに置き換えて、ディープラーニングのための最も一般的な画像バンクであるImageNetの画像で同じアルゴリズムを訓練することにした。このアルゴリズムは一次元データ(テキストの文字列)を扱うように設計されているため、画像を1つのピクセルのシーケンスに展開した。その結果、iGPTと名付けられた新しいモデルは、視覚世界の2次元構造を把握することができることがわかった。画像の前半のピクセルのシーケンスが与えられれば、人間が感覚的に考えるような方法で後半のピクセルを予測することができる。
iGPTは、低解像度のImageNet上でラベルなしで学習したにもかかわらず、GPT-2スケールのモデルが線形プロービング、微調整、低データ分類によって測定されるように、強力な画像表現を学習することがわかった。
以下にいくつかの例を示す。一番左の列が入力、一番右の列がオリジナル、真ん中の列がiGPTの予測補完だ。
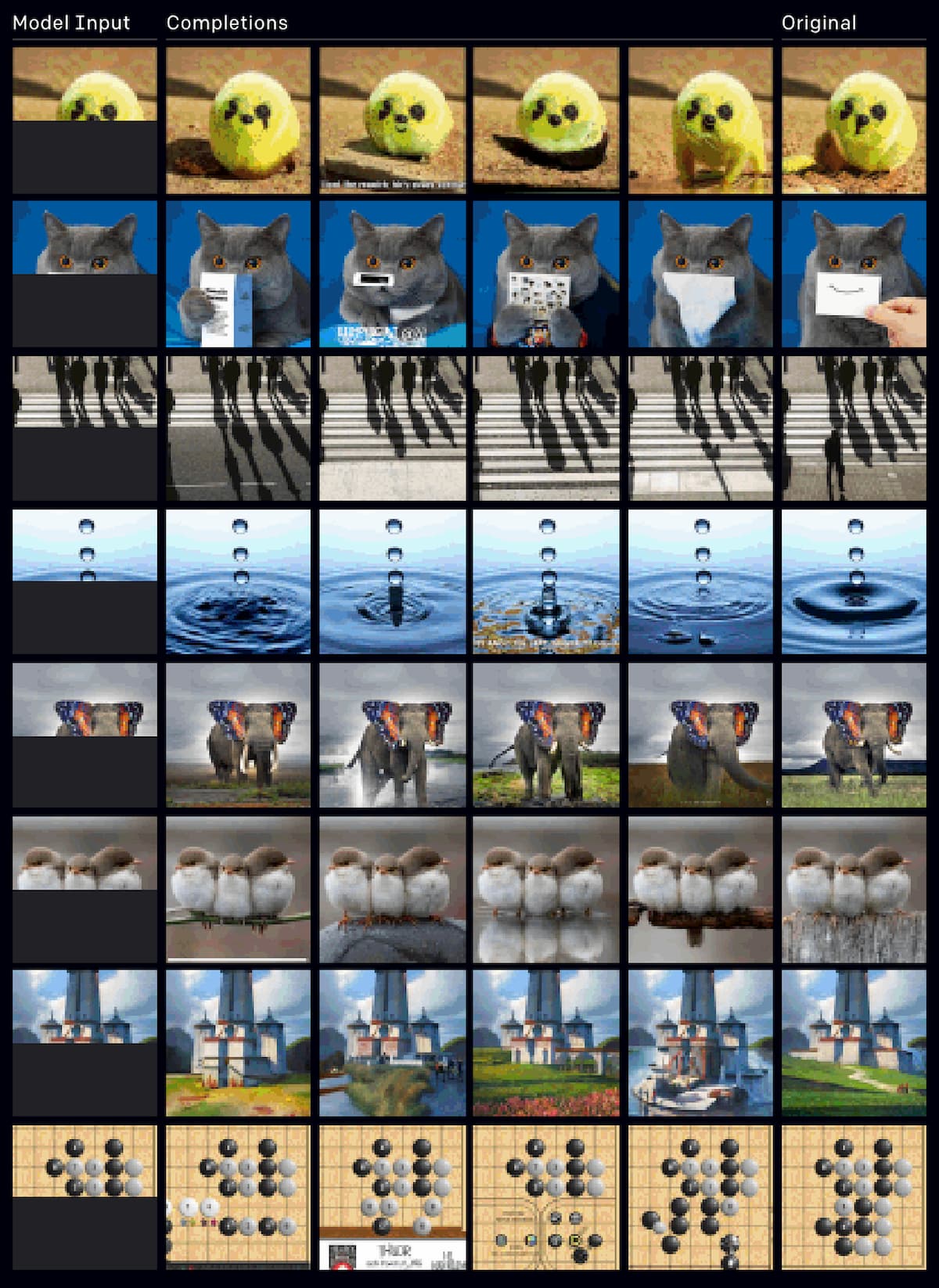
この結果は驚くほど印象的であり、コンピュータビジョンシステムの開発において、ラベル付けされていないデータを用いて学習する教師なし学習を利用するという新たな道筋を示している。2000年代半ばの初期のコンピュータビジョンシステムでは、以前にもこのような手法が試みられていたが、ラベル付きデータを使用する教師付き学習の方がはるかに成功していることが証明されたため、そのような手法は人気を失いた。しかし、教師なし学習の利点は、AIシステムが人間のフィルターなしで世界を学習できることと、データにラベルを付けるという手作業を大幅に削減できることだ。
iGPTがGPT-2と同じアルゴリズムを使っていることからも、その適応性の高さが伺える。これは、より汎用化可能な機械知能を実現するというOpenAIの究極の野望と一致している。
同時に、この方法はディープフェイク画像を作成するための新しい方法を提示している。過去にディープフェイクを作成するために使用されたアルゴリズムの中で最も一般的なカテゴリである生成的な敵対的ネットワークは、高度にキュレーションされたデータ上で訓練されなければならない。対照的に、iGPTは、何百万、何十億もの例題にわたって視覚世界の構造を十分に学習し、その中に存在する可能性のある画像を吐き出す。モデルの学習にはまだ計算コストがかかり、そのアクセスには当然のことながら障壁となるが、それも長くは続かないかもしれない。
参考文献
Mark Chen · Alec Radford · Rewon Child · Jeffrey K Wu · Heewoo Jun · David Luan · Ilya Sutskever. Generative Pretraining From Pixels.
Image via OpenAI



