「稀な事故」を含んだ自律走行シミュレーション
MITで開発された自律走行車(AV)を訓練するためのシミュレーションシステムは、実際の道路を走行する前に、車が最悪のシナリオに直面した場合に備えるための学習を支援する。その学習内容は新しい道路や新規の複雑で衝突に近い状況など、これまでに遭遇したことのないシナリオを含んでいる。


マサチューセッツ工科大学(MIT)で開発された自律走行車(AV)を訓練するためのシミュレーションシステムは、実際の道路を走行する前に、車が最悪のシナリオに直面した場合に備えるための学習を支援する。 MITの研究者らは学習した方策がフルスケールの自律走行車に応用可能なことを確認し、その学習内容は新しい道路や新規の複雑で衝突に近い状況など、これまでに遭遇したことのないシナリオを含んでいる。
AVの制御システム、つまり「コントローラ」は、人間の運転者からの走行軌跡の実世界のデータセットに大きく依存している。これらのデータから、さまざまな状況で安全な操舵制御をエミュレートする方法を学習する。しかし、衝突しそうになったり、道路から外れたり、他の車線に追いやられたりするような危険な「コーナーケース」の実データはほとんどない。
「シミュレーションエンジン」と呼ばれるコンピュータプログラムの中には、詳細な仮想道路をレンダリングしてこれらの状況を模倣し、制御者の対応力の訓練に役立てることを目的としたものがある。しかし、シミュレーションで学習した制御が、実物大の自動車で現実に適用されることはこれまで示されていなかった。
筆頭著者のMITのコンピュータ科学・人工知能研究所(CSAIL)の博士課程の学生Alexander Aminiらは、「Virtual Image Synthesis and Transformation for Autonomy (VISTA)」と呼ばれるフォトリアリスティックなシミュレータでこの問題に取り組んだ。VISTAは、道路を走行している人間が撮影した小さなデータセットのみを使用して、車両が現実世界で取ることができる軌道から、実質的に無限の数の新しい視点を合成する。コントローラーは、衝突せずに移動した距離に応じて報酬を得るので、安全に目的地に到達する方法を自分で学習しなければならない。そうすることで、車線間を旋回した後に制御を回復したり、衝突に近い状況から回復したりすることも含めて、どのような状況に遭遇しても安全にナビゲートできるように学習する。
テストでは、シミュレータ「VISTA」で訓練されたコントローラーが、実物大のドライバーレスカーに安全に搭載され、これまで見たこともないような道路をナビゲートすることができた。また、様々な事故一歩手前の状況を模擬したオフロードの方向に車を配置し、数秒以内に安全な走行軌道に戻すことにも成功した。このシステムを説明した論文はIEEE Robotics and Automation Lettersに掲載され、5月に開催されるICRA会議で発表された。この研究は、Toyota Research Instituteとの共同研究で行われた。
人間が走行中に経験しないようなエッジケースでデータを収集するのは大変だが、 Aminiらが提案するシミュレーション手法では、制御システムはこのような状況を経験し、そこから回復するために自ら学習し、現実世界の車両に展開された場合でもロバストな状態を維持することができる、と論文は主張している。
データ駆動型シミュレーション
歴史的に、自律走行車の訓練やテストのためのシミュレーション・エンジンの構築は、ほとんどが手作業で行われてきた。企業や大学では、アーティストやエンジニアで構成されたチームが、正確な道路標識や車線、木の葉の詳細な描写など、仮想環境のスケッチを行うことがよくある。エンジンの中には、複雑な数学モデルに基づいて、車と環境との相互作用の物理学を組み込むものもある。
しかし、複雑な現実世界の環境では、考慮すべきことが非常に多くなるため、すべてをシミュレーターに組み込むことは事実上不可能だ。そのため、通常、コントローラがシミュレーションで学習したことと、実際の世界でどのように動作するかの間にミスマッチが生じる。
その代わりに、MITの研究者たちは、「データ駆動型」シミュレーションエンジンを開発した。このエンジンは、実際のデータから、道路の外観と一致する新しい軌道を合成し、シーン内のすべてのオブジェクトの距離と動きも合成する。
まず、人間がいくつかの道路を走行している映像データを収集し、それをエンジンに入力する。各フレームごとに、エンジンはすべてのピクセルを一種の3D点群に投影する。そして、その世界の中に仮想車両を配置する。車両が操舵指令を出すと、エンジンは操舵カーブと車両の向きと速度に基づいて、点群を介して新しい軌跡を合成する。
そして、エンジンはこの新しい軌跡を使って、フォトリアリスティックなシーンをレンダリングする。そのために、画像処理タスクで一般的に使用される畳み込みニューラルネットワークを使用して、コントローラの視点からのオブジェクトの距離に関する情報を含む奥行きマップを推定する。次に、この深度マップと、3Dシーン内でのカメラの向きを推定する技術を組み合わせる。これにより、バーチャルシミュレータ内のすべてのものから車両の位置と相対的な距離をピンポイントで特定することができる。
その情報をもとに、元のピクセルの向きを変えて、車の新しい視点からの世界を3Dで再現する。また、ピクセルの動きを追跡することで、シーン内の車や人、その他の動く物体の動きを捉えることができる。
このプロセスは、環境をナビゲートしているバーチャルエージェントと、現実世界で環境を運転している人間の再生バージョンの両方について繰り返される。共通の座標フレームで、VISTAは2つの状態ベクトルを差し引くことで相対的な変位を計算する。このようにして、VISTAは、常に最も近い人間の状態を基準とした仮想エージェントの横方向、縦方向、角度の摂動の推定値を維持している。
VISTAは、環境全体や都市の3D再構成を保存して運用する必要がないため、スケーラブルだ、と論文は主張している。その代わりに、仮想エージェントの現在の状態に最も近い状態で収集された観測のみを考慮する。数千kmに及ぶ実道路網上で仮想エージェントのシミュレーションを行うには、数百ギガバイトの単眼カメラデータが必要となる。
下図の(C)は、ビュー合成のサンプルを示している。最も近い単眼画像から、ステレオカメラの自己監視を利用した畳み込みニューラルネットワークを用いて深度マップを推定する。推定された深度マップとカメラの内部構造を使用して、我々のアルゴリズムはセンサーフレームから3Dワールドフレームに投影する。仮想エージェントと人間の間の相対的な変換を考慮するために座標変換を適用した後、アルゴリズムは車両のセンサーフレームに投影し、その結果を次の観測としてエージェントに返す。
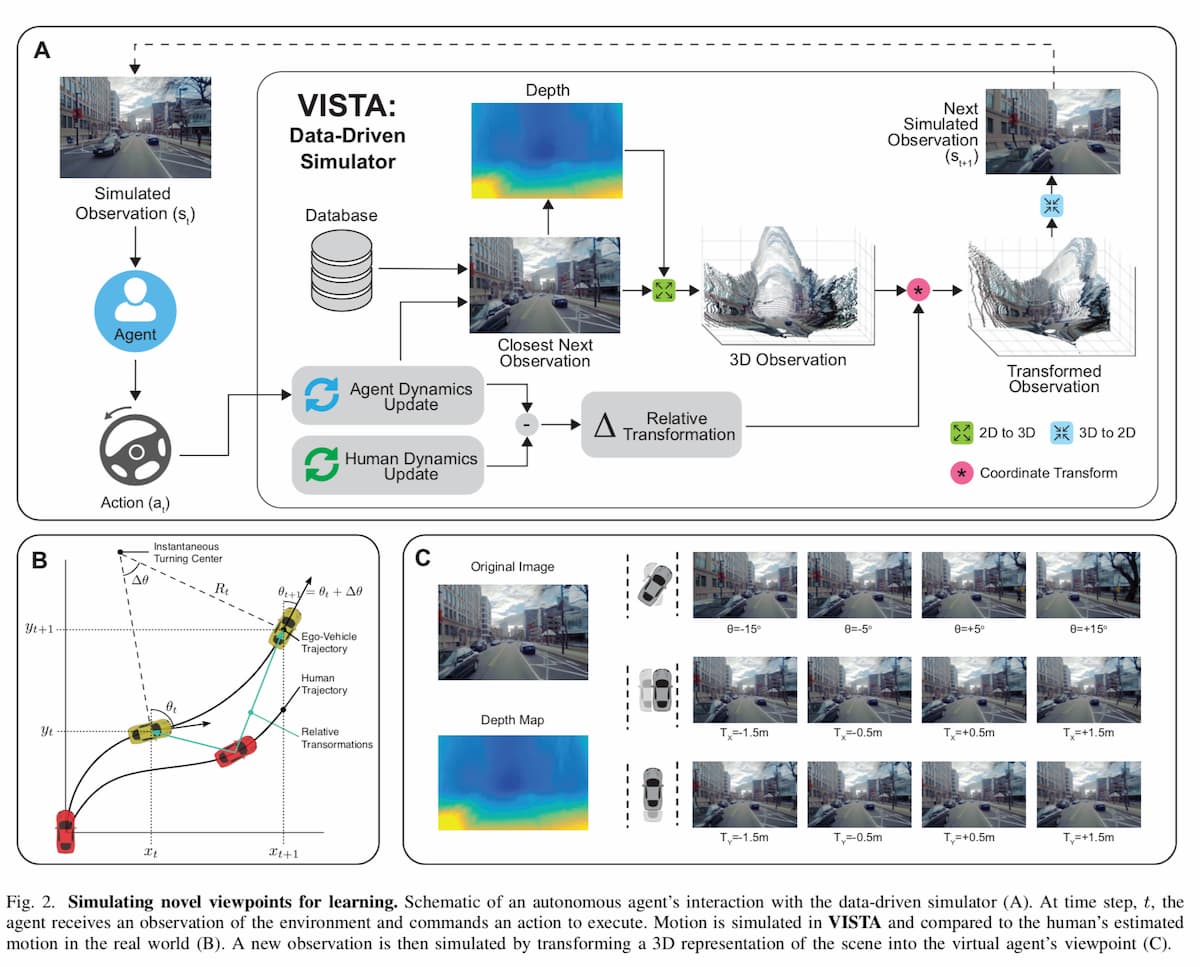
VISTA環境内での仮想エージェントの動きをある程度許容するために、収集したデータよりも小さな視野に画像を投影する。欠落したピクセルはバイリニアサンプラーを使用してペイントされるが、よりフォトリアリスティックでデータドリブンなアプローチも使用可能だ。VISTAは、道路に沿った横方向と縦方向の移動(±1.5m)だけでなく、エージェントの異なる局所的な回転(±15◦)をシミュレートすることができる。車線内の車両の横方向の自由空間は通常1m未満であるため、VISTAは車線安定運転の範囲を超えたシミュレーションを行うことができるという。
ゼロからの強化学習
従来、研究者たちは、人間が定義した運転ルールに従うか、人間の運転を真似して自律走行車を訓練してきた。しかし、研究者たちは、「エンド・ツー・エンド」のフレームワークの下で、コントローラをゼロから完全に学習させている。つまり、道路の視覚観測などの生のセンサーデータのみを入力として取り込み、そのデータから出力で操舵コマンドを予測する。
このためには、「強化学習」(RL)と呼ばれる報酬設計を伴う機械学習技術が必要で、車がエラーを起こすたびにフィードバック信号を提供する。研究者のシミュレーションエンジンでは、コントローラは、運転の仕方やレーンマーカーが何であるか、他の車がどのように見えるかについて何も知らない状態から始め、ランダムな操舵角を実行し始める。衝突したときだけフィードバック信号が送られてくる。その時点で、新しいシミュレートされた場所にテレポートされ、再び衝突しないように、より良い舵角のセットを実行しなければならない。10~15時間のトレーニングを経て、これらのまばらなフィードバック信号を使って、衝突せずに長距離を走行できるように学習する。
シミュレーションで1万キロの走行に成功した後、著者らは、学習したコントローラを実物大の自律走行車に適用した。研究者らは、シミュレーションでエンドツーエンドの強化学習を用いて学習したコントローラが、実物大の自律走行車に適用されることに成功したのは、これが初めてだとチームは主張している。
研究者たちは、次のステップとして、夜間と昼間、晴天と雨天など、1つの走行軌跡からあらゆるタイプの道路状況をシミュレートしたいと考えている。また、道路上の他の車とのより複雑な相互作用もシミュレートしたいと考えている。
参考文献
Alexander Amini, et al.Learning Robust Control Policies for End-to-End Autonomous Driving From Data-Driven Simulation. IEEE Robotics and Automation Letters ( Volume: 5, Issue: 2, April 2020) DOI: 10.1109/LRA.2020.2966414
Gif via http://www.mit.edu/~amini/vista/
Special thanks to supporters !
Shogo Otani, 林祐輔, 鈴木卓也, Mayumi Nakamura, Kinoco, Masatoshi Yokota, Yohei Onishi, Tomochika Hara, 秋元 善次, Satoshi Takeda, Ken Manabe, Yasuhiro Hatabe.
コーヒー代支援 / サポーター加入
Axionは吉田が2年無給で、1年が高校生アルバイトの賃金で進めている「慈善活動」です。有料購読型アプリへと成長するプランがあります。コーヒー代のご支援をお願いします。個人で投資を検討の方はTwitter(@taxiyoshida)までご連絡ください。プロジェクトの詳細は以下を参照くださいませ。




