Uberの機械学習基盤Michelangelo (ミケランジェロ)
Uberの機械学習基盤MichelangeloはUberのすべてのトランザクションデータとログデータを保存するデータレイクであり、同社の機械学習、データサイエンスのためのデータソースとその加工を一手に支えており、同社が配車マッチング、ダイナミックプライシング、食品配達マッチング等の製品を投入するのを助けている。


要点
Uberの機械学習基盤MichelangeloはUberのすべてのトランザクションデータとログデータを保存するデータレイクであり、同社の機械学習、データサイエンスのためのデータソースとその加工を一手に支えており、同社が配車マッチング、ダイナミックプライシング、食品配達マッチング等の製品を投入するのを助けている。
Uberのエンジニアリング部門は人工知能(AI)と機械学習(ML)への投資を増やしていることで知られている。Uberでは、この分野への貢献として、機械学習を民主化し、AIをビジネスのニーズに合わせてスケーリングすることを、乗車をリクエストするのと同じくらい簡単にできるようにする、社内のML-as-a-serviceプラットフォームであるMichelangelo(ミケランジェロ)を構築している。
Michelangeloは、社内チームがUberの規模で機械学習ソリューションをシームレスに構築、展開、運用できるようにしている。データの管理、モデルのトレーニング、評価、デプロイ、予測の作成、予測の監視といったエンドツーエンドのMLワークフローをカバーするように設計されています。また、従来のMLモデル、時系列予測、ディープラーニングにも対応する。
Michelangeloは、2016年ごろからUberで本番のユースケースに対応しており、何十ものチームがモデルを構築して展開しており、エンジニアやデータサイエンティストにとって機械学習のためのデファクトシステムとなっている。実際、このシステムは複数のUberデータセンターに展開され、専用のハードウェアを活用し、同社で最も負荷の高いオンラインサービスの予測を行っている。
この記事では、Michelangeloを紹介し、製品のユースケースを議論し、この強力な新しいML-as-a-serviceシステムのワークフローを説明する。
ミケランジェロの背景にある動機
ミケランジェロの前は、Uberでの機械学習モデルの構築と展開において、事業の規模や規模に関連した多くの課題に直面していた、とUberのJeremy Hermann Mike Del Balsoは同社のブログ記事で説明している。データサイエンティストは予測モデルを作成するために様々なツール(R、scikit-learn、カスタムアルゴリズムなど)を使用していたが、個別のエンジニアリングチームは、これらのモデルを本番で使用するために、特注のシステムを構築していたた。その結果、UberにおけるMLの効果は、数人のデータサイエンティストやエンジニアが、ほとんどがオープンソースのツールを使って短期間で構築できるものに限られていた。
具体的には、学習データや予測データを大規模に作成して管理するための、信頼性が高く、均一で、再現性のあるパイプラインを構築するためのシステムがなかった。ミケランジェロが登場する以前は、データサイエンティストのデスクトップマシンに収まるサイズ以上のモデルを訓練することはできず、訓練実験の結果を保存する標準的な場所も、ある実験と別の実験を簡単に比較する方法もなかった。最も重要なことは、モデルを本番環境にデプロイするための確立された道筋がなかったことだ。ほとんどの場合、関連するエンジニアリング・チームは、プロジェクトに特化したカスタム・サービング・コンテナを作成しなければならなかった。
Michelangeloは、エンドツーエンドのシステムでチーム間のワークフローやツールを標準化することで、これらのギャップに対応するように設計されている。Uberのエンジニアリングチームの目標は、これらの当面の問題を解決するだけでなく、ビジネスとともに成長していくシステムを作ることだった。
2015年半ばにMichelangeloの構築を開始したとき、Uberはまず、スケーラブルなモデルトレーニングと本番のサービングコンテナへのデプロイに関する課題に取り組むことから始めた。その後、機能パイプラインを管理・共有するためのより良いシステムの構築に注力した。最近では、開発者の生産性を向上させるために、アイデアから最初の本番モデルへのパスと、それに続く高速なイタレーションを高速化することに焦点を当てている。
ユースケース: UberEATSの推定配信時間モデル
UberEATSはミケランジェロ上で動作するいくつかのモデルを持っており、食事の配達時間の予測、検索ランキング、検索オートコンプリート、レストランランキングをカバーしている。配達時間モデルでは、注文が出される前に食事の準備と配達にどれくらいの時間がかかるかを予測し、配達プロセスの各段階で再度予測する。
食事の配達予定時間(ETD)を予測するのは簡単ではない。UberEATSの顧客が注文をすると、注文はレストランに送られて処理される。その後、レストランは注文を確認し、食事の準備をする必要があるが、注文の複雑さやレストランの忙しさに応じて時間がかかる。食事の準備が整いそうになると、Uberの配達員が食事を受け取るために派遣される。その後、デリバリー・パートナーはレストランに到着し、駐車場を見つけ、中に入って食事を取りに行き、車に戻り、顧客の場所まで車で移動し(ルート、交通量、その他の要因に依存します)、駐車場を見つけ、顧客のドアまで歩いて配達を完了させる必要がある。目標は、この複雑な多段階のプロセスの合計時間を予測し、プロセスの各段階で配達までの時間を再計算することだ。
Michelangeloプラットフォーム上で、UberEATSのデータサイエンティストは、このエンドツーエンドの配送時間を予測するために、勾配ブースト決定木回帰モデルを使用している。モデルの特徴には、リクエストからの情報(時間帯、配達場所など)、過去の特徴(過去7日間の平均的な食事準備時間など)、ほぼリアルタイムで計算された特徴(過去1時間の平均的な食事準備時間など)が含まれている。モデルは、Uberのデータセンター全体でミケランジェロ・モデル・サービング・コンテナに配備され、UberEATSマイクロサービスによるネットワーク・リクエストを介して呼び出される。これらの予測は、レストランで注文する前や、食事が準備されて配送される際に、UberEATSの顧客に表示される。
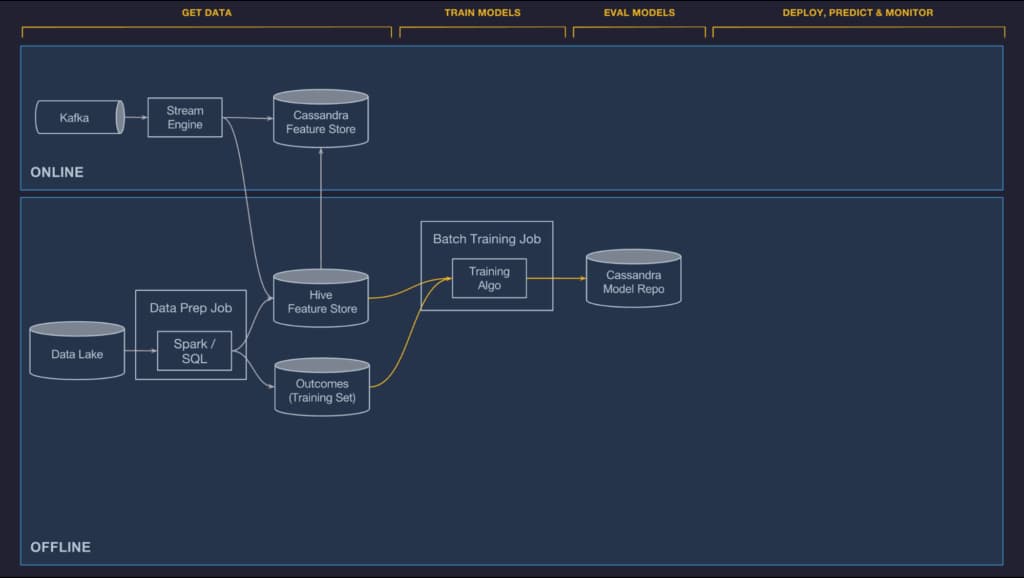
システムアーキテクチャ
Michelangeloは、オープンソースのシステムと社内で構築されたコンポーネントのミックスで構成されている。主なオープンソースのコンポーネントは、HDFS、Spark、Samza、Cassandra、MLLib、XGBoost、TensorFlowだ。一般的に、可能な限り成熟したオープンソースのオプションを使用することを好み、必要に応じてフォーク、カスタマイズ、貢献を行うが、オープンソースのソリューションが我々のユースケースにとって理想的でない場合は、自分たちでシステムを構築することもある。
「MichelangeloはUberのデータと計算インフラストラクチャの上に構築されており、Uberのすべてのトランザクションデータとログデータを保存するデータレイク、すべてのUberのサービスからのログメッセージを集約するKafkaブローカー、Samzaストリーミング計算エンジン、管理されたCassandraクラスタ、そしてUberの社内サービスのプロビジョニングとデプロイメントツールを提供している」とブログ記事は説明している。
機械学習のワークフロー
Uberでは、分類や回帰、時系列予測など、課題に関係なく、ほぼすべての機械学習のユースケースで同じ一般的なワークフローが存在している。ワークフローは一般的に実装に依存しないため、新しいアルゴリズムタイプや新しいディープラーニングフレームワークなどのフレームワークをサポートするために簡単に拡張することができる。また、オンラインとオフライン(車内と電話内)の両方の予測のユースケースなど、さまざまな展開モードにも適用できる。
Michelangeloは、スケーラブルで信頼性が高く、再現性があり、使いやすく、自動化されたツールを提供するために特別に設計されており、以下の6つのステップのワークフローに対応している。
- データの管理
- モデルのトレーニング
- モデルを評価する
- モデルの展開
- 予測を立てる
- モニタリング
データの管理:チームが異なるモデルで使用されている機能を登録したり、キュレーションしたり、共有したりできるようにするための集中型機能ストアなどがある。これにより、新しい機能を見つけるために新しいクエリを書かなくても、機能ストアから選択するだけでよいので、モデリング作業が楽になるという。さらに重要なことに、モデルが本番になると、予測時にそれらのフィーチャをモデルに配信するためのパイプラインを自動的に配線することができる。
モデルのトレーニング:もちろん、実際にモデルを訓練しなければならない。モデルの評価、モデリング作業は非常に反復的な作業なので、モデルを比較して、どれが良いか悪いかを見つけるための良いツールが必要になる。探索木や線形モデルの場合はCPUクラスタ上で、深層学習モデルの場合はGPUクラスタ上で大規模な分散トレーニングを実行する。ディープラーニングの場合は、TensorFlowとPyTorchをベースにしている。しかし、Horovodという独自の分散型トレーニングインフラストラクチャを構築した。Horovodには2つの興味深い側面があります。1つは、パラメータサーバを削除し、MPIとリングリダクションを含む別の技術を使用して、分散トレーニング中にデータをより効率的にシャッフルすることで、分散トレーニングをより効率的にしていることだ。また、モデリング開発者にとっては、分散訓練ジョブを管理するためのAPIが非常に簡単になる。これはスケールとスピードの面で非常に強力ですが、使い勝手も非常に良くなっている。
モデルを評価する:モデルは多くの場合、問題に最適なモデルを作成する特徴、アルゴリズム、ハイパーパラメータのセットを特定するために、方法論的な探索プロセスの一部として訓練される。与えられたユースケースの理想的なモデルに到達する前に、何百ものモデルを訓練しても、その中から選ばれなかったモデルが出てくることも珍しくない。最終的に本番で使用されることはないが、これらのモデルの性能は、エンジニアを最高のモデル性能をもたらすモデル構成へと導く。これらの訓練されたモデルを追跡し(誰が、いつ、どのデータセットで、どのハイパーパラメータで訓練したかなど)、評価し、互いに比較することは、非常に多くのモデルを扱う際の大きな課題であり、プラットフォームが多くの価値を付加する機会を提供する。
モデルの展開:気に入ったモデルができたら、ボタンをクリックしたり、APIを呼び出したりして、提供インフラストラクチャ全体にデプロイできる。Uberはここにオフライン展開、オンライン展開、ライブラリ展開の3つの区分を設けている。いずれの場合も、必要なモデル成果物(メタデータファイル、モデルパラメータファイル、およびコンパイルされたDSL式)は、ZIPアーカイブにパッケージ化され、当社の標準コード展開インフラストラクチャを使用して、Uberのデータセンター全体の関連するホストにコピーされます。予測コンテナは、ディスクから新しいモデルを自動的にロードし、予測要求の処理を開始する。多くのチームでは、ミケランジェロのAPIを介して定期的にモデルの再トレーニングとデプロイをスケジュールするための自動化スクリプトが用意されている。UberEATS配信時間モデルの場合、トレーニングと展開は、データサイエンティストやエンジニアがWeb UIを介して手動でトリガーする。
予測:Uberでは、ほとんどのモデルはリクエストレスポンスベースのリアルタイム予測サービスに展開されている。多くの場合、モデルに必要なデータはHadoopのどこかにある。過去のデータに対して分析クエリを実行するパイプラインを配線し、それをモデルが読み取れるキーバリューストアに配信する必要がある。スコアリング時にモデルが使用するために、適切なデータを適切な時間と場所に配信するためには、多くの複雑なパイプラインが必要になる。
モニタリング:モニタリングは過去のデータに対してモデルを訓練し、過去のデータに対して評価するという点で興味深いものだ。そして、本番環境にモデルをデプロイすると、モデルが正しい動作をしているかどうかが実際にはわからなくなる。そのため、時間的に予測の精度を監視できることが非常に重要になる。
モデルをトレーニングした後、ユースケースに適したモデルを見つけるまでに何十、何百ものモデルをトレーニングすることがよくある。トレーニングしたすべてのモデル、トレーニングデータ、誰がトレーニングしたか、モデルの精度に関する多くのメトリクスやレポート、さらにはデバッグレポートまでを厳密に記録しておくことができると、モデラーは反復作業を行い、最終的には本番で使用したいモデルを見つけることができるようになる。彼らはここで多くの作業に投資し、モデルに関するメタデータを収集し、開発者が理解しやすく、モデリングプロセスを前進させることができるような方法で公開している。
彼らが発見したのは、従来のツリーや線形モデルからディープラーニング、教師あり・教師なし、オンライン学習など、バッチパイプラインやオンライン、携帯電話でモデルを展開しているかどうかに関わらず、同じワークフローが、これまでに見てきたあらゆる種類の、あるいはほとんどのML問題に適用されるということだ。また、マーケットプレイスの事例で見たように、分類や回帰だけでなく、時系列予測にも機能する。これらすべてのことについて、基本的なワークフローは同じであるため、これらをサポートするためのプラットフォームの構築に時間を費やした。
参考文献
- Jeremy Hermann, Mike Del Balso. Meet Michelangelo: Uber’s Machine Learning Platform. Uber Engineering. September 5, 2017.
- Jeremy Hermann. Michelangelo - Machine Learning @Uber. InfoQ.
Image via Uber
Special thanks to supporters !
Shogo Otani, 林祐輔, 鈴木卓也, Mayumi Nakamura, Kinoco, Masatoshi Yokota, Yohei Onishi, Tomochika Hara, 秋元 善次, Satoshi Takeda, Ken Manabe, Yasuhiro Hatabe, 4383, lostworld, ogawaa1218, txpyr12, shimon8470, tokyo_h, kkawakami, nakamatchy, wslash, TS, ikebukurou 太郎.
月額制サポーター
Axionは吉田が2年無給で、1年が高校生アルバイトの賃金で進めている「慈善活動」です。有料購読型アプリへと成長するプランがあります。コーヒー代のご支援をお願いします。個人で投資を検討の方はTwitter(@taxiyoshida)までご連絡ください。

投げ銭
投げ銭はこちらから。金額を入力してお好きな額をサポートしてください。



