マイクロソフト、「最先端」の生物医学NLPモデルを提案
マイクロソフトの研究者たちは、「生物医学自然言語処理(NLP)のためのドメイン固有の言語モデル事前学習」というAI技術を提案。データセットから「包括的な」生物医学NLPベンチマークをコンパイルすることで、名前付き実体認識、エビデンスに基づく医療情報抽出、文書分類などのタスクで最先端の結果を得たと主張した。


要点
プレプリントサーバーArxiv.orgに公開された論文の中で、マイクロソフトの研究者たちは、「生物医学自然言語処理(NLP)のためのドメイン固有の言語モデル事前学習」と呼ばれるAI技術を提案している。公開されているデータセットから「包括的な」生物医学NLPベンチマークをコンパイルすることで、共著者らは、名前付き実体認識、エビデンスに基づく医療情報抽出、文書分類などのタスクで最先端の結果を得ることに成功したと主張している。
生物医学のような特殊な領域では、NLPモデルをトレーニングする際に、領域固有のデータセットを使用することで精度を向上させることができることがこれまでの研究で示されている。しかし、一般的な前提として、「領域外」のテキストも有用であるとされているが、研究者らはこの前提に疑問を呈している。研究者らはこの仮定に疑問を呈している。研究者らは、「混合領域」の事前学習は伝達学習の一形態とみなすことができ、ソース領域は一般的なテキスト(ニュースワイヤーやウェブなど)であり、ターゲット領域は専門的なテキスト(生物医学論文など)であるとしている。これを基に、生物医学NLPモデルのドメイン固有の事前学習が一般的な言語モデルの事前学習よりも優れていることを示し、混合領域の事前学習が必ずしも正しいアプローチではないことを示している。
研究を促進するために、研究者らは、事前訓練のためのモデリングとタスク固有の微調整を、バイオメディカルNLPアプリケーションへの影響別に比較検討した。最初のステップとして、研究者らはBiomedical Language Understanding & Reasoning Benchmark (BLURB)と呼ばれるベンチマークを作成した。このベンチマークは、PubMedから入手可能な出版物に焦点を当て、関係抽出、文の類似性、質問回答のようなタスクと、YES/NOの質問回答のような分類タスクをカバーしている。サマリースコアを計算するために、BLURB内のコーパスをタスクタイプ別にグループ化し、個別にスコアを付け、その後、それらすべてのコーパスの平均を計算する。
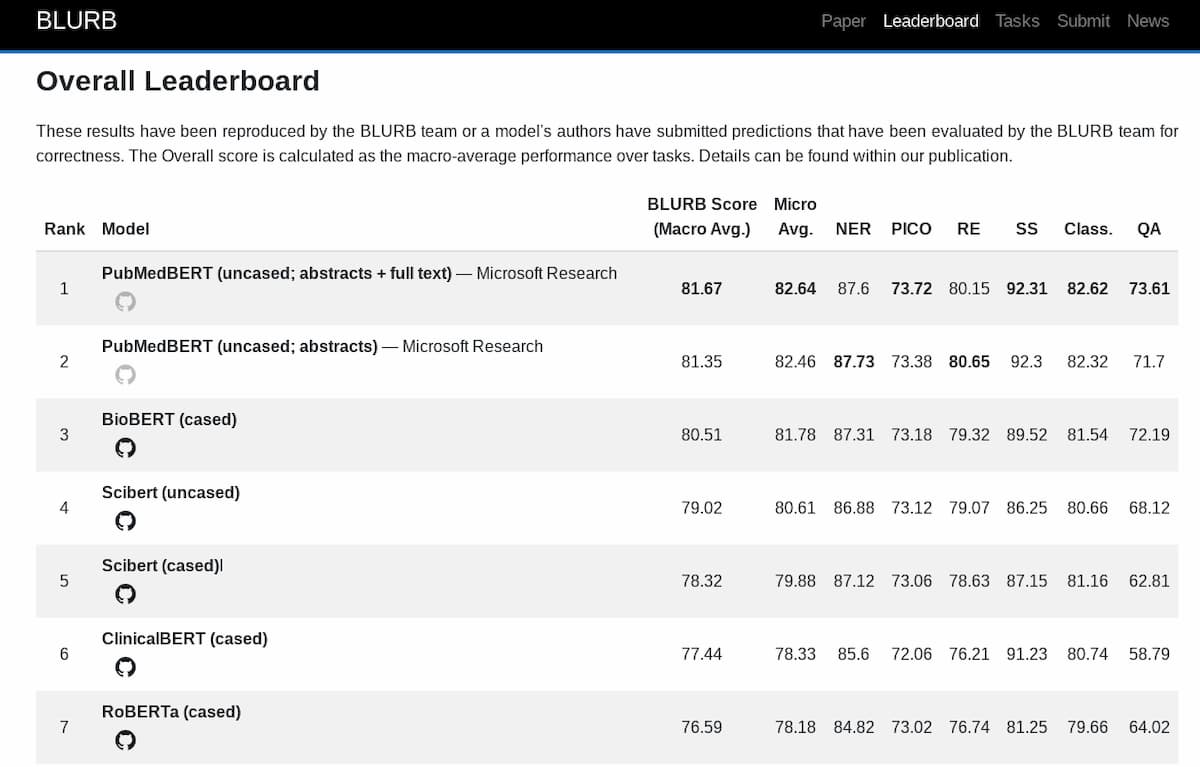
事前学習アプローチを評価するために、本研究の共著者らは,PubMed文書の最新のコレクションを用いて語彙を生成し、モデルを学習した。1,400万件の抄録と32億語、合計21GBである。訓練は、16枚のV100グラフィックスカードを搭載したNvidia DGX-2マシン1台で約5日間、62,500ステップ、バッチサイズは以前の生物医学的プレトレーニング実験で使用された計算に匹敵するものだった(「バッチサイズ」とは、1回の反復で使用される訓練例の数を指す)。
生物医学的ベースラインモデルと比較して、研究者らは、彼らのモデル-GoogleのBERTの上に構築されたPubMedBERT-は、ほとんどの生物医学的NLPタスクで他のすべてのモデルを「一貫して」上回ると述べている。プレトレーニングのテキスト(168億語)にPubMedからの論文のフルテキストを追加すると、プレトレーニングの時間が延長されるまでのパフォーマンスのわずかな低下につながった、興味深いことに、研究者は部分的にデータ内のノイズに属性している。
「本論文では、ニューラル言語モデルの事前訓練における一般的な仮定に挑戦し、ゼロからのドメイン固有の事前訓練が、一般的なドメイン言語モデルからの継続的な事前訓練などの混合ドメインの事前訓練を有意に上回ることを示し、広範囲の生物医学的NLPアプリケーションのための新しい最先端の結果につながることを示している」と研究者は書いている。「今後の方向性としては、ドメイン固有の事前訓練戦略のさらなる探求、生物医学NLPへのより多くのタスクの組み込み、BLURBベンチマークの臨床やその他の価値の高いドメインへの拡張などが挙げられる」。
生物医学的NLPの研究を奨励するために、研究者たちはBLURBベンチマークを特徴とするリーダーボードを作成した。また、事前に訓練されたタスク固有のモデルもオープンソースで公開している。
Photo by Microsoft



