MS、GPU10万台以上を載せた惑星規模のAIインフラを運用
マイクロソフトは先月、「Singularity」(シンギュラリティ)と名付けたAIワークロードのための惑星規模の分散スケジューリングサービスを運用していることを明らかにした。

マイクロソフトは先月、「Singularity」(シンギュラリティ)と名付けたAIワークロードのための惑星規模の分散スケジューリングサービスを運用していることを明らかにした。
26人のマイクロソフト社員が共著したプレプリント(査読前論文)に記述されているSingularityの目的は、深層学習のトレーニングにかかる計算コストへの対応であり、そのコストはワークロードのサイズ、複雑さ、数の増加に伴って急速に膨れ上がっている。また、ハイパフォーマンス・コンピューティングとそのシステム上でのAIモデル・トレーニングのコストと環境フットプリントをいかにして最小化するかという議論の焦点となっているアイドル時間を最大限に活用する試みでもある
Singularityは、arXivで公開されたプレプリント論文では、「惑星規模のアクセラレータの与えられた固定容量のプールで、複数の価格階層に対して厳しいサービスレベル契約を提供しつつ、総計の有用スループットを最大化することによってAIのコストを下げる」と、ひとつの主要目標に向かって作られていると説明されている。
研究者によると、Singularityはこのアクセラレータのフリート全体を「単一のローカルな共有クラスタとして扱い、リソースの断片化や静的な容量予約を回避する」とのことだ。Singularityは、リソースの増減に合わせてジョブを弾力的にスケーリングし、必要に応じて、ノード、クラスタ、リージョン間でジョブのチェックポイント、先取り、移行を行うことでこれを管理する。このスケジューラは、クラスタ、地域、ワークロードの境界を超えると同時に、プリエンプトされたところからジョブを再開することで障害に対する回復力を確保するという。

この論文では、Singularity自体よりもスケジューラーに多くの時間を費やしているが、システムのアーキテクチャを示すいくつかの図を提示している。Singularityの性能分析では、Xeon Platinum 8168を使用したNvidia DGX-2サーバーでのテスト実行に言及している。これは、各20コアの2ソケット、サーバーあたり8つのV100モデルGPU、692GBのRAM、InfiniBandでネットワーク接続されたサーバーだ。SingularityのGPUは数十万個で、さらにFPGAやその他のアクセラレータを搭載している可能性もあり、マイクロソフトは少なくとも数万台のこうしたサーバーを保有していることになる。
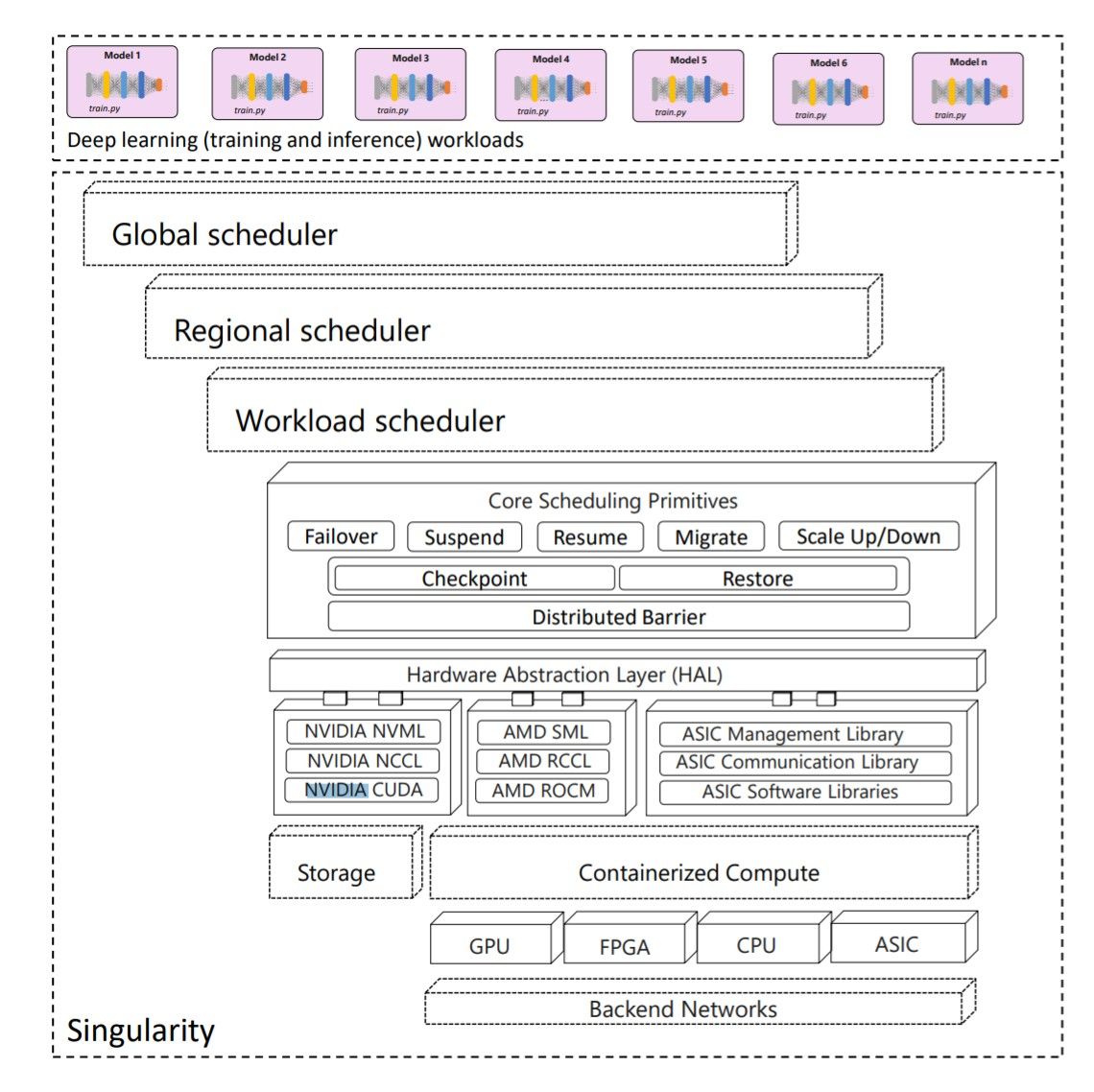
この論文では、Singularityのスケーリング技術とスケジューラーに焦点を当て、コスト削減と信頼性向上を実現するための秘策であると主張している。
このソフトウェアは、ジョブとアクセラレータリソースを自動的に切り離す。つまり、ジョブがスケールアップまたはスケールダウンする際には、「ワーカーがマッピングされるデバイスの数を変更するだけで、ジョブのワールドサイズ(すなわちワーカーの総数)は、ジョブを実行する物理デバイスの数に関係なく同じままであり、ユーザーには完全に透過的だ」。
これは、「レプリカ・スプライシング」と呼ばれる新しい技術により、各ワーカーがデバイスのメモリ全体を使用できるようにしながら、無視できるオーバーヘッドで同じデバイス上の複数のワーカーをタイムスライスすることが可能になっている」おかげで実現した。
これを実現するには、著者らが「デバイスプロキシ」と呼ぶ、「独自のアドレス空間で動作し、物理的なアクセラレータデバイスと一対一で対応する」ものが必要となる。ジョブワーカーがデバイスAPIを開始すると、それらはインターセプトされ、別のアドレス空間で実行され、その寿命がワーカープロセスの寿命から切り離されたデバイスプロキシプロセスに共有メモリ上で送られる。
以上により、より多くのジョブを、より効率的にスケジュールすることが可能になり、何千台ものサーバーがより長い時間サービスを受けることができるようになる。また、スケーラビリティを向上させ、中断することなく迅速に拡張することができるとされている。



