Nvidia、AIベンチマークMLPerfの提出物の85%を占拠
機械学習のベンチマークを提供するMLPerfコンソーシアムは21日、MLPerf Inference v0.7の結果を発表した。提出物の85%がNvidiaアクセラレータを使用していた。他のAIアクセラレータであるCerebras(CS-1)、AMD(Radeon)、Groq(Tensor Streaming Processor)、SambaNova(Reconfigurable Dataflow Unit)、Google(TPU)の存在感は薄かった。


機械学習のベンチマークを提供するMLPerfコンソーシアムは21日、MLPerf Inference v0.7の結果を発表した。提出物の85%がNvidiaアクセラレータを使用していた。他のAIアクセラレータであるCerebras(CS-1)、AMD(Radeon)、Groq(Tensor Streaming Processor)、SambaNova(Reconfigurable Dataflow Unit)、Google(TPU)の存在感は薄かった。
Nvidiaは、参加したカテゴリでトップのパフォーマンスを記録し、「クローズドデータセンター」と「クローズドエッジ」のカテゴリを支配している。MLPerfのクローズド・カテゴリーでは、参加システム間の比較を確実にするために、システムやネットワークの制限が課せられている。オープンバージョンのカテゴリでは、カスタマイズが可能です。実質的に言えば、Nvidia社以外の製品の中には、Nividia社のA100s、T4、Quadro RTXを上回ると期待されるものはほとんどなかった。
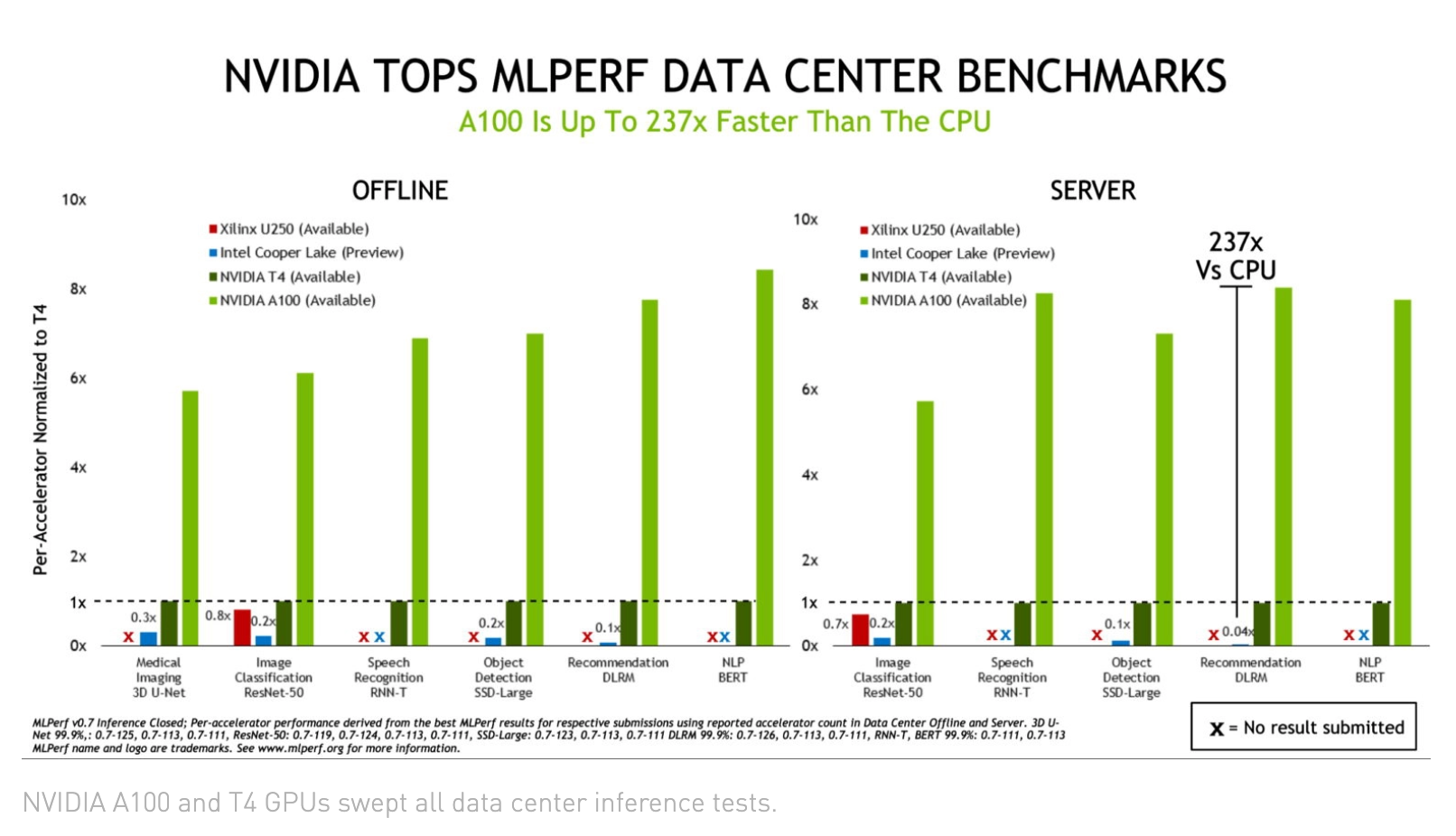
Nvidiaは、メディア向けのブリーフィングと、その後のParesh Kharyaのブログで、アクセラレーションシステムの製品管理担当シニアディレクターがこの結果を誇示した。A100 GPUは、オープンデータセンターのカテゴリではCPUベースのシステムよりも最大237倍高速で、同社のJetson AGXビデオ解析システムとT4チップは、電力に敏感なエッジカテゴリでも優れたパフォーマンスを発揮したとNvidiaは報告している。
Kharyaは「Nvidia A100は、Cooper Lake CPUより237倍速い」と説明している(下の図)。1台のDGX-A100は、1000台のCPUサーバーと同じ性能をレコメンデーションシステムで提供している。
MLPerfはベンチマーク・スイートとプロセスの改善を続けている。いくつかのモデルを追加し、フォームファクタに基づく新しいカテゴリを追加し、ルール遵守に関する無作為化された第三者監査を実施し、1年前の最初の推論実行から約2倍の提出数(23件対12件)を集めた。
さらに、Dell EMC、Inspur、富士通、Netrix、Supermicro、QCT、Cisco、Altosなど、参加しているシステムメーカー間の比較は、興味深い読み物になる(詳細は後述)。また、Raspberry Pi4やFirefly RK-3399など、Armテクノロジー(Cortex-A72)を使用した他のプラットフォームで、エッジで効果的に推論を実行できることがわかったのは、今後の産業応用に役立つはずだ。
MLCommons(MLPerf.orgの主催者)のエグゼクティブ・ディレクターであるDavid Kanterは、「結果と進捗状況に満足している。より多くのユースケース領域をカバーするためのベンチマークが増えました。異なるクラスのシステム間で良い区分けができたことで、より良い仕事ができたと思います」と声明の中で述べている。
バランス的には、参加した若手のアクセラレータ・チップ/システム企業が少なかったことに、オブザーバーは軽度の失望感を示したが、驚きはしなかった。全体的には、AIコミュニティはまだMLPerfを大きく支持しているようで、重要なフォーラムになるための軌道に乗っていると述べている。



