エッジの逆襲 ポストモバイル時代が視る夢はなにか
5G以降は、計算処理をクラウドに依存するのではなく、デバイスとマイクロデータセンターが分散協調するエッジコンピューティングへの移行が起きる。センサーが生成する大量のデータを処理するためには、水道のように安価な機械学習が必要となる。


Summary
- 富裕国でモバイルフォンが生み出したエコノミーは飽和している。モバイルの未来はネット接続していない「世界の残り半分」にある。これらの新興国には、中国が達成したような富裕国の状況をとび越えたデジタル・エコノミーを構築するチャンスがある。モバイルはいまでも世界経済に重要なインパクトを与える要素である
- ノイマン型コンピュータの性能向上の限界が近づいている。今後はコンピュータ・アーキテクチャとソフトウェアの多様化が想定される。最も典型的な領域が機械学習である。機械学習はエッジコンピューティングにおいて非常に重要な役割を果たす。自律的に意思決定する機械が人間のあらゆる仕事を手伝うようになる
- 未来はエッジにある。5Gはエッジの処理をクラウドに吸い上げるのではなく、エッジデバイスが分散協調するためのインフラになる。テックジャイアントは大規模クラウドからエッジへの拡張を進めている。エッジで大量に生まれるデータを処理するためには、水道のように安価な機械学習が必要とされている
- ヒューマン・コンピュータ・インターフェイス(HCI)はスクリーンへの一極集中が続いたが、これからはAR / VR / MRのほか、音声に広がっていく
- 上記の変化はわたしたちの経済にとてつもない衝撃を与える: とてもわくわくする
想定読者
ぼくは本記事をモバイル以降のビジネストレンドを探索する目的で執筆した。対象読者はテック業界、メディア広告業界、起業家、投資家、今後周辺産業に就職、転職する人を想定している。ビジネスパーソンの方にぜひ読んでいただきたい。途中からある程度テクニカルになるが、読み飛ばしながらエッセンスをとることは可能だ。「ビジネスサイドがテクニカルなことを理解する必要はない」という時代はとうに終わったので、ぜひ挑戦してほしい。
僕はこの記事の初稿はスマートフォンで書いた。途中からスマホに飽き飽きとしてしまった。僕もコンピューティングの新しい価値を求めてやまない。さあ、一緒に次の世界へ行こう。
0. ポストモバイル
ピーター・ティールはNewYork Timesのインタビューでモバイルについてこう語っている。「私たちはスマートフォンがどういうものか、それで何ができるかをすでに知っている。これはTim Cookの責任ではない。これ以上のイノベーションが望める領域ではないのだ」。
Thileが話したことはどんなコンテクストをもつか。2007年にAppleはiPhoneがスマートフォンという形態を確立し、ブラックベリーや日本人ご用達のiモード電話のような、それまでの「インターネット接続する電話」を駆逐して以来、テック業界はこのモバイルというトレンドとともに動いてきた。
インターネット測定企業Comscore ”Global Digital Future in Focus 2018”によると、この通り。
- デジタル時間消費の61.9%がスマートフォン、タブレットを含めると7割超が”モバイル”で占められる。
- モバイルユーザーはデスクトップユーザーと比較して2倍以上の時間を消費する
- モバイルで消費される時間の80%以上はアプリで消費される
- 富裕国ではデスクトップとモバイルを同時に利用するマルチプラットフォーム利用が多数派だが、モバイルオンリーのインターネットユーザーが世界的に増えている。モバイルオンリーの割合は新興国で大きい傾向がある。
Thielが投資し取締役を務めたFacebookほどこのトレンドを説明するのに適切な企業はいないだろう。ハーバード大生向けのデスクトップwebサイトは、トレンドの変遷に合わせて開発資源をモバイルに集中させた。いまやFacebookのトラフィックの大半がモバイルアプリによるものだ。2018年Q2決算によると、同社の広告収益90パーセント以上がモバイルからもたらされている。デイリーアクティブユーザー数は14億7100万人を数えているが、うち10億人はモバイル利用が大半を占める「アジア太平洋、その他」からもたらされている。
モバイルがフランスの王政のように死んで、消え去るというわけではない。モバイルには2つのフロンティアがある。一つがまだ接続していない人々であり、もう一つは高度化である。
つまりこういうことだ。__安い電話がインターネットのいきわたっていない人々に接続性(Connectivity)を授ける。モバイルをバックグラウンド(所与の条件)とした富裕国たちはコンピューティングの多様化と高度化の季節に突入する。加えて、富裕国では、コンピュータネットワークとヒューマンインタフェースの高度化も起きる。__とてもワクワクしてくるはずだ。
1. 未接続者
モバイルを持っていない人が世界中にたくさんいる。つまりインターネットユーザーではない人がまだたくさんいる。モバイルは「未接続(Unconnected)な人たち」にとって絶好のゲートウェイドラッグだ。
グローバルインターネットユーザー数は2017年に36億人に達し、世界人口の49%に達している。50%が手付かずの市場である。ただしYear on Yearのユーザー数成長率は鈍化しており、2016年が前年比12%の成長だったが、2017年は7%に過ぎない。この世界人口の50%のライン以降、成長速度の鈍化が想定される(Kleinerperkins "Internet Trends Report 2018")。
課題は幾つかある。スマートフォンの普及はコネクティビティ(インターネット接続性)の供給と表裏一体である。ワイアレスネットワーク(無線ネットワーク)が普及していなければ、スマホはただの「トランジスタを詰め込んだ電話」だ。安定したコネクティビティとクラウドコンピューティングへのアクセスが整備されるために、賢くて清潔でコンシステントな政府のリーダーシップが必要だ。だが、新興国は往々にして機能的な政府を持つことに難点を抱えている。開発途上国の低所得者には100ドルのスマートフォンと数十億ドルの通信コストでも高価だ。
「ゲートウェイドラッグ」は安いほうがいい。5万円くらいするヘッドセットでもなく、売り手が50%近い利益率を上げる高価なiPhoneでもなく、「安い電話」がいい。新興国では「安い電話」こそ「インターネットの未来」である。
順調に経済成長するインドは典型的なインディケータである。IDC Indiaによれば、スマートフォン企業は2018年Q2にインドに合計3350万台を出荷した。台数は前年同期比で20%成長した。平均販売価格(ASP)150ドル程度の市場で、Xiaomi, Vivo, Oppoなどの中華勢が激しい競争を繰り広げている。
インドではコネクティビティの供給も前進している。telecomlead.com によると、2017年の段階で、ワイアレスネットワーク契約者は4億2467万人に達しており、インターネット契約者の95%に上る。インド最大財閥Relianceが通信事業者に参入して以来4Gの利用者も急激に拡大しており、2億3800万人に達した。4Gの速度は「世界平均の3分の1」ではある。ただインドが4G、5Gの波に乗ろうとしていることは確かだ。アプリケーションレイヤーではモバイルプラットフォームを前提とした進歩的なサービスが欧米と中国、ソフトバンクの資金を元に挑戦をしている。今後は一人あたりGDPようなマクロ経済諸表や、資源配分の効率化を推し進め、ワイヤレスネットワークの供給を容易にする都市化などの事象が、インドのモバイルインターネットの上の経済の発展に影響を与えるだろう。
ガバナンスが不安定なインドでもモバイルフォンとコネクティビティの供給が成功している。中東やアフリカでも同様のシナリオに期待できる。
奇跡的に発展した中国が先例だ。スマートフォンのASPは、その国の経済状況に比例して上がっていくと考えるのが妥当だ。中国でも数年前はHuawei, Xiaomiなどの大手メーカーが廉価帯を中心に製造販売していたが、近年は中〜高価格帯にシフトしている。インドの課題は深センを持たないことだ。電化製品の大半は中国からの輸入であり、ある程度の機能要件を満たしたスマホは深セン生産品である。ハードウェアとソフトウェアの知見が国内に蓄積せず、ただの輸出先として発展してしまうことだ。そしてこの課題はもしかしたら中東、アフリカ諸国が引き継ぐことになるかもしれない。
1.1 中国は「世界の工場」であり続ける
中国はエレクトロニクスにおける世界の工場であり、スマートフォンの生産は海外に移転しそうにない。中国企業は製造を支配するだけでなく技術開発面で米テック企業をキャッチアップしている。
Huaweiの成長は驚異的だ。80年代のジャパニーズエレクトロニクスの台頭を現代の中国に見ている感じだ(日本はその後大変なことになってしまったが)。「HUAWEI P20 Pro」は出色の傑作で、カメラに関してはiPhoneに匹敵する性能を示している。SoC(システムオンチップ)でも独自開発が進んでおり、特許数を積み上げつつある。Huaweiの今秋投入のSoC、Kirin 980はiPhoneのA12 Bionicと"史上初"の7nmプロセスを競い合い(ファブはともにTSMC)、トランジスタ数は69億とA12 Bionicと同じ数になる見込みである。同社はQualcommのSnapdragon 845との比較データを示し、Kirin 980はSnapdragon 845と比較して性能で37%、電力効率で32%優れていると主張している(参考: PC Watch)。
しかし、現行のKirin 970はSnapdragon 845に負けている。Snapdragon855のシングルプロセッサのベンチマークはGeekbenchにリークされており、かなり素晴らしいスコアだった(Source: Geekbench)。Snapdragon855搭載のGalaxy S10は来年始め発売の予定で、そのときにKirin980, A12 Bionic, Snapdragon855が雌雄を決することになる。とあるGeekbenchの比較によるとCPU性能の比較ではA12が若干のリードを保っている。が、スマートフォン用チップの歴史上、最もプレイヤーのちからが均衡した時代に突入した。
HuaweiはApple, Intel, QualcommとハイエンドSoCで競争できていることが重要だ。ハイエンド機の開発製造が太平洋またがずして中国で完結する未来はすぐそこまで来ている。
また、チップの生産に関しては台湾のTSMCが極めて重要な存在になっている。前出の”史上初”の7nmプロセスを製造できるのは2018年の間は台湾のTSMCのみになる見通しだ。7nmプロセスが何かということを掘り下げていくと電子工学の沼にハマるので省略するが、これを実現するには高度な技術力と莫大な投資が必要になる。スマートフォンの組み立てで重要な役割を果たす鴻海精密工業も台湾企業であるように、台湾は深センと湾岸の工業地帯への主要な投資家である。深セン、台湾周辺のエレクトロニクスにおける凝集性は極めて価値が高く、近い内にこれに対して競争力を示せるプレイヤーが現れるかは疑問である。
加えて、深センの対岸にある資本供給先としての香港も重要だ。アリババ、テンセントの上場する香港証券取引所はアジアで最も重要な取引所であり、香港を通じた本土中国への外国直接投資は、現地企業の資金調達コストを下げている。台湾同様、香港にも本土中国とは政治的緊張があるが、三者の経済的なつながりの利益はとても大きいのだ
1.2中華プラットフォームの独自化
Huaweiは独自OSを開発していると言われている。現状、AndroidとiOSはスマートフォン市場の99.9%を握っている。Duopoly(複占)だ。
South China Sea Postによると、Huaweiは2012年に米当局がHuaweiとZTEに捜査を実施した際に独自OSを開発し始めたと言われる。Huawei創業者のRen Zhengfeiは「最悪の事態に備えるため独自のOSをもつべきだ」と当時発言していた。トランプ政権の米国は今夏、HuaweiとZTEに再び圧力をかけており(ZTEは一時輸入禁止、以降も当局の監視が続く状況だ)、Huaweiは秘密裏に続けているOS開発が再び重要性を増したと同紙は推測している。これに対し同社幹部はそうする必要はなく、Androidは「完全に許容可能」と判断したと説明している。
興味深い年次予測を出すCCS Insightは「米国の技術支配の断片化」として、中華独自OS採用の見通しは実際に、おそらく2022年までに可能性が高いと主張している。CCSは、中国が5Gで主導権を握り、全世界で自国のサービスのマインドシェアを獲得していると見ている。
「中国と米国の現在の政治的緊張と、ZTEとHuaweiのトラブルは、他の中国企業がスマートデバイス用の独自OSを開発する強いインセンティブになる。米国企業への依存度をすばやく下げることを願い、中国のテクノロジープレイヤーは4Gスマートフォンの代わりに5G対応デバイスを使用して自国開発プラットフォームへの移行を進めていく」(筆者抄訳)
Huaweiは現在デバイスとSoC、一部のアプリケーションを設計している。加えてOSの設計を検討するのは自然だ。だが、Androidはオープンソースである。潤沢な開発リソースを費やすことがたやすいGoogleにOSを任せておくことは理に適う。中国国外のAndroidユーザーはYouTube, Googleなどのアプリケーションに依存している。Windows Mobileのような独自OSとAndroidとの決別のコストは高い。Huaweiは、Googleが無視できないスマートフォンの巨大製造業者だが、独自OSの条件は整っていない。
CCSはまたテンセントとアリババが西欧と新興市場でより重要になったことを明らかにした。憂慮すべきことに、彼らは電子商取引と同じように「市民のスコアリング」を運用したい(多くの新興国の)権威主義的な政府に好まれる。ユビキタスサーベイランスは、国家が個人の活動の広範囲を監視することを可能にする。政治的な抗議をする人々は国家により様々な苦境を与えられる可能性がある。
1.3テックエコノミーの先端
さてゲートウェイドラッグがまだ接続していない世界に何をもたらすのだろうか。それはテックエコノミーである。中国はモバイルファーストなインターネット普及が新しい経済をもたらした典型的な例だ。先進国のコンシューマに先入観があったり、いまだにポータルサイトの画面にくらいついている人がいるが、中国には何もなかったところにモバイルベースのネット体験が入り、あくなきユーザーの利便性が追及された。コマースや金融で中国は欧米日をはるかに凌駕するビジネスを作り上げている。金融における富裕国と新興国の対比に関してはぼくは日本では早い段階でこういう記事(『デジタル決済革命はアジアで起きている:先進国凌ぐ中印』)を書いているので、ここに宣伝をしておこう。この記事から数年経ったいま規制を整えようとする日本はかなりマズい。
中国市場の規模が大きくなれば、デジタルビジネスモデルの大規模な社会実装が急速に進んでいく。中国のインターネットユーザーベースの規模は、プレイヤーによる実験の継続を促進し、デジタルプレイヤーが「規模の経済」を迅速に達成できるようにする。中国は2018年8月時点で中国は8億人のインターネットユーザーを抱えており、欧州連合と米国を合わせた規模に当たる。
中国の消費者に広く共有されたデジタルツールへの熱狂は成長をサポートし、イノベーションの急速な導入を促進し、中国のデジタルプレーヤーとそのビジネスモデルを競争力のあるものにしている。 マッキンゼーの『China’s digital economy: A leading global force』によると、中国のインターネットユーザーの5人に1人近くが、携帯電話のみに依存している(モバイルオンリー)のに対し、米国ではわずか5パーセントに過ぎない。中国のモバイルデジタルペイメントを利用しているインターネットユーザーの割合は約68%である。米国では約15%にとどまる。
中国の3大ネット大手は自分たちを超えて広がる豊かなエコシステムを構築している。BATとして知られるBaidu、Alibaba、Tencentは、インターネット世界で確かな地位を築くのと同時に低品質で非効率な「オフライン市場」をもディスラプトしている。 BAT企業は、消費者の生活のあらゆる側面に触れる多面的かつ多産業に渡るデジタル・エコシステムを開発してきた。2016年にBATは、中国におけるベンチャーキャピタルの総投資額の42%を提供し、米国のベンチャーキャピタル投資のわずか5%に留まったAmazon, Facebook, Google, Netflixよりも、はるかに重要な役割を果たした(出典:前出のマッキンゼー資料)。中国の大手3社だけでなく、Huawei, Xiaomi, DJIのハードウェアメーカーのほか、Toutiao, Didiなども独自の生態系を構築している。中国のデジタルプレーヤーはハードウェアメーカーとの密接なつながりの顕著な利点を享受する。珠江デルタの産業拠点は、ハードウェア製造能力の強さのため、ネット接続デバイスの主要生産者であり続ける可能性が高い。
中国政府は厳格な規制を適用するだけでなく、デジタルプレイヤーの実験を許容し、テック企業の積極的な支援者になっている。市場が成熟するにつれて、政府と民間部門は徐々に規制と施行を通じてより健全なデジタル経済開発を形作ることをめぐりより積極的になってきた。 今日、政府は、投資家、開発者、消費者のデジタル化を支援するための世界クラスのインフラを構築する上で積極的な役割を果たしている。
1.4 "未接続者"の結論
モバイルというトレンドは新興国から開発国(Developing Countries, 発展途上国という訳語は不適切だと思う)にあり、欧米日の富裕国にはない。これまでConnectivity(接続性)がなかった場にそれが普及し始めると、人々はネットワーク提供するさまざまな利益を享受し始める。そしてそこでは見たこともないような新しいビジネスが生まれるし、現実世界のあり方を変えていくのだ。混沌とした物事のなかから新しいものが、それこそ富裕国では想定できなかったほど独創的かつ、多大な便益をもたらす素晴らしいプロダクト群が、人々の生活を豊かにする機会がある。中国はそれを実証し、次はインド、アフリカが続く版である。
2. 富裕国での高度化
さて、もうひとつのフロンティアの富裕国における高度化について見てみよう。電話が切り開いたコンピューティングの移動性(モビリティ)が、これからくる時代には移動性ですらなくなり、空気のようにどこにでもあるものになっていく。モバイル(Mobile)という言葉でスマートフォンを指すことができた時代が今までだとすると、あらゆるデバイスがインターネットに接続するときには、あなたは地球上に存在する限り常にメッシュに包まれた状態になる。その隙間のない網目の中で用いられるコンピューティングには機械学習という未来がある。そしてそのコンピュータネットワークに接続するインターフェイスは拡張現実(AR)という形を取ることになる。
富裕国での高度化はコンピューティングの進化に依存する。各領域においてさまざまな進化が期待されており、各要素がいつ、どれほどの効果を及ぼすのかは極めて流動的であり予測が困難だ。テクニカルな説明になるが、それ以外の方法は見つからないので、読み飛ばしながら、お付き合いいただければ幸いである。モバイル未来を予見するには、コンピューティングの未来について目を見張らないといけない。
2.1 ポストムーア
チップの微細化のルールはすでに「ムーアの法則の終わり」に達したと考えていい。微細化が処理速度や消費電力、コストを低下させる時代はすでに終わった。近年、チップ産業はコストを容認しながらも微細化やマルチコア化を進めてきた。彼らはチップを三次元構造にしていくことで物理的な集積の壁を越えようとしてもいる。
Intel共同創業者ゴードン・ムーアは1965年にチップ当たりのトランジスタ数が1~2年で2倍になると予測した(その後期間を「18ヶ月から24ヶ月」に訂正した)。この法則はIntelの存在理由であり、現代社会の圧倒的進化の原動力のひとつでもあった。だが、法則は終わりを迎えている。2014年のDRAMチップには80億個のトランジスタがあったが、160億個のトランジスタをもつDRAMチップは2019年まで量産されないことが確定している。ムーアの法則では2019年には4倍のDRAMチップが開発されていないといけない。2010年のIntel Xeon E5マイクロプロセッサは23億個のトランジスタを有し、2016年のXeon E5は72億個のトランジスタを有している。これも法則に反する。半導体製造技術は過去に比べて改善が進んでいるが、その性能改善の速度は遅くなっている。
あまり知られていないが重要なのはデナード則(デナードスケーリング)だ。1974年のRobert Dennardの洞察は、微細化が進めば処理速度は向上し、同じ面積の中に複雑な回路を集積することができ、消費電力が低下することを意味した。微細化が性能向上を約束する魔法のような法則である。デナード則は最初に観測されてから30年たった2000年代なかばに終了した。微細化がもたらすメリットは低下し、半導体企業はシングルプロセッサでの性能向上からマルチコアで性能を増やすことでムーアの法則を守ることを考えたのだ。ただし、このマルチコア化による性能改善にも「アムダールの法則」という制約が課せられている。
業界はシステムオンチップのような形で経済的得を表現し、ソフトウェアの改善の力を借り、命令セットの簡易化、アウト・オブ・オーダー実行、投機的実行などの細やかな最適化を施している。万策を尽くしているが、機械学習の「探索と活用」において、あからさまに活用の成果がサチってきている状況である。カリフォルニア大学バークレー校教授のデイビッド・パターソンは、プロセッサの性能改善は「”20年で2倍”速くなる」と指摘している。
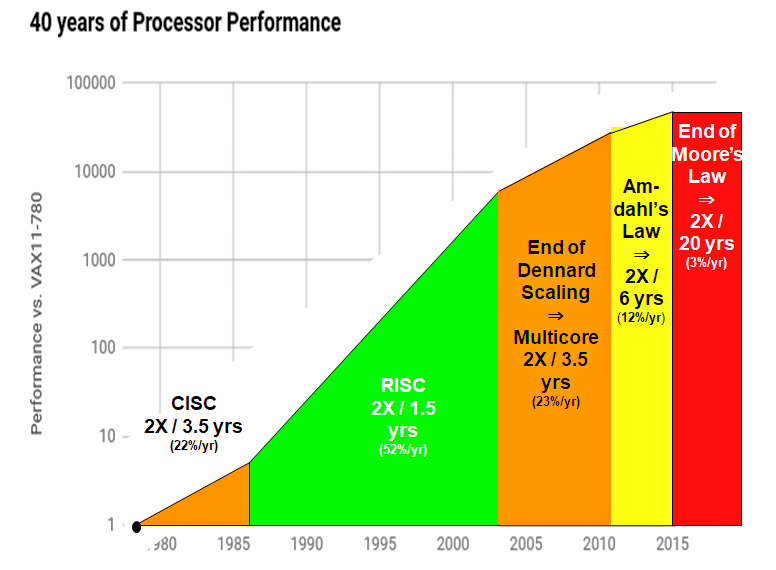
微細化は経済と物理の双方の制約を生み出している。7nmプロセスを製造できるファウンドリは1,2社に限られており、ファブラインの構築に10億ドルを超える設備投資が必要になる。微細化技術の開発はとても困難であり、プロセスをコンパクトにするたびに加工方法や素材の転換が求められる。次世代の投入までの時間は引き伸ばされてきている。同時にチップ開発は投資を回収する商業的成功を必ずしも保証されているわけではないので、ファウンドリ(半導体製造業者)が負担するリスクが高まっている。
微細化がコスト効率を悪化させているという経済的な制約と、チップの微細化に限度があるという物理的な制約が生まれている。ジョン・ヘネシーやデイビッド・パターソンは「ムーアの法則の終わり」を宣言し、特定の目的に特化したアーキテクチャとソフトウェアの導入を提案している。近年は現代をコンピュータアーキテクチャの「カンブリア紀」とするレトリックも多数見られる。地球が界面に覆われ、生物が爆発的に多様化した時期であり、ノイマン型の汎用なコンピュータの設計ではなく、その目的に応じたアーキテクチャが設計されるようになる時期であることを指す。
これは産業面にも衝撃を与えている。2018年にApple発売した新型iPhoneやMacBookが劇的な性能向上を表現できなくなっている。Macbookが積んでいるIntelのCPUは、AMDに対抗しようといたずらにコア数を増やしたのが災いし発熱する。冷蔵庫で冷やしたあとに使用するとパフォーマンスがいい。ハードウェアの進化があなたの体験の進化を表現しない。この課題はクラウドの進化が解決してくれるし、コンピュータアーキテクチャ自体にもさまざまな進化のオプションが多数存在する。まずは後者を掘り下げてみよう。ムーアの法則の終焉は大きな転換点である。
ジョン・ヘネシーとデイビッド・パターソンの名著『Computer Architecture, Sixth Edition: A Quantitative Approach』の最新版には『Domain Specific Architectures”ドメイン固有アーキテクチャ”』の章が加えられている。Domain Specific Architectures (DSAs)の代表的な例としてGoogleのTPU(Tensor processing unit)とMicrosoftのFPGAが挙げられている。ヘネシーはGoogleの親会社Alphabetの会長に就任し、パターソンはGoogleエンジニアとTPUの開発に取り組み、UCLAの教授職を定年退職した後はGoogleでパートタイムで働いており、TPUに携わっている。どうやら何か新しいことが起きている。
この機械学習に特化したチップ、TPUについて知るには、まずGPU(Graphic processing unit)について説明しないといけない。
2.11 GPU
CPUは汎用的な処理を得意とするが、GPUは画像処理に特化している。GPUのCPUとの違いは並列処理にある。逐次処理用に最適化された数個のコアから成るCPUに対して、GPUは複数のタスクに同時に対応できるよう設計された何千ものより小さく、より効率的なコアで構成されている。GPUはCPUから描画情報を受け取ると、頂点処理、テクスチャの参照やピクセル単位での照明計算を含むピクセル処理などを実行し、画面に出力するという手順を即座に進める。頂点処理やピクセル処理は高い並列性という特性がある。
「GPU」という用語はNVIDIAによって広く普及した。NVIDIAは1999年にGeForce 256を「世界初のGPU」と銘打って売り出した。実際には1976年のRCA Studio II、1977年のAtari 2600に「ビデオチップ」が搭載されておりこれが最初の画像処理特化チップと考えられる。ゲーミングや映画でCG映像の使用の拡大とともにGPUは市場を広げてきた。その後、GPUは劇的に性能向上を続けていたが、市場はそれに追いつかなかった。3Dゲームだけが、その性能を使い切ることができた。
画像処理から汎用利用への拡張は2007年に起きている。2007年にNVIDIAによってGPGPU開発環境CUDAが一般公開されると、多くのユーザーが高い演算性能を安価に得られる新たな並列計算ハードウェアとして CUDAに興味を示し、GPGPUの研究が広く注目を集めることとなった。CUDAは現在NVIDIA製GPUに対して最も低いレイヤーでアクセスすることが可能なプログラミング環境であり、適切に利用することでGPUの持つ性能を引き出すことができる。AMDも2008年にATI Stream SDK(AMD Stream SDK) とBrook+からなる開発環境の一般公開を開始した。
GPUの性能はCPUを超える速度で向上している。HPC(ハイパフォーマンス・コンピューティング)の要求に応えグラフィックスだけでなくGPGPUを意識した性能も向上している。 NVIDIAはGPGPUに重点的に投資し、AMDを圧倒した。
2.2 機械学習ハイプとGPUとの婚姻
GPGPUには驚くべき副産物があった。それは機械学習である。GPUをCNN(畳み込みニューラルネットワーク)の並列計算に利用する。2000年代後半にジェフ・ヒントン(Geoff Hinton)のバック・プロパゲーションと確率的勾配降下法、ヤン・ルカンの畳み込みニューラルネットワークなどの、ゲームチェンジングな発見が現れ、二度の冬にさらされた”人工知能”に生命の息吹が注がれた。
スタンフォード大学のアンドリュー・ウン氏とNVIDIAはGPUを機械学習に応用する研究をCUDAを投入した2007年頃から開始した。ウン氏はモデルが猫を識別する「Googleの猫」でGPUによるCNNトレーニングの高速化を実証した。ImageNetの2012年大会では、トロント大学のアレックス・クリジェフスキー氏が、大規模なGPUトレーニングで教育したモデルで、伝統的なコンピュータビジョンの専門家に大差の性能を見せつけた。
この後、機械学習への熱狂が高まり、GPUへの需要は高まるばかりである。その熱狂を物語るエピソードがある。2016年12月に開催された機械学習関連のトップカンファレンス「Neural Information Processing Systems(NIPS)」に向けた論文の締め切りは5月19日だったが、これに合わせて世界中の研究チームがクラウドを利用したため、Google CloudとMicrosoft AzureのGPUが一時的に枯渇したのだ(The Registar)。
機械学習領域での成功はNVIDIAの株価を急激に引き上げた。日経BPに「トヨタが頼った謎のAI半導体メーカー」と書かれたが、NVIDIAの時価総額はトヨタに肉薄しつつある。NVIDIAは機械学習用のチップを事実上独占し、これが最大の利用者であるテックジャイアントの危機感を煽った。
2.3 Google TPU
ムーアの法則の終わりは、ドメイン特化型アーキテクチャ(Domain Specific Architectures = DSAs)を「コンピューティング」の未来とした。GoogleのTPU(Tensor Processing Unit)は2015年に初めて導入された。TPUを利用するGoogleのクラウド・コンピューティングは10億人以上にサービスを提供している。それは「現代のCPUおよびGPUよりも30〜80倍優れたエネルギー効率で、ディープニューラルネットワーク(DNN)の推論を15〜30倍高速で実行する」と説明されている。
Googleは2006年にはじめて、データセンターにGPU、FPGA、ASIC(特定用途向け集積回路)を導入することを検討した。特別なハードウェア上で実行できるアプリケーションは、Googleの大規模データセンターの超過容量を使用して無料でほとんど実行できるが、同時に無料の性能改善は困難だった。つまり、現状への対応はできるが需要の拡大には対応できない状態だったという。
しかし、2013年にGoogleユーザーが音声認識のDNNを使用して1日3分声で検索した場合、データセンターの計算需要が倍増することがわかった。これは従来のCPUを使用すると非常に高価になる。Googleはこうして推論のためのカスタムチップを素早く開発するという優先度の高いプロジェクトを開始した。目標はコストパフォーマンスを10倍向上させることだった。TPUはわずか15ヶ月でGoogleのデータセンターで設計、検証、構築、展開された(Communications od the ACM "A Domain-Specific Architecture for Deep Neural Networks”)。チップの開発は通常約3年かかるものだ。
2.4 TPUの技術的な説明
TPUは大規模なマトリックス乗算 (行列積) の用途に特化した、高いスループットを提供する「マトリックス乗算ユニット(Matrix Multiplication Unit)」と大型のソフトウェア制御型のオンチップメモリで構成されている。GPUがベクトル演算に特化しているのに対し、TPUはマトリックス乗算に特化することで、ニューラルネットワーク(NN)の推論、学習に最適化されている。
アーキテクチャは 65,536 個の 8 ビット整数乗算器を使用してシストリック・アレイ・アーキテクチャーを介して次から次へとデータをプッシュする。シングル・スレッドの単一の高水準命令を使用して複数の低レベル処理をトリガーできる「複合命令セット・コンピューティング(CISC)アーキテクチャ」を採用する。
NNの推論、学習に完全に特化されており、機械学習への活用に置いてCPU、GPUよりも優れていると説明されている。以下はGoogle Cloud Platform Japan Blogから引用する。
- ニューラル ネットワークの推論を使っている本番 AI ワークロードでは、TPU は現在の GPU や CPU よりも 15 倍から 30 倍高速。
- TPU のエネルギー効率は従来のチップよりもはるかに高く、30 倍から 80 倍の改善を示している。
- これらのアプリケーションを支えるニューラル ネットワークのコード量は驚くほど少なく、100 行から 1,500 行に過ぎません。このコードは、Google が開発した人気の高いオープンソースの機械学習フレームワークである TensorFlow をベースとしている。
GoogleはデータセンターにおけるGPUの消費電力がネックだったと指摘している。データセンターのハードウェア投資の基準は、総所有コスト(TCO: Total Cost of Ownership)におけるはずだ。機械などを保有する際にその購入費用だけでなく、使い続ける費用なども含んだ総コストを指す。巨大なデータセンターにおいてプロセッサの電力効率がきわめて重要だとJohn Henesseyが指摘している。 論文では、TCOはビジネス上の理由で開示できないが、TCOと相関する電力コストを開示できるとしている。
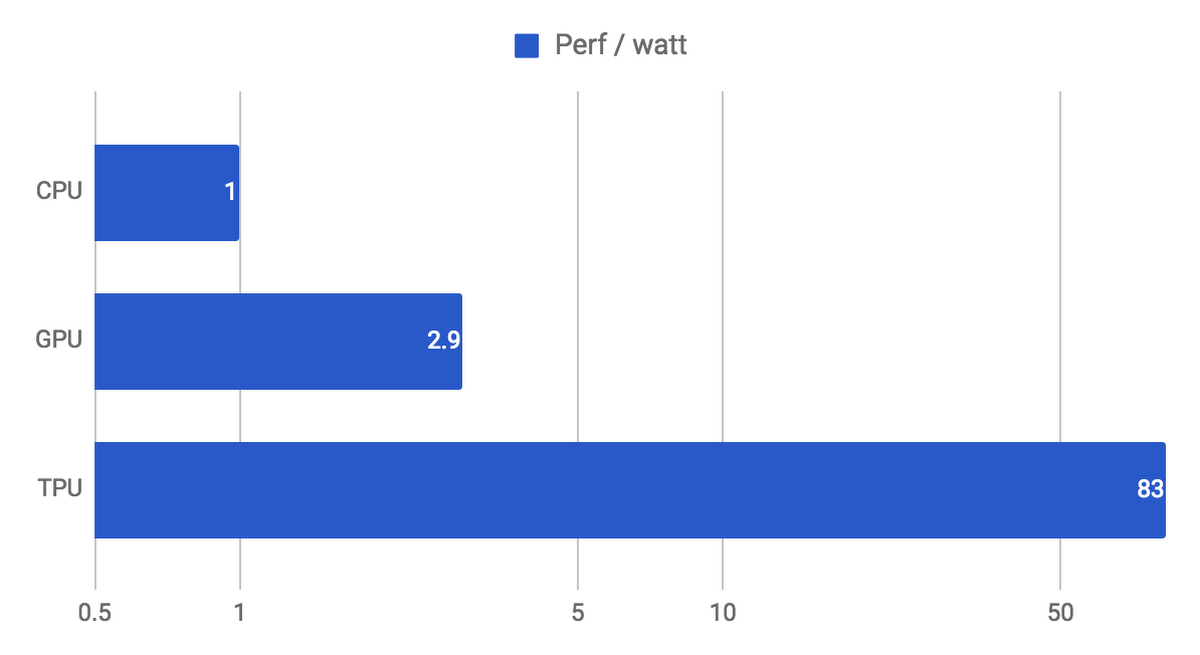
TPU v1(2015年)は推論のみの対応だったが、TPU v2(2017年)は推論とトレーニングにも対応した。Googleは今年の5月に発表したTPU v3で構成したポッドは前世代のポッドより8倍早いと主張している。TPU v3は初めて水冷を採用している。冷却液で冷やすことは熱容量が圧倒的に大きく、空冷よりおおむね冷却性能が高い。

Googleはハードウェアだけでなくソフトウェアでも機械学習特化を進めている。TensorFlow である。TensorFlow はGoogle Brainプロジェクトによって開発されたクローズドソースの深層学習システム「Google DistBelief」にそのルーツを持つ。Googleは分散処理用にTensorFlowをゼロから設計し、Googleのデータ・センター内にあるTPU で最適に稼働されるようにした。TensorFlowは深層学習アプリケーションに有効に機能するように設計されている。Googleは必ずしもCloud TPUとTensorFlowの垂直統合型を目指しておらず、TensorFlowはオープンソースであり、通常のCPUやNVIDIAのGPUもサポートしている。
2.5 MS Catapult FPGA
マイクロソフトも機械学習チップの分野に同様の強い投資をしている。FPGAである。FPGAはチップ内部のロジックを書き換えることで特定の処理を汎用マイクロプロセッサより非常に高速に処理できる汎用LSIである。Microsoftは機械学習のための演算リソースをこのFPGAで提供しようとしている。FPGAはさまざまなタイプの機械学習モデル用に再構成できる。この「柔軟性」により、最適な数値精度とメモリモデルに基づいて機械学習アクセラレーションが可能になる。
Project CatapultはMicrosoftのクラウドに大規模なFPGAを適用するプロジェクト。2010年にMicrosoft Research NExTのDoug BurgerとDerek Chiouが”ポストCPU”のテクノロジーとしてGPU, FPGA, ASICを模索するところから始まった。MicrosoftはFPGAがカスタムASICを開発するコスト、複雑さ、およびリスクなしに、効率と性能を実現できるという判断をした。
Doug Burgerによると、2015年後半には、Microsoftが購入したほぼすべての新しいサーバーにCatapult FPGAボードを載せていた。それはBing、Azureなどに活用された。その後は規模を拡大し、世界中に展開されるようになり、Microsoftは地球上で最も多くのFPGAを使用しているという。
このFPGAはIntelが製造している。Project Catapultのなかで機械学習に特化した部分を"Project Brainwave"と呼ぶが、「”リアルタイム”の推論の要求に対して低いレイテンシを達成することを可能にする」とうたっている。Project Brainwaveは推論のための演算能力を提供し、学習の面倒はみないのだ。BrainwaveのFPGAはビデオ、センサー、検索クエリなどのライブデータストリームを処理し、ユーザーに迅速にデータを配信するように設計されている。Microsoftはエッジでの処理を強調し、IoTへの対応を強調している。「世界中にある15億台のWindows端末もひとつのエッジデバイスと考えていて、Windowsにも機械学習を動かすためのランタイム環境を今年の秋から正式に入れていく」。

今年4月にMicrosoftは「Azure Sphere」を発表している。”エッジ”デバイス向けのソフトウェアとハードウェアスタックであり”Intelliginence Edge”を達成するものだという。Azure Sphereは組み込み用のマイクロコントローラーユニット(MCU)、IoTセキュリティ向けに構築されたカスタムOS、デバイスを保護するクラウドセキュリティサービスから構成される。
CVP Microsoft Azure の Julia Whiteは4月の公式ブログで「MicrosoftはIoTに50億ドルを投資する」と書いている。Whiteが引用するA.T. Kearneyの予測によると、IoT は2020年までに1兆9000億ドル相当の生産性改善と1770億ドル相当のコストカットをもたらしうると指摘している。
Googleもこれに対しEdge TPUを外販すると発表している。Edge TPUはIoTデバイス、ゲートウェイ、エッジコンピューティングデバイスなどを対象としている。SOM(System on Module)という形状のモジュールで顧客に提供される。OMには、クアッドコアのArm CPUとGPUを内蔵したSoC、Edge TPU、Wi-Fi、Microchipのセキュアエレメントが搭載されている。

Edge TPUはエッジでTensorFlow Liteの機械学習モデルを動かすために設計された専用ASICチップ。「ワットあたりのパフォーマンス」と「1ドルあたりのパフォーマンス」を最適化するために集中しているという。Edge TPUはCloud TPUを補完するように設計されている。クラウドでMLトレーニングを加速し、エッジで驚異的な機械学習の推論を実現する。センサーはデータコレクター以上のものになり、ローカルでリアルタイムでインテリジェントな意思決定を行う。
同時に発表したCloud IoT Edgeは、Google Cloudのデータ処理と機械学習機能をゲートウェイ、カメラ、およびエンドデバイスにまで拡張し、IoTアプリケーションをよりスマートに、より安全に、より信頼性の高いものにするソフトウェアだという。
両者とも用語やその言葉の対象範囲が異なるが、概ねエッジまでクラウドのコンピューティング能力を拡張し、重要性の増す機械学習機能をハードとソフトの両面で提供しようとしている。
Googleは機械学習のリソースを”民主化”するアプローチをとっている。TPUではデータセンターのコストセンターである電力を節約できることを強調しているし、ASICは一度製造を開始すればコストは低減する。コストパフォーマンスで差をつけて、競争相手を押し出してしまおうとしているように見える。
なぜ、両者が機械学習用のチップを開発し、クラウドからエッジに資源を拡張するのか。そこにはIoT、エッジコンピューティングというバズワードが存在する。
2.6 Cloud and Edge
近年のインターネットはテックジャイアントが運営するクラウドに集中してきた。コンピューティングは集中と分散の振り子であり続けた。メインフレームコンピュータの集中、1980年〜2000年まではクライアントサーバーの分散を経て、この10年以上はモバイル-クラウドの集中の季節にある。例えば、モバイルアプリケーションの大半はクラウド構築されており、遠隔地のデータセンターからあなたのデバイスにデータが渡されている。クラウドには様々な類型があるが、大規模運営者はAmazon, Microsoft, Googleなどに絞られる。
IoT時代には多量のセンサがネットワークに接続される。センサからは多量のデータが生まれるが、それをクラウドに運ぶことはネットワークの能力を超過する。センサデータのほとんどが非構造化データであり価値密度が低いとされるため、クラウドに運ぶ経済的利点も薄い。データをデータ源そのものか、近接した場所で処理する、クラウドへの集中化からエッジへの展開が企図されている。
IntelのFPGAでDNNを走らせるオブジェクト検出に関するブログ”High-throughput Object Detection on Edge Platforms with FPGA”では、エッジプラットフォームが必要な理由としていかが挙げられている。IntelはMicrosoftへのFPGAのサプライヤーである。
- クラウドへの接続が低速または信頼できない:特定の状況では、リアルタイムの解析とセンサデータへの対応する応答が必要だ。低速または信頼性の低いネットワーク接続性が存在することは、そのようなシステムの適切な機能を著しく妨げることになる。
- 収集される膨大なデータ:厳密なリアルタイムレスポンスが不要な状況であっても、大量のデータをクラウドに送信することは実用的でないか、高価すぎる可能性がある。例えば、監視カメラのシステムは、膨大な量の生画像フレームを収集することができる。このデータのすべてをクラウドに送ることが期待されるのは、これらのフレームのうちのほんの少数に関心のあるオブジェクトがあれば、実用的でないか無駄になる可能性がある。
- 顧客データのプライバシーとセキュリティ:収集された特定のデータは秘匿が求められており、その機密性は顧客のビジネスにとって不可欠。このような場合、インターネットを介してそのようなデータの送信を回避できると、攻撃面が大幅に減少し、より良いセキュリティが提供される。
機械学習はエッジの力を解放した。組み込みコンピュータがその場でデータ処理をする。クラウドは機械学習の学習の場、ストレージとして役割が強くなる。Teslaはとてもいい例であり、多量のコンピュータを積んでおり、デバイス自体でセンシングと推論、アクションを全部行っている。
センサーの増加は指数関数的でありユビキタスになっている。同時にセンサーの質自体も向上している。IDCは、接続されたデバイスから生成されるデータの総量が2025年までに40兆ギガバイトを超えると予測している。センサーデータはクラウドの能力を完全に越えることになる。
エッジコンピューティングは、重要なデータをローカルで処理または保存し、処理したデータを100平方メートルの領域をカバーするクラウドストレージリポジトリにプッシュする「データセンターのメッシュネットワーク」と表現することもできる。
エッジコンピューティングは次世代5Gセルラーネットワークと親和性がある。通信プロバイダーがワイヤレスネットワークに5Gを組み込むと基地局とは別に5G用のタワーを増やし、隣接するマイクロデータセンターを追加すると予測される。顧客はタワー内のスペースを所有または借りて(コロケーション)、独自のマイクロデータセンターを置くだろう。彼らはエッジ・コンピューティングを行い、通信事業者の広範なネットワークへのゲートウェイに直接アクセスしたり、パブリッククラウドに接続したりすることができる。Microsoft, Googleのようなパブリッククラウド業者も激増するIoTデバイスに対応するため、データセンターの外側にマイクロデータセンターを増やし、エッジに近づいてこようとするだろう。
IoTには未解決のセキュリティ課題が存在する。ノードの爆発的な拡大のせいでアタック対象が急増し、無数の脆弱性が生まれる。物理的なセキュリティ課題もあるクラウドでは物理的なセキュリティをデータセンターの一箇所に集中して管理できたが、分散すれば分散するほど、警備するコストが上がると考えられる。また、エッジでデータがレイテンシなく共有され、エッジデバイスが自律的な行動と協調行動をとることは必要不可欠だ。
エッジコンピューティングの経済は少しずつ担保されつつある。エッジの機械学習チップとネットワークの進化により、エッジコンピューティングのコストは急速に低下していくはずだ。電力コストを強調するTPUからは、エッジコンピューティングを安くし、”水”や”電気”のようなものにしようという目論見が見える。
3. 5G
2020年頃に日韓中米などで投入される5Gユースケースは、3つの主要なタイプの接続サービスに大きく分類される。
- 拡張モバイルブロードバンド:5Gはスマートフォンをより良くするだけでなく、より速く均一なデータレート、低い待ち時間、1ビット当たりのコストで、VRやARなどの新しい没入型エクスペリエンスを導く
- 超高信頼コミュニケーション:5Gは、クリティカルなインフラストラクチャ、車両、医療処置のリモートコントロールなど、超信頼性/可用性、低レイテンシのリンクを持つ業界を変革できる新しいサービスを可能にする
- 大規模なインターネット:5Gは、データレート、パワー、モビリティをスケールアップして、非常にリーン/低コストのソリューションを提供することにより、膨大な数のエンベデッド・センサーをすべてにシームレスに接続する。
5Gは前方互換性の設計がされている。期待されるサービスを柔軟にサポートするという。5Gは世界を超高速大容量の「メッシュ」で包み込み、そこでは、マシン、オブジェクト、およびデバイスを相互接続して制御し合う。産業へのインパクトの推定は大きすぎて難しい。小売から教育、交通機関、エンターテイメント、そしてその間のあらゆるものに至るまで、幅広い業種を再定義する可能性が生まれる。自動車と電気のような社会を大きく変える可能性がある技術なのだ。
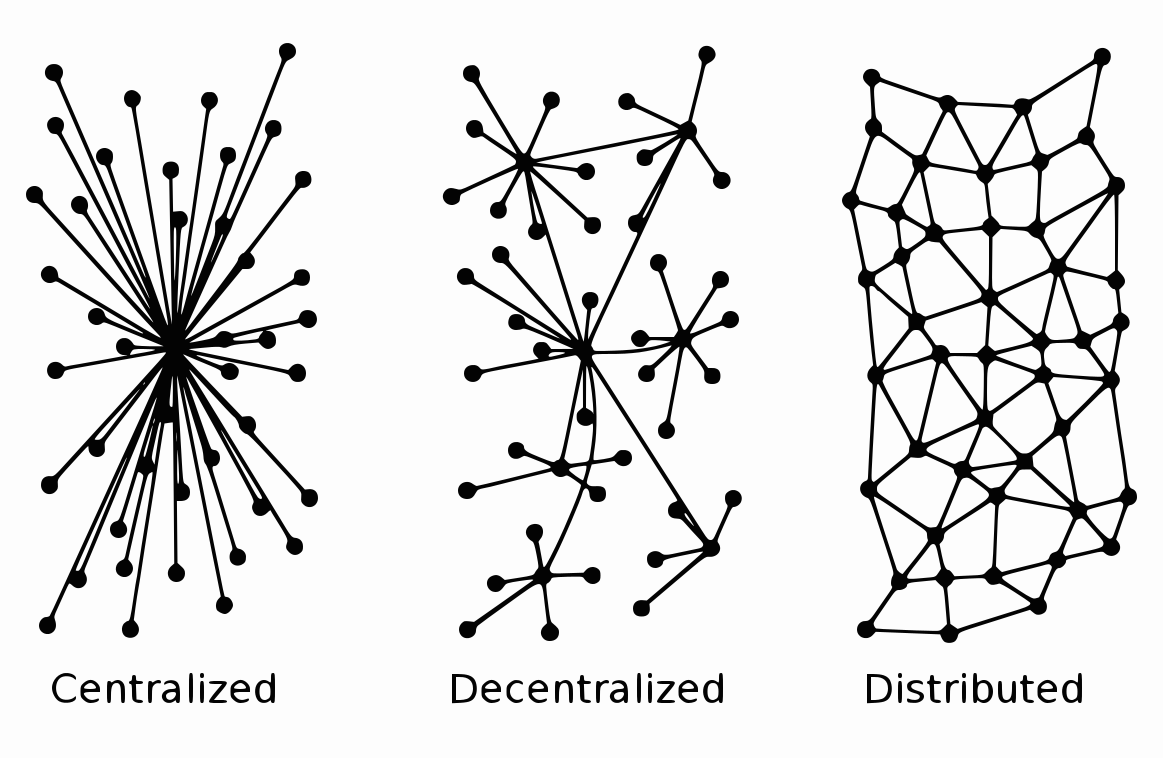
3.1 分散協調
端末の地点にあるモデルが自律的にデータを処理し、アクションを起こすことを機械学習は可能にしている。5Gの発達により自律機械(Autonomous Machines)たちを結びつけるネットワークが強くなる。自律機械たちが自律的な行動をとりながら、学習内容や情報を共有しながら協調するようになるのが理想的だ。エッジは価値密度を固めたデータをクラウドに渡し、クラウド側で得られた学習内容が、再度エッジに反映されることで、エッジの進化が続いていく。自律的に意思決定するエッジに対し、クラウドが情報を与えることで、エッジの意思決定の質が向上し、人間がその性能向上を享受できる。
クラウドに集中しているのでもなく、それぞれがばらばらに自律的に動いているのでもなく、集中と分散を細やかに組み合わせたより複雑化された形のコンピューティングが指向されている。下の図は必ずしも適切ではないが、わかりやすくなればいいと貼ってみた。
3.2 自律自動車と5G
自律機械の端的な例であり、大規模な投資がされている分野が、自動走行車だ。自動走行車は大量のセンサーとその情報を処理するためのコンピューティングパワー、そして即時の意思決定がされている。
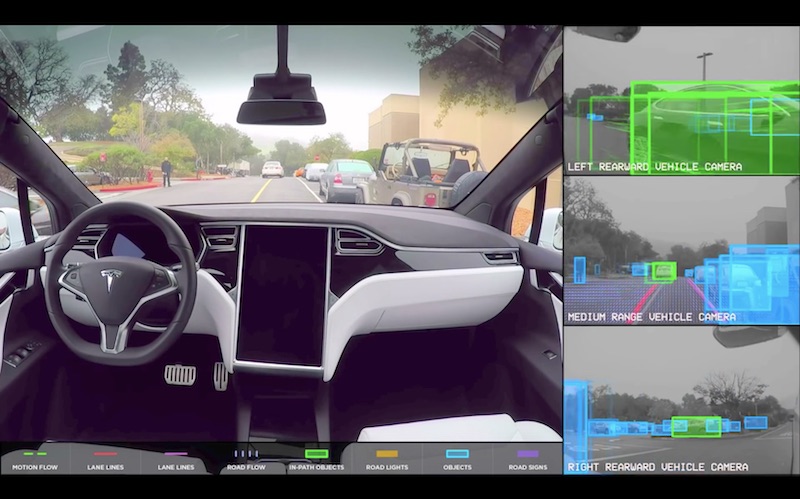
自動運転車には5Gの応用範囲が存在する。それは Vehicle-to-Vehicle (V2V) の通信である。自動運転車同士が通信をとることで、追突を避けたり、効率的な走行で化石燃料の消費を抑制し輸送機関全体のパフォーマンスを向上させたりし、円滑な交通運営が可能にする。
V2X(Vehicle-to-Everything)は、車車間、路車間、人車間で通信を行なう規格で、ADAS、あるいはレベル3以上の自動運転を実現するために欠かせない技術とされている。従来はV2Xの研究開発はDSRC(Dedicated Short Range Communications)というWiFiの通信形態に向けられてきた。しかし、特に欧米を中心に、DSRCから「C-V2X」と呼ばれるセルラーネットワークを利用したV2Xへ移行する動きが急速に進んでいる。5Gは現在のセルラーネットワークよりもはるかに帯域幅の広い周波数帯を使用するため、理論的には、今日よりもはるかに高速に大量のデータを交換できる。C-V2X搭載車が意図する行動を、周囲を走行する他のC-V2X車に事前に伝え、自律走行を支援することができる。
センサデータの処理要件は極めてシビアであり少しでもレイテンシがあると事故が起きてしまうかもしれない。したがってクラウドに分析・意思決定の場を置くことは考えられない。リアルタイムの遠隔地との通信は渋滞情報などの提供に絞られる。機械同士をつなぐ通信が重要視される。このように機械同士がつながることをM2M(Machine to Machine)と表現されている。
3.3 汎用ロボティクス
自律機械の応用例は無数に現れている。ドローンは5Gの多接続と低遅延によって同時稼働台数を増やし、活動範囲を広げることができる。加えて、ドローンは”空飛びコンピュータ”の役割を果たす。宅配のような物流への応用のほか、カメラを搭載し機体でデータ処理・分析を行い有益な情報だけを中央に送ったり、具体的なアクションをとったりするだろう。産業用ロボットはこれまでも製造業者の需要が大きく、今後は生産ラインの無人化がより一般的になる。他にもハウスキーピングや料理などを行うロボットが熱心に開発されている。
現在のヒューマン・コンピュータ・インターフェイス(HCI)は過度にスクリーンに依存しているが、ロボットとのコミュニケーションでは、多様化が考えられる。実際、物理的なロボットではなく、Google Assistantのようなバーチャルなエージェントに対して音声インターフェイスを使うことはすでに一般的だ。掃除ロボットに「キッチンの掃除をしておいて」と音声で伝えると、ロボットは主人の意図を識別し、仕事をするというふうに。
機械学習はロボッティクスの可能性を切り開いている。その最終的な目標は人が必要とするあらゆる要件を実行できる汎用ロボットだ。モデルをトレーニングするために豊富な高質のデータが必要になるが、このデータ量の要件が機械学習の社会実装のボトルネックになっている。この数年の間で、少ないデータで質の高いモデルをつくることは、機械学習関係者の共通の目標になっている。Deep MindのAlphaZero / Alpha Go Zeroは典型例である。AlphaZero / Alpha Go ZeroはそれまでのAlpha Goとは異なり、囲碁などのルールのみを設定したあとは、訓練データなしの強化学習で、人間よりはるか上のレーティングを達成したのだ。
3.4 VR・AR・MR
5GはVR(仮想現実)、AR(拡張現実)、MR(現実と仮想現実の融合)の社会実装を促進することが期待されている。使途はゲーミング、エンタテイメントだけでなく科学研究、医療、商品開発、ファッションなどの分野で活用が考えられる。
VR・AR・MRのなかで最も早そうで一般層に訴えるのはARと考えられるが、ARでも現状は大きな筐体のハードウェアとくっついていないと、描画が追いつかない。派手なプロモーション映像や『マトリックス』の有名な「バレットタイム」の考案・製作者を仲間に入れているMagicLeapの最初のハードウェアも”まだまだ”だと言われている。
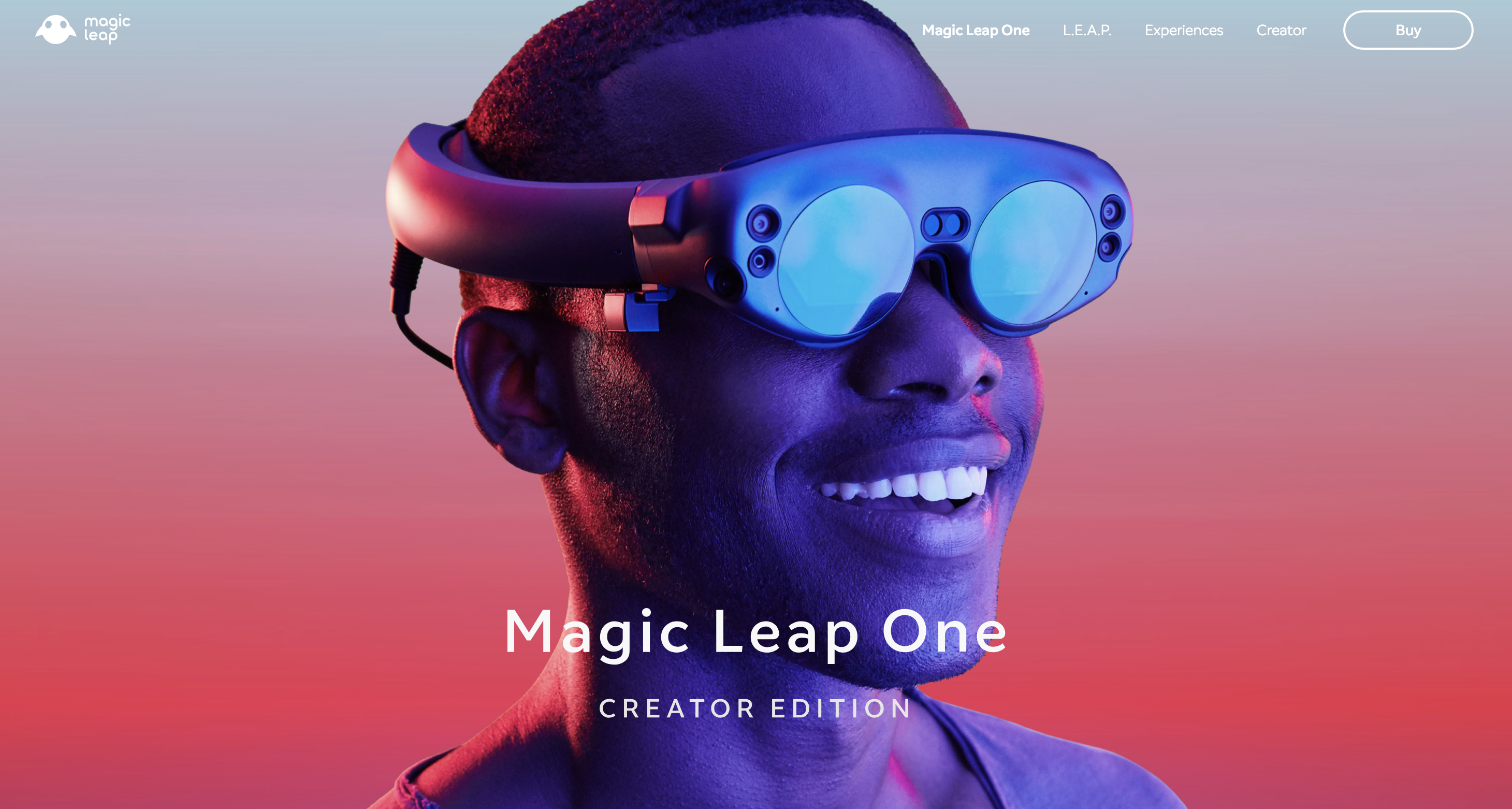
5GがARのデータを送付するのに耐えられるほどの大容量だとしても、それが大ぶりなハードウェアと接続されていないといけないので、ワイヤレスネットワークを使う楽しみがなくなる。幸いなことにGPUの性能改善はいまのところ停滞していないので、いずれは人々が街なかでARをいじり、さまざまなことを片付け、エンタテイメントを楽しむ用になるはずだ。『マイノリティ・リポート』のトム・クルーズのような人がたくさんいるようになる。
スクリーンに偏るHCIを多様化していくことが、AR / VR / MR に期待されている。モバイルフォンは多様化したデバイスたちのうちの一つとなる。メッシュのようにネットワークに接続し、ロボットなどを駆使するようになったときには、モバイルがいまのように人の可処分時間を占めることは難しくなるだろう。
モバイルフォンには「カメラ」としての役割があるので、それがモバイルフォンをこの世界にとどまらせ続ける可能性がある。特に若年層にとって、モバイルフォンは動画と画像の生成と視聴のためのデバイスとしての価値が大きくなっている。ビデオの視聴はARデバイスに移行されるが、撮影機能は電話に残存する可能性がある。Go Proのようにカメラが独立した形でのユースケースになるか、未来のマーケットが答えを出すだろう。それにしても「電話がカメラとして生き残る」のは変な感じだ。
4. 結論
ぼくたちはコンピュータとそのネットワークの大きな変化を前にしている。モバイルは強烈な一点突破の拡張だったが、今後は追いかけてくる様々な要因がそれを押し広げ、目まぐるしいくらい多様化するだろう。モバイルの崩壊というわけではなく、新興国ではインターネットとコンピューティングのゲートウェイドラッグになるし、富裕国でも一定の地位を残すはずだ(少なくともそれは電話という形ではない。カメラが有望だ)。自律的に働く機械が人間の周辺で増え「human in the loop(人と関与する)」で発展するだろう。さまざまな仕事を機械に委託することで、生産性が高いことに使う時間が増えていく。
分散協調する自律的な機械により物事が行うことで、ぼくたちの社会は驚異的な生産性を生み出す。未来では、これまでの集権的なコンピューティングでは想定できなかったことが生まれてくるはずだ。
経済は爆発的な発展を遂げ、資本主義の次の経済原理をつくることに議論が向かう、ということも、コンピューティングの変化が影響する範囲に入るかもしれない。ぼくたちとの機械とのふれあい方は極めて多様化していく、モバイルフォンの小さいスクリーンではなく、AR / VR / MR や音声に多様化する。ぼくたちは変化たち自分たちの能力拡張をもたらしてくれることを力強く実感する。
参考文献
- 機械学習用チップの性能評価 : TPU の研究論文を公開
https://cloudplatform-jp.googleblog.com/2017/04/quantifying-the-performance-of-the-TPU-our-first-machine-learning-chip.html?m=1 - New AIY Edge TPU Boards
https://developers.googleblog.com/2018/07/new-aiy-edge-tpu-boards.html - FPGA+Edge Computing High-throughput Object Detection on Edge Platforms with FPGA
https://ai.intel.com/high-throughput-object-detection-on-edge-platforms-with-fpga/ - Cloud Tensor Processing Units (TPUs)
https://cloud.google.com/tpu/docs/tpus - Dave Patterson, on TPU
https://youtu.be/fhHAArxwzvQ - FPGA
https://www.microsoft.com/en-us/research/blog/clouds-catapults-life-end-moores-law-dr-doug-burger/ - Azure Sphere
https://azure.microsoft.com/en-us/blog/introducing-microsoft-azure-sphere-secure-and-power-the-intelligent-edge/
ここまで読んでくれた人、どうもありがとうございます。食事、お茶などでお話したい人はぜひ @taxiyoshida まで。いま共同創業者、メンバーを募集しています。



