ロボットの空間知覚は可能か?
MIT航空宇宙学助教授ルカ・カルローンらは人間が世界を知覚し、ナビゲートする方法をモデルにした、ロボットのための空間知覚の表現を開発した。ロボットは、人、部屋、壁、その他の構造物などのオブジェクトとその意味的ラベルを付け、ロボットがその環境で見ているであろうものを含む周囲の3Dマップを素早く生成する。


要点
MIT航空宇宙学助教授ルカ・カルローンらは人間が世界を知覚し、ナビゲートする方法をモデルにした、ロボットのための空間知覚の表現を開発した。ロボットは、人、部屋、壁、その他の構造物などのオブジェクトとその意味的ラベルを付け、ロボットがその環境で見ているであろうものを含む周囲の3Dマップを素早く生成する。
ロボットのための「空間知覚」
家の周りでちょっとした手助けをしてくれるとありがたいと思わないだろうか。マサチューセッツ工科大学(MIT)のエンジニアは「キッチンに行ってコーヒーカップを取ってきて」などの高レベルの指令に従うことができる、ホームヘルパーのようなロボットを想定している。そのような高度なタスクを実行するためには、人間と同じように物理的な環境を認識できるロボットが必要になると研究者は考えている。
MIT航空宇宙学助教授ルカ・カルローン(Luca Carlone)と彼の学生たちは、人間が世界を知覚し、ナビゲートする方法をモデルにした、「ロボットのための空間知覚」の表現を開発した。この新しいモデルは、彼らが「3D Dynamic Scene Graphs」と呼んでいるもので、ロボットは、人、部屋、壁、その他の構造物などのオブジェクトとその意味的ラベル(例えば、椅子とテーブルの違いなど)付けをし、ロボットがその環境で見ているであろうものを含む、周囲の3Dマップを素早く生成することができる。
また、このモデルでは、ロボットは3Dマップから関連情報を抽出し、オブジェクトや部屋の位置、またはパス内の人の動きを照会することができる。このように環境を圧縮して表現することで、ロボットは迅速に意思決定を行い、進路を計画することができるので便利だ。
これは、私たちが人間として行っていることとあまりかけ離れたものではない。自宅から職場までの経路を計画する必要がある場合、必要な位置をすべて計画することはない。通りや経由地について先に考えておくだけで、より早くルートを計画するのに役立つ。
カルローンによると、この新しいタイプの環境のメンタルモデルを採用したロボットは、家事のヘルパー以外にも、工場の現場で人と並んで作業したり、被災者のために災害現場を探索したりするような、他の高レベルの仕事にも適しているかもしれないという。
3Dマッピングと意味論的セグメンテーション
現在、ロボットのビジョンとナビゲーションは主に2つのルートで進歩している。1つは、ロボットがリアルタイムで探索する際に環境を3次元で再構築することを可能にする3Dマッピング、もう1つは、ロボットがその環境の特徴を、車と自転車のような意味的なオブジェクトとして分類するのを助けるセマンティックセグメンテーションである。
カルローンと論文の主著者でMIT大学院生のAntoni Rosinolの空間知覚の新しいモデルは、リアルタイムで環境の3Dマップを生成し、その3Dマップ内のオブジェクト、人(オブジェクトとは逆に動的である)、構造物をラベル付けした初めてのモデルである。
論文のなかで言及されている「キメラ(Kimera)」は、神話上の生き物のように、2つの性質を具有したものだ。それは以前、Rosinolが開発したオープンソースのライブラリで、環境の3D幾何学的モデルを同時に構築すると同時に、物体が例えば椅子と机のどちらであるかをエンコードするためのものである。ロボットのカメラからの画像のストリームや、車載センサーからの慣性計測を取り込むことで、ロボットやカメラの軌跡を推定し、シーンを3Dメッシュとして再構築し、すべてリアルタイムで動作する。
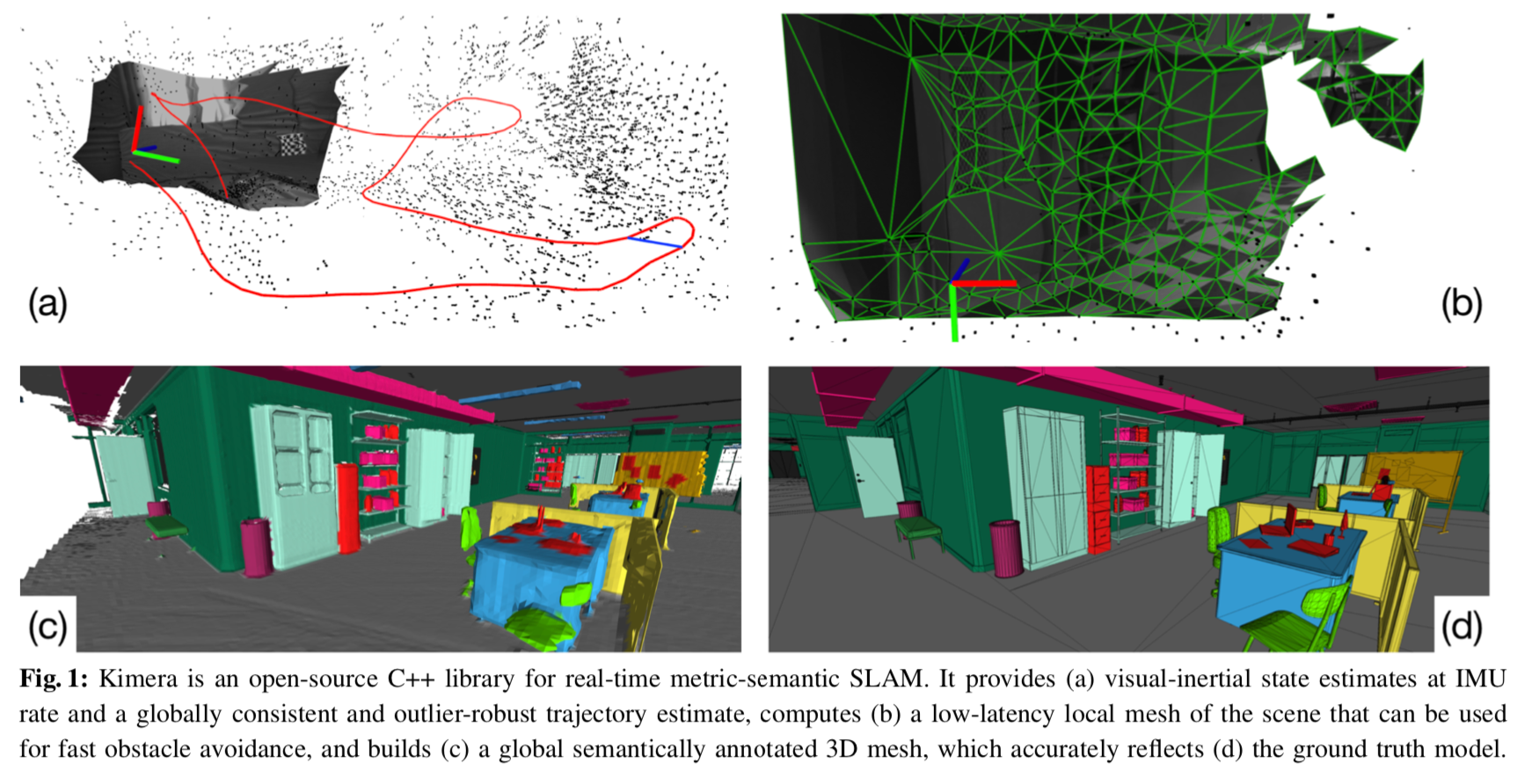
意味的な3Dメッシュを生成するために、キメラは何百万もの実世界の画像で訓練された既存のニューラルネットワークを使用して各ピクセルのラベルを予測し、リアルタイムレンダリングのためのコンピュータグラフィックスで一般的に使用されるレイキャスティングとして知られる技術を使用して、これらのラベルを3Dに投影する。その結果、ロボットの環境のマップは、密な3次元メッシュに似ており、各顔は環境内のオブジェクト、構造物、および人の一部として色分けされているという。
ロボットが風景のレイヤー化を通じて「見る」
ロボットが環境をナビゲートするためにこのメッシュだけに頼っていたとしたら、それは計算量が多く、時間のかかる作業になるだろう。そこで研究者たちは、キメラの初期の高密度な3Dセマンティックメッシュから3Dダイナミックな「シーングラフ」を構築するアルゴリズムを開発した。
シーングラフは、複雑なシーンを操作してレンダリングする一般的なコンピュータグラフィックスモデルであり、一般的にビデオゲームエンジンで3D環境を表現するために使用されている。
3Dダイナミックシーングラフの場合、関連するアルゴリズムは、キメラの詳細な3Dセマンティックメッシュを抽象化したり、分解したりして、ロボットが特定のレイヤー(レンズ)を通してシーン(風景)を「見る」ことができるように、異なるセマンティックレイヤーに分割する。
レイヤーは、オブジェクトや人物から、壁や天井などのオープンスペースや構造物、部屋、廊下、ホール、そして最終的には建物全体へと階層的に進行していく。このレイヤー化された表現により、ロボットが元の3Dメッシュ内にある何十億もの点や顔を理解しなくても済むという。
また、物体と人のレイヤーの中で、研究者たちは、環境の中の人の動きや形をリアルタイムで追跡するアルゴリズムを開発することもできた。
これは、自動運転車、捜索救助、共同製造、家庭用ロボットなど、多くのアプリケーションに影響を与える可能性がある。もう1つの領域は、仮想・拡張現実(AR)だ。このアルゴリズムを実行するARゴーグルを装着すると、ゴーグルは「赤いマグカップをどこに置いてきたか」「一番近い出口はどこか」などの質問に答えてくれる可能性がある。あなたの周りの環境を認識し、物体や人間、その関係性を理解している機械知性と考えるのが適切かもしれない。
参考文献
- A. Rosinol, T. Sattler, M. Pollefeys, L. Carlone. Incremental Visual-Inertial 3D Mesh Generation with Structural Regularities. IEEE Intl. Conf. on Robotics and Automation (ICRA) (2019).
- Antoni Rosinol, Marcus Abate, Yun Chang, Luca Carlone. Kimera: an Open-Source Library for Real-Time Metric-Semantic Localization and Mapping. IEEE Int. Conf. Robot. Autom. (ICRA), 2019.
- 太田 英司. セマンティック・セグメンテーションの基礎.



