模倣学習で動物のような動きを学ぶロボット
Googleの研究者たちは、模倣学習を利用して、自律型四足歩行ロボットにペースや回転、より機敏な動き方を教えた。センサーから記録されたモーションキャプチャデータのデータセットを使用して、従来のロボット制御では実現が困難な、いくつかの異なる動きを教えた。https://www.axion.zone/robots-learning-to-move-like-animals/


要点
Googleの研究者たちは、模倣学習を利用して、自律型四足歩行ロボットにペースや回転、より機敏な動き方を教えた。センサーから記録されたモーションキャプチャデータのデータセットを使用して、従来のロボット制御では実現が困難な、いくつかの異なる動きを教えた。
最初に、彼らは犬のトロット、サイドステップ、および古典的な80年代のダンス「The Running Man」の犬のバージョンを含む各操作のシミュレーションを構築するために実際の犬からの動きのデータを使用しました。次に、シミュレーションされた犬とロボットの主要な関節を一致させ、シミュレーションされたロボットが動物と全く同じように動くようにしました。そして、強化学習を使って、動きを安定させ、体重配分やデザインの違いを修正することを学習しました。最終的に、研究者たちは最終的な制御アルゴリズムを実験室の物理的なロボットに移植することができましたが、人間が走るような動きは完全には成功しませんでした。
フレームワーク
研究チームが採用したフレームワークは、モーションリターゲティング、モーションイミテーション、ドメインアダプテーションの3つの主要な構成要素から構成されています。
- まず、参照運動が与えられると、運動リターゲティング段階では、元の動物の形態からロボットの形態へと運動をマッピングします。
- 次に、運動模倣段階では、再対象化された参照運動を用いて、シミュレーションで運動を模倣するためのポリシーを訓練します。
- 最後に、領域適応段階では、シミュレーションからサンプル効率的な領域適応プロセスを経て、実際のロボットに方針を伝達します。
本研究では、このフレームワークを応用して、ライカゴ四足歩行ロボットの様々な俊敏な運動スキルを学習しています。
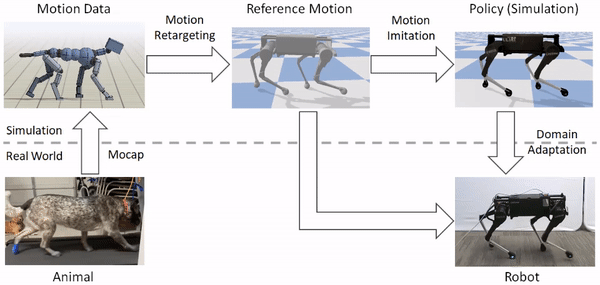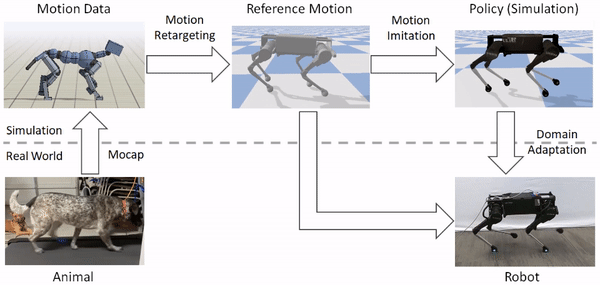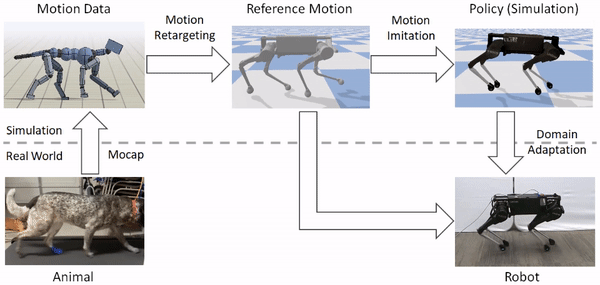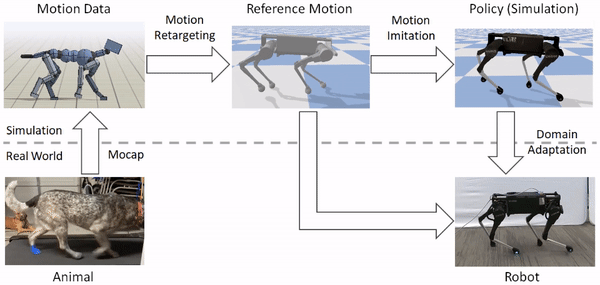
モーションリターゲティング
動物の体は、一般的にロボットの体とは大きく異なります。そのため、ロボットが動物の動きを模倣する前に、まずロボットの身体に動きをマッピングしなければなりません。リターゲティングプロセスの目標は、動物の動きの重要な特徴を捉えたロボットの基準となる動きを構築することです。これを行うために、まず、腰や足などの動物の体のソースキーポイントのセットを特定します。次に、ロボットの身体上に対応するターゲットキーポイントを指定します。

次に、逆運動学を用いて、各タイムステップで動物からの対応するキーポイントを追跡するロボットの基準運動を構築します。
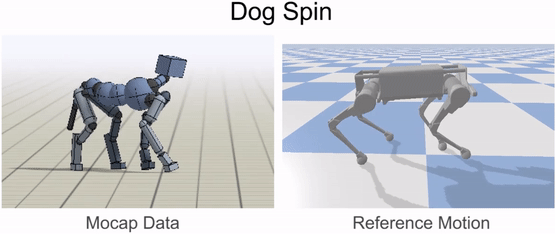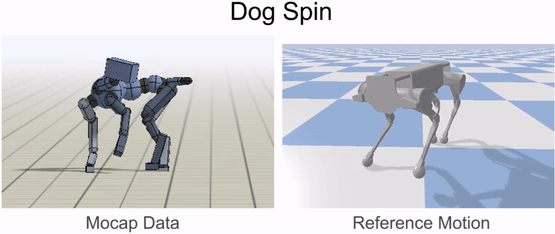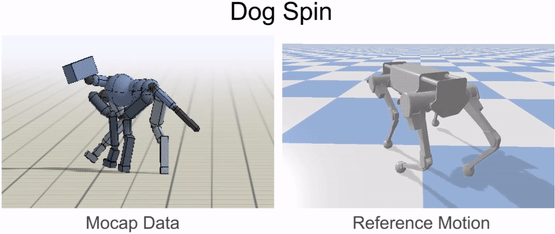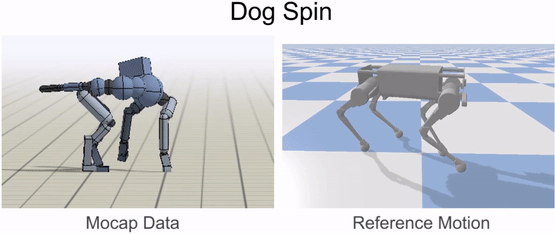
基準運動をロボットにリターゲットした後、次のステップは、リターゲットした運動を模倣する制御方針を訓練することです。しかし、強化学習アルゴリズムは効果的な制御方針を学習するのに時間がかかり、実際のロボットで直接訓練するのはかなり危険です(ロボットと人間の仲間の両方にとって)。そこで、我々は代わりに、訓練の大部分をシミュレーションの快適さの中で実行し、学習したポリシーをよりサンプル効率の良い適応技術を用いて実世界に転送することを選択します。すべてのシミュレーションはPyBulletを用いて行われます。
領域適応
シミュレータは一般的に現実世界の粗い近似値しか提供しないため、シミュレーションで訓練されたポリシーは、実際のロボットに配備されたときにはかなり悪い結果になることがよくあります。そこで、シミュレーションで学習したポリシーを実世界に移植するために、我々は、実ロボット上でのわずかな試行回数でポリシーを実世界に適応させることができるサンプル効率的な領域適応技術を使用します。これを行うために、まず、シミュレーションでの訓練中に、質量や摩擦などの力学パラメータをランダムに変化させる領域ランダム化を適用します。
実際のロボットにポリシーを移す際には、エンコーダを削除し、現実世界でロボットの報酬を最大化する空間を直接探索します。これは、単純なオフポリシー強化学習アルゴリズムであるアドバンテージ加重回帰を用いて行われます。我々の実験では、この手法はしばしば50回以下の試行で実世界にポリシーを適応させることができ、これは実世界のデータの約8分に相当します。
結果
このフレームワークでは,犬のように高速な回転運動だけでなく、歩幅やトロッキングなどの歩行動作も含めて、様々な運動能力を模倣したロボットの訓練を行うことができます。また、単に前方の歩行動作を後ろ向きに再生するだけで、ロボットが後ろ向きに歩くように訓練することも可能です。
本物の犬の動きを真似るだけでなく、ダイナミックなホップターンなど、アーティストがアニメーションしたキーフレームの動きを真似ることもできます。また,学習したポリシーを,メーカーから提供された手動で設計されたコントローラと比較しました.私たちのポリシーは、より速い歩行を学習することができます。
全体的に、システムは四足歩行ロボットを用いて、かなり多様な行動を再現することができました。しかし、ハードウェアやアルゴリズムの制限により、走ったり跳んだりするようなより動的な動作を模倣することはできませんでした。また、学習されたポリシーは、手動で設計された最高のコントローラほどロバストではありません。学習したポリシーの敏捷性とロバスト性をさらに向上させるための技術を探求することは、より複雑な実世界での応用に向けた貴重な一歩になるかもしれません。このフレームワークをビデオからスキルを学習するために拡張することは、ロボットが学習できるデータ量を大幅に増やすことができるエキサイティングな方向性です。
Robotics Science and Systemsのベストペーパーとなった論文の主著者であるJason Pengは、克服すべき課題がまだたくさんあると記述している。ロボットの重さは、大きなジャンプや高速走行などの特定の動作を学習する能力を制限しています。さらに、動物からモーションセンサーデータを取得できるとは限りません。莫大な費用がかかり、動物の協力が必要になります。
参考文献
- Xue Bin Peng et al. Learning Agile Robotic Locomotion Skills by Imitating Animals. Robotics Science and Systems (RSS 2020).
Image via Berkrey Artificial Intelligence Research



