Snowflakeのクラウド型DWHの仕組み
『Building an elastic query engine on disaggregated storage』(Vuppalapati et al. 2020)は、クラウドベースのデータウェアハウス「Snowflake」の背後にある設計上の決定事項について説明している。


『Building an elastic query engine on disaggregated storage』(Vuppalapati et al. 2020)は、クラウドベースのデータウェアハウス「Snowflake」の背後にある設計上の決定事項について説明している。この論文では、Snowflakeの設計と実装を、クラウドインフラストラクチャの最近の変化(新しいハードウェア、きめ細かな課金など)が、Snowflakeシステムの設計と最適化を導いた多くの前提条件をどのように変更したかについての議論とともに紹介している。本稿は、コンピュータサイエンスのカンファレンス「Networked Systems Design and Implementation(NSDI)2020」に採択された上述論文のまとめである。
Abstract
最先端のデータベースに近いSQL対応のクラウド型データウェアハウスシステム「Snowflake」の設計は、以下の3つの目標に基づいている。(1)計算とストレージの柔軟性、(2)マルチテナンシーへの対応、(3)高いパフォーマンス。ここ数年の間に、Snowflakeは、毎日何百万ものクエリを実行する何千もの顧客にサービスを提供するまでに成長し、ペタバイトのデータを扱うようになった。この論文では、Snowflakeの設計と実装を紹介するとともに、クラウドインフラストラクチャにおける最近の変化(新たなハードウェア、きめ細かな課金など)が、Snowflake システムの設計と最適化の指針となっていた多くの前提条件をどのように変化させたかについて議論する。14日間で7000万件のクエリを実行した際に、システムの様々なコンポーネントから収集したデータを使用して、既存の問題の理解を深めると同時に、ストレージシステムや高性能クエリ実行エンジンの設計など、様々な次元での新たな研究課題を浮き彫りにした。
シェアード・ナッシングからディスアグリゲーションへ
シェアードナッシングアーキテクチャは、従来のクエリ実行エンジンやデータウェアハウスシステムの基盤となってきた。このようなアーキテクチャでは、パーシスタントデータ(永続データ構造)が一連の計算ノードに分割され、各計算ノードはローカルデータのみを担当する。このようなシェアード・ナッシング・アーキテクチャにより、クエリ実行エンジンは拡張性に優れ、クロスジョブ分離とデータのロカリティを提供し、様々なワークロードに対して高いパフォーマンスを発揮することが可能になった。しかし、これらの利点は、いくつかの大きな欠点を犠牲にしている。
ハードウェアとワークロードの不一致。ハードウェアとワークロードのミスマッチ。共有型のアーキテクチャでは、コンピュートノードが提供する CPU、メモリ、ストレージ、帯域幅のリソースとワークロードが必要とするリソースとの間で完璧なバランスを取ることが難しくなる。例えば、帯域幅を重視した計算負荷の軽いバルクローディングに最適なノード構成は、帯域幅を重視した計算負荷の軽い複雑なクエリには適していないかもしれない。しかし、多くの顧客は、クエリの種類ごとに個別のクラスタを設定することなく、さまざまなクエリを実行したいと考えている。そのため、パフォーマンス目標を達成するためには、通常、リソースを過剰にプロビジョニングする必要がある。
柔軟性の欠如。たとえコンピュートノードのハードウェアリソースをワークロードの要求に合わせることができたとしても、(非弾性的な)シェアードナッシングアーキテクチャに固有の静的並列性とデータパーティショニングは、データスキュー(過度に表現された値)や時間的に変化するワークロードへの適応を制約する。例えば、当社の顧客が実行しているクエリは、中間データサイズに極端なスキューがあり、そのデータサイズは5桁以上も変化し、CPU要件は同じ時間内に1桁も変化します。リソースを弾力的にスケーリングするためにノードを追加したり削除したりする通常のアプローチでは、大量のデータを再編成する必要がある。これは、ネットワーク帯域幅の要件を増加させるだけでなく、データの再シャッフルに参加するノードのセットがクエリ処理にも関与するため、パフォーマンスの大幅な低下をもたらす。
従来のデータウェアハウスシステムは、予測可能な量とレートのデータ、例えば、組織内からのデータ(トランスアクションシステム、エンタープライズリソースプランニングアプリケーション、顧客関係管理アプリケーションなど)に対して、定期的にクエリを実行するように設計されていた。状況は大きく変化しています。今日では、データの大部分が、管理しにくい外部ソース(アプリケーションログ、ソーシャルメディア、ウェブアプリケーション、モバイルシステムなど)からのものとなっており、その結果、その場しのぎで、時間が変動し、予測不可能なクエリワークロードが発生している。このようなワークロードに対して、シェアードナッシング・アーキテクチャは、コストが高く、柔軟性がなく、パフォーマンスが低く、効率が悪いため、本番アプリケーションやクラスターの展開に支障をきたしている。
これらの制限を克服するために、私たちは、最先端のデータベースに匹敵するSQLスーパーポートを備えた、弾力性のあるトランザクション型クエリ実行エンジンであるSnowflakeを設計した。Snowflakeの設計における重要な洞察は、前述のシェアード・ナッシング・アーキテクチャの制限は、コンピュートとストレージの緊密な結合に根ざしており、解決策はこの2つを切り離すことであるということだ。顧客データは、高可用性とオンデマンドの柔軟性を提供する永続的なデータストア(Amazon S3、Azure Blob Storageなど)に格納される。計算の弾力性は、オンデマンドベースで顧客に割り当てることができる、事前に暖められたノードのプールを使用して達成される。
Snowflakeのシステム設計は、2つの重要なアイデアを使用している。第一に、クエリ実行中に計算ノード間で交換されるエフェメラル/中間データ(例:結合中に交換されるテーブル)の管理と交換のために、カスタム設計されたストレージシステムを使用している。既存の永続的なデータストアには、主に2つの制限があるため、このようなエフェメラルストレージシステムが必要だった。(1) 中間データの交換の際にコンピュートタスクがブロックになるのを避けるために必要なレイテンシとスループット性能を提供するには不十分であり、(2) 中間データに必要なものよりも強い可用性と耐久性のセマンティクスを提供する。
第二に、Snowflakeはそのエフェメラルストレージシステムを中間データのためだけでなく、永続的なデータのための書き込みスルーの「キャッシュ」としても使用している。Snowflakeは、カスタム設計されたクエリ・スケジューリング・メカニズムと組み合わせることで、コンピュ ータ・ストレージの不一致による追加のネットワーク負荷を軽減し、データの局所性の低下に伴うパフォーマンス・オーバヘッドを軽減することができる。
本研究による主な発見
Snowflakeシステムは数年前から稼働しており、現在では数千人の顧客が毎日のように数百万件のクエリを実行し、ペタバイトのデータを処理している。2018年2月の14日間の連続した期間に約7,000万個のクエリを実行中に収集した統計を使用して、Snowflakeにおけるネットワーク、計算、ストレージの特性に関する詳細な研究を提示しています。私たちの主な発見は以下の通りだ。
- 顧客が送信するクエリの種類は多岐にわたっており、例えば、読み取り専用のクエリ、書き込み専用のクエリ、読み取り/書き込みのクエリなどがあるが、これらはそれぞれ、全顧客クエリの約28%、約13%、約59%を占めている。
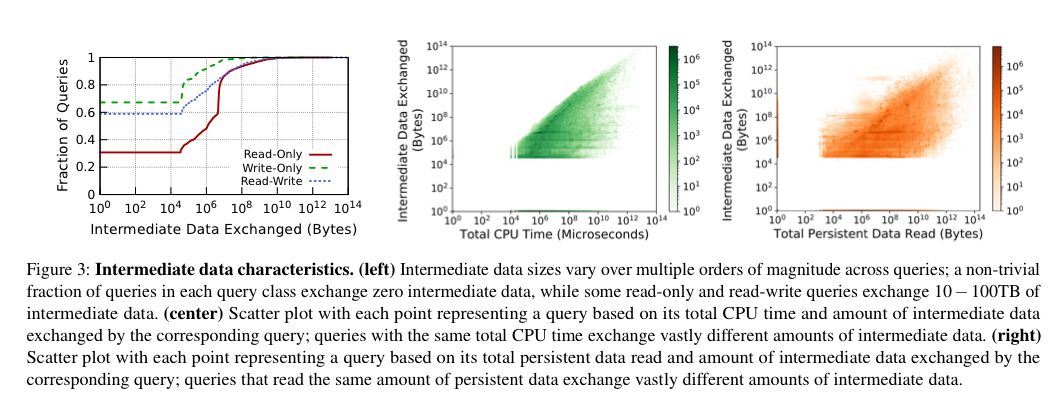
- 中間データのサイズは、クエリによっては数百ギガバイトから数テラバイトの中間データを交換するクエリもある。クエリによって生成される中間データの量は、クエリによって読み込まれる永続的なデータの量やクエリの実行時間とはほとんど相関関係がある。
- たとえローカルストレージ容量が小さくても、データウェアハウスで一般的な偏ったアクセス分布と時間的なアクセスパターンにより、永続的なデータアクセスごとの平均キャッシュヒット率がかなり高い(クエリの種類によっては60~80%)ことが可能になる。
- Snowflakeのユーザー企業の中には、当社の弾力性のサポートを利用しているお客様もいる(クラスタの約20%)。顧客がリソースの弾力的なスケーリングを要求した場合、クラスタ内のコンピュートノード数はクラスタの寿命の間に2桁も変化する可能性がある。
- 資源利用率のピークは高くても、平均的な資源利用率は低いのが普通だ。CPU,メモリ、ネットワークTx、ネットワークRxの平均利用率はそれぞれ約51%,約19%,約11%,約32%である。
この研究は、現在進行中の研究の方向性を裏付けるものであると同時に、今後の研究の方向性を示すものでもあると位置づけられた。
- コンピュートとエフェメラルストレージのデカップリング: Snowflakeは、コンピュートを永続的なストレージからデカップリングして弾力性を実現している。しかし、現在のところ、コンピュートとエフェメラルストレージはまだ密接に結合されている。研究チームの生産クラスタでは、計算容量とエフェメラルストレージの容量の比率が数桁異なることがあり、アドホックなクエリ処理のワークロードでは、CPUの利用率が低いか、エフェメラルストレージのスラッシングにつながる可能性がある。そのため、エフェメラルストレージからのデカップリング計算に関する最近の学術的研究は非常に興味深いものだ。しかし、エフェメラルストレージシステムの設計においては、特にきめ細かな弾力性、マルチテナンシー、クロスクエリ分離を提供するという点で、より多くの作業が必要とされている。
- ディープストレージ階層: Snowflake エフェメラルストレージシステムは、最近のコンピュートストレージディスアグレッションの研究と同様に、頻繁に読み込まれる永続的なデータのキャッシングを使用して、 ネットワークトラフィックを削減し、データの局所性を向上させている。しかし、キャッシングとデータロカリティを改善するための既存のメカニズムは、2層のストレージシステム(メモリをメイン層、HDD/SSDを2層目)向けに設計されたものである.本番クラスタのストレージ階層はますます深くなってきており、新たなメカニズムが必要とされている。
- サブ秒単位のタイムスケールでの価格設定。Snowflakeは、事前にウォームアップされたノードのプールを使用して顧客にサービスを提供することで、きめ細かなタイムスケールでの計算の弾力性を実現している。これは、1時間ごとの粒度でのクラウドプライシングではコスト効率が高いものだった。しかし、最近ではほとんどのクラウドプロバイダーがサブ秒単位の価格設定に移行しており、複数のテナント間でリソースの弾力性とリソース共有を効率的に実現するための新たな技術的課題が発生している。これらの課題を解決するには、Snowflakeの現在の設計とは異なる設計上の決定とトレードオフが必要となる場合がある。
この論文では、本番用クラスタで観察された計算、ストレージ、ネットワークの特性とともに、Snowflake のシステムアーキテクチャに焦点を当てている。したがって、本稿を自己完結型にするために必要な詳細に焦点を当てる。また、Snowflakeのクエリ計画、最適化、協調制御メカニズムなどの詳細については、SIGMOD 2016に採択された、『The Snowflake Elastic Data Warehouse』を参照されたい。将来の研究や研究を支援するために、本論文で使用したデータセットの匿名版を公開する。このデータセットは、本論文のすべての結果を再現するためのドキュメントとスクリプトとともにGithubに公開されている。
永続的データと中間データ
ほとんどのクエリ実行エンジンやデータウェアハウスシステムと同様に、Snowflakeには3つの形態のアプリケーション状態がある。
- 永続データは、データベース内のテーブルとして格納された顧客データ。各テーブルは、多くのクエリによって、時間をかけて、または同時に読み込まれることがある。したがって、これらのテーブルは長寿命であり、強力な耐久性と可用性の保証が必要だ。
- 中間データは、クエリ演算子(結合など)によって生成され、通常はそのクエリの実行に参加しているノードによって消費される。そのため、中間データは短命だ。さらに、中間データアクセスでノードがブロックされるのを避けるために、中間データへの低レイテンシのハイスループットアクセスは、強力な耐久性保証よりも優先される。実際、中間データの(短い)寿命の間に障害が発生した場合、中間データを生成したクエリの一部を単に再実行することができる。
- オブジェクトカタログ、データベーステーブルから永続的ストレージ内の対応するファイルへのマッピング、統計、トランザクションログ、ロックなどのメタデータ。
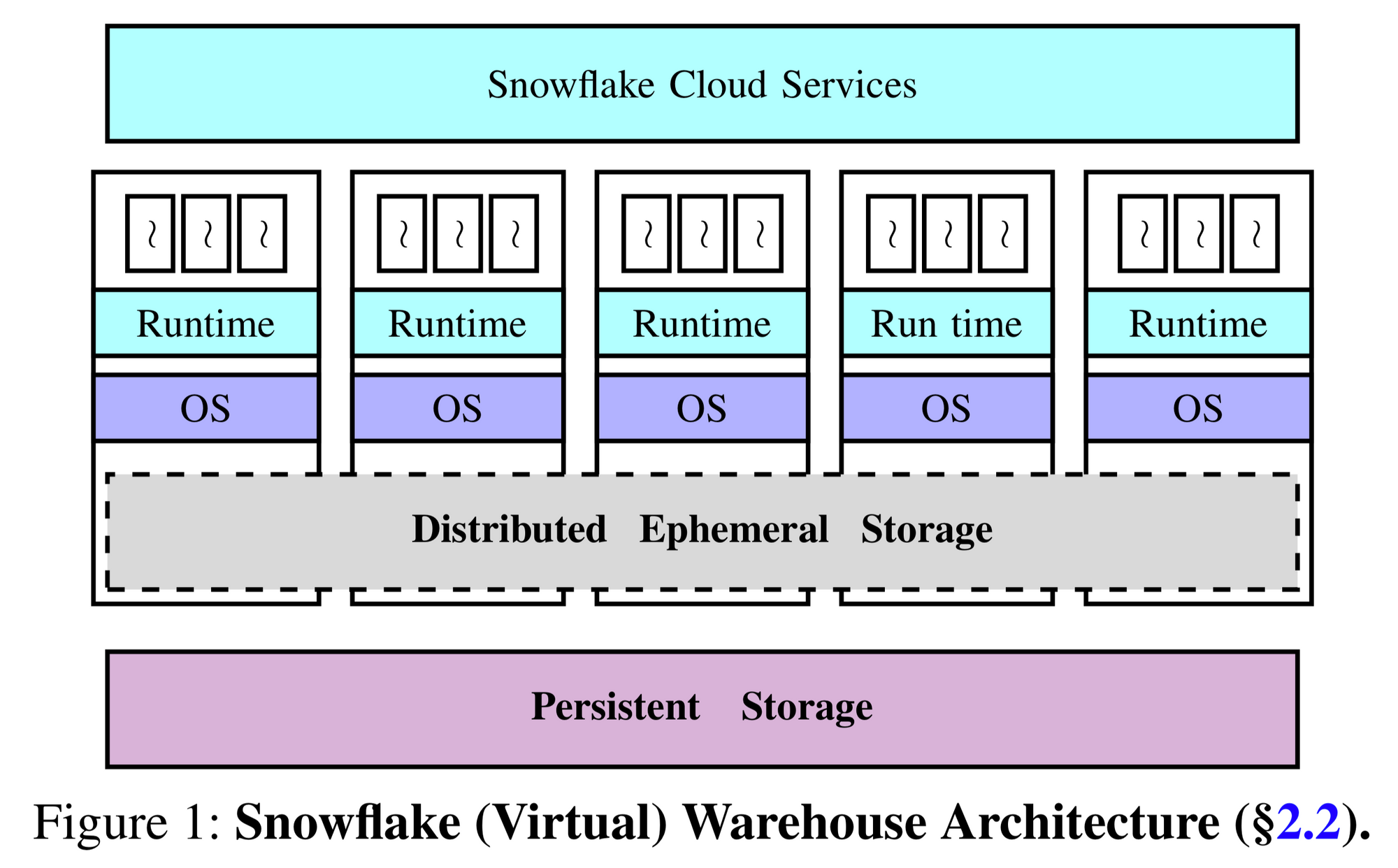
エンドツーエンドのシステムアーキテクチャ
Snowflakeのハイレベル・アーキテクチャは、エンドツーエンドのクエリ実行をオーケストレーションするための集中型サービス、計算層、分散型エフェメラルストレージシステム、永続的なデータストアの4つの主要コンポーネントから構成されている。
- クラウドサービスによる集中制御。すべてのSnowflakeの顧客は、クラウドサービス(CS)と呼ばれる集中管理レイヤと対話し、クエリーを送信する。この層は、アクセス制御、クエリの最適化と計画、スケジューリング、トランザク ション管理、同時実行制御などを担当する。CSは、高可用性とスケーラビリティを実現するために十分なレプリケーションを備えたマルチテナント型の長寿命サービスとして設計・実装されている。そのため、個々のサービスノードが故障しても状態や可用性が失われることはあるが、一部のクエリは失敗して透過的に再実行されることがある。
- 仮想ウェアハウス(VW)の抽象化による弾性計算。ユーザーは、VWの抽象化を通じて、Snowflake内の計算リソースへのアクセスが可能になる。各VWは、基本的にはAWS EC2インスタンスのセットであり、顧客のクエリが分散して高速に実行される。顧客はVWのサイズに応じて計算時間を支払う。各VWは、顧客の要求に応じてオンデマンドで弾力的に拡張することができる。細かいタイムスケール(数十秒など)での弾力性をサポートするために、Snowflakeは事前にウォームアップされたEC2インスタンスのプールを維持している。リクエストを受信したら、そのVWにEC2インスタンスを追加/削除するだけです(追加の場合は、事前にウォームアップされたインスタンスのプールから直接ほとんどのリクエストをサポートできるため、インスタンスの起動時間を避けることができる)。各VWは複数の同時クエリを実行することができる。実際、多くのお客様は複数のVW(例:データインジェスト用とOLAPクエリ実行用)を実行している。
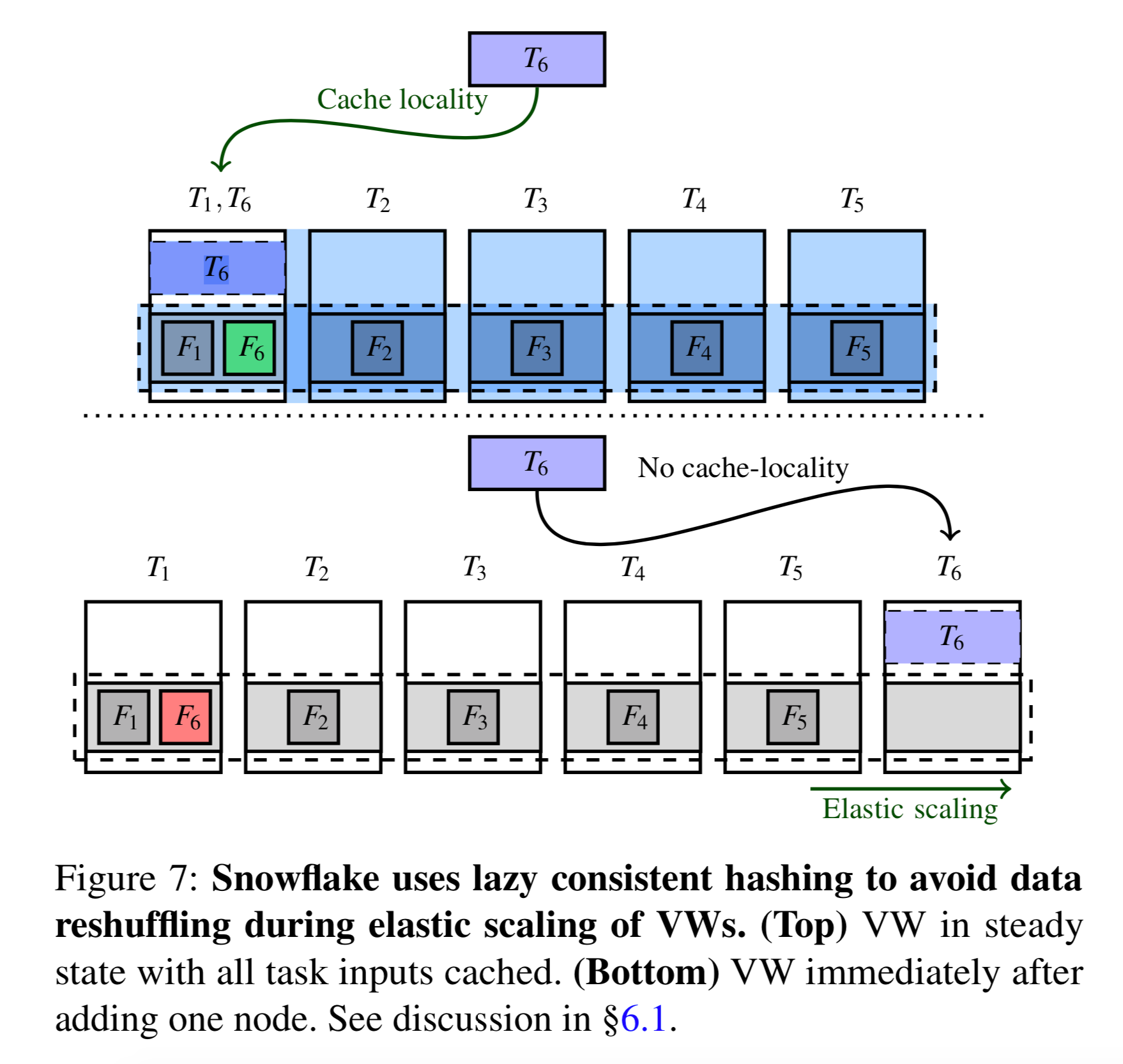
- 弾性的なローカル・エフェメラル・ストレージ。中間データには、永続的なデータとは異なる性能要件がある。残念ながら、既存の永続的データストアはこれらの要件を満たしていない。S3は必要とされる低レイテンシと高スループットの特性を提供していない。そこで、Snowflakeは、中間データの要件を満たすようにカスタム設計された分散型エフェメラルストレージシステムを構築した。このシステムはVW内のコンピュートノードと同位置に配置されており、ノードの追加や削除に応じて自動的にスケーリングするように明示的に設計されている。ノードが追加されたり削除されたりすると、我々のエフェメラルストレージシステムはデータの再分割や再シャッフルを必要としないことに注意してください(このようにして、シェアードナッシングアーキテクチャの核心的な制限の1つを緩和する)。各VWは独立した分散型エフェメラルストレージシステムを実行し、そのVW上で実行されているクエリによってのみ使用される。
- 弾力的リモート永続ストレージ。Snowflakeは、すべての永続的なデータをリモートの分散された永続的なデータストアに保存する。S3の弾力性、高可用性、耐久性の特性により、比較的控えめなレイテンシとスループットのパフォーマンスにもかかわらず、S3に永続データを格納している。S3は不変ファイルの保存をサポートしています。ファイルは完全に上書きすることしかできず、追加操作すらできない。ただし、S3はファイルの一部に対する読み取り要求をサポートしている。S3にテーブルを格納するために、Snowflakeはテーブルを従来のデータベースシステムのブロックに相当する大規模な不変ファイルに水平に分割する。各ファイル内では、PAXのように、個々の属性や列の値がグループ化され、圧縮される。各ファイルには、ファイル内の各カラムのオフセットを格納するヘッダがあり、S3の部分読み取り機能を利用して、クエリ実行に必要なカラムのみを読み取ることができる。
同じ顧客に属するすべてのVWは、リモートパーシステントストアを介して同じ共有テーブルにアクセスできるため、あるVWから別のVWにデータを物理的にコピーする必要はない。
エンドツーエンドのクエリ実行
クエリの実行は、顧客が特定の顧客VWに対して実行するために、顧客がCSにクエリテキストを送信することから始まります。この段階で、CS はクエリの解析、クエリの計画、操作を実行し、実行する必要のある一連のタスクを作成します。各タスクは、エフェメラルストレージシステムとリモートの永続的なデータストアの両方で読み書き操作を行うことができます。我々は§5でSnowflakeのスケジューリングとクエリ実行のメカニズムを説明する。CSは、各クエリの進捗状況を継続的に追跡し、パフォーマンスカウンタを収集し、ノード障害を検出すると、VW内の計算ノードでクエリの再スケジューリングを行う。クエリが実行されると、対応する結果は CS に戻り、最終的には顧客に返却される。
ワークロード特性
Snowflakeのアーキテクチャは、それがサポートする必要があるワークロードの特性に影響される。この論文では、14日間に渡って実行された約7,000万個のクエリについて収集したデータに基づいている。
クエリの約28%は読み取り専用で、読み込まれるデータ量は9桁以上も変化している。クエリの量は営業時間中に急増する。クエリの約13%は書き込み専用で、書き込みされるデータ量は8桁を超えている。残りの約13%は書き込みのみのクエリで、データ量は8桁以上の差がある。
また、クエリの実行中には、さまざまな量の中間データを処理する必要がある。クエリによっては、数百ギガバイト、あるいは数テラバイトの中間データを交換することもあります。クエリによって生成される中間データの量を予測することは、ほとんどのクエリでは「難しい、あるいは不可能」だ。中間データのサイズは、クエリごとに数桁の違いがあり、永続的なデータの読み込み量やクエリの予想実行時間とはほとんど、あるいは全く相関関係がない。
ディスアグリゲーション
これまでのところ、Snowflakeでは永続ストレージとコンピュート層が分離されていることを見てきた。独立してスケールすることができ、どのノードからでもすべての永続ストレージにアクセスできるようになっている。
しかし、中間データのためのエフェメラルストレージサービスは、S3をベースにしていない。これは、ノード上のインメモリデータが必要に応じてローカルSSDに流出する3層構造になっており、必要なときにはローカルSSDが枯渇するとS3に流出する。したがって、このストレージシステムの主な2つの層は分散されておらず、コンピュートノードに関連付けられている。中間データが必要ない場合は、同じエフェメラルストレージを、頻繁にアクセスされる永続的なデータのためのライトスルーキャッシュとして使用する。一貫性のあるハッシュスキームでデータをノードにマッピングする。
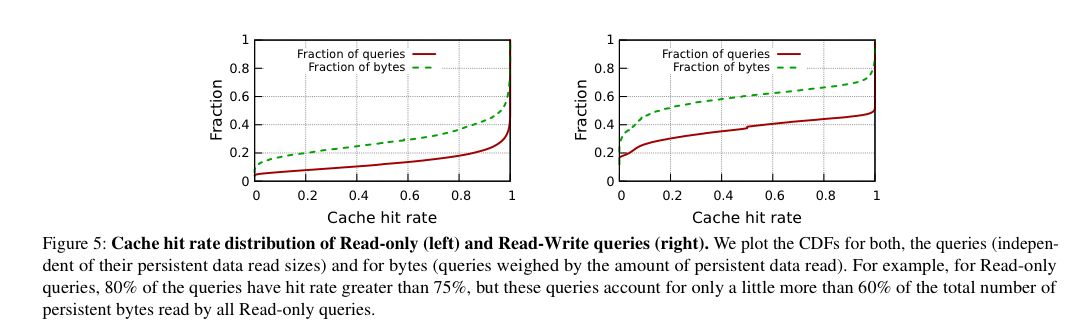
「エンドツーエンドのクエリ性能は、永続データファイルのキャッシュヒット率と中間データのI/Oスループットの両方に依存するため、エフェメラルストレージシステムがこの2つの間でどのように容量を分割するかを最適化することが重要だ。現在、中間データを常に優先するという単純なポリシーを使用していますが、エンドツーエンドの性能目標に関しては最適なポリシーではないかもしれない」と著者のコーネル大学博士候補のMidhul Vuppalapatiらは書いている。
伸縮性 (Elasticity)
ストレージの永続的な弾力性は、基礎となるストア(AWS上のS3など)によって提供されます。仮想倉庫はコンピュートノードのセットで構成され、コンピュートの弾力性はオンデマンドでノードを追加または削除することで達成される。事前にウォームアップされたノードプールを使用することで、数十秒単位の粒度で計算の弾力性を提供することができる。Snowflakeは一貫性のあるハッシュを使用して、アクセスする必要のある永続的なデータが存在するノードにタスクを割り当てるため、ノードを追加または削除すると、大量のデータの再シャッフルが必要になることがある。Snowflakeはこれを怠惰に行う。再構成後、一貫性のあるハッシュはパーティションの新しいホームノードにタスクを送るかもしれないが、そのノードはまだデータを持っていない。この時点でデータは永続的なストレージから読み込まれ、キャッシュされる。最終的には、古いホームノードのデータもキャッシュから取り除かれることになる。
VWのスケーリングは現在、かなり粗い粒度になっており、顧客がサイズ変更を要求する必要がある。問い合わせ間の到着時間は、顧客がVWのサイズ変更を要求するよりもはるかに頻繁に変化する。80%以上の顧客は、倉庫のサイズ変更を全く要求していない。理想的には、Snowflakeは、クエリ間の自動スケーリング(これについては現在進行中)と、個々のクエリの実行中の両方をサポートすることだ(リソースの消費量は、クエリのライフタイムで大きく変化する可能性がある)。
さらに進むと、Snowflakeは、自動スケーリング、高い弾力性、およびきめ細かな課金のために、サーバーレス・プラットフォームを探求したいと考えているという。「... Snowflakeが既存のサーバーレスインフラストラクチャに入り込む際に重要な障壁となるのは、セキュリティとパフォーマンスの両面で分離をサポートしていないことだ」とVuppalapatiらは書いている。
テナントの分離
Snowdflakeのテナントの分離は、VWレベルで行われる(各顧客はそれぞれ独自の VW を取得する)。VW は、「かなり良いが、理想的ではないが、平均的な CPU 利用率を達成しているが、他のリソースは通常、平均的には十分に利用されていない」。
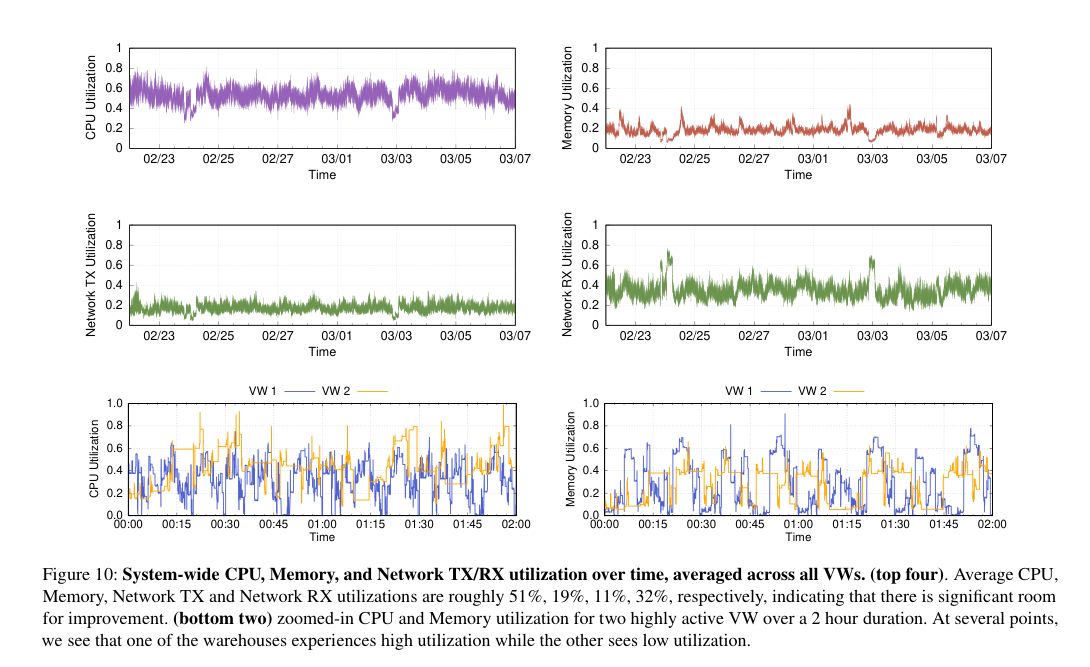
「Snowflakeを設計したときには、このパフォーマンスの分離と利用率のトレードオフを意識していましたが、最近のトレンドにより、この設計の選択を見直す必要が出てきました。具体的には、インフラストラクチャ・プロバイダーが時間単位で課金していた場合、事前にウォームアップされたインスタンスのプールを維持することはコスト効率が良かったのだが、最近ではすべての主要なクラウド・インフラストラクチャ・プロバイダーが秒単位で課金するようになったことで、興味深い課題が出てきた」とVuppalapatiらは書いている。
Snowflakeは運用コストを削減したいと考えており、顧客もよりきめ細かい価格設定を希望している。「秒単位の課金」では、特定の顧客に対して、事前に暖められたノードの未使用サイクルを課金することはできない。この橋を渡るために、Snowflakeはアイソレーションモデルを再考し、共有リソースのセットに顧客の要求を多重化する必要がある。もちろん、これは強力な分離特性を維持しながら行われなければならない。分離する必要がある2つの重要なリソースは、コンピュートとエフェメラルストレージだ。データセンターでのコンピュートの分離についてはよく研究されているが、メモリとストレージの分離についてはあまり研究されていない。
エフェメラルストレージの課題は、テナント間でキャッシュを公平に共有することと、他のテナントに影響を与えることなく、1つのテナントの需要に合わせて拡張できることだ(たとえば、現在採用されているハッシュスキームは、リサイズのトリガーとなる1つのテナントだけでなく、複数のテナントでキャッシュミスが発生する原因となりうる)。
メモリの問題は重要であり(VWのメモリ使用率は現在のところ低く、DRAMは高価である)、対処が困難だ。独立したスケーリングのための分散メモリ・ソリューションと、複数のテナント間で分散メモリを共有するための効率的なメカニズムの両方が必要である。
参考文献
- Midhul Vuppalapati et al. Building An Elastic Query Engine on Disaggregated Storage. Proceesing of 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’20) February, 2020.
- B. Dageville, T. Cruanes, M. Zukowski, V. Antonov, A. Avanes, J. Bock, J. Claybaugh, D. Engovatov, M. Hentschel, J. Huang, et al. The snowflake elastic data warehouse. In SIGMOD, 2016.
Special thanks to supporters !
Shogo Otani, 林祐輔, 鈴木卓也, Mayumi Nakamura, Kinoco, Masatoshi Yokota, Yohei Onishi, Tomochika Hara, 秋元 善次, Satoshi Takeda, Ken Manabe, Yasuhiro Hatabe, 4383, lostworld, ogawaa1218, txpyr12, shimon8470, tokyo_h, kkawakami, nakamatchy, wslash, TS, ikebukurou, 太郎.
月額制サポーター
Axionは吉田が2年無給で、1年が高校生アルバイトの賃金で進めている「慈善活動」です。有料購読型アプリへと成長するプランがあります。コーヒー代のご支援をお願いします。個人で投資を検討の方はTwitter(@taxiyoshida)までご連絡ください。

投げ銭
投げ銭はこちらから。金額を入力してお好きな額をサポートしてください。



