SpAtten: Attentionの実行に特化したソフトウェアとハードウェア
MITの電気工学・コンピュータサイエンス学科の博士課程の学生であるHanrui Wangらは、計算機の性能に深く依存するAttentionの実行時のDRAMアクセスと計算量の両方を削減するためのテクニックとハードウェアを提案した。


自然言語処理(NLP)は、近年、Attentionメカニズムに牽引されて急速に進歩している。Transformer、BERT、GPT-2などのAttentionモデルは、畳み込みニューラルネットワーク(CNN)やリカレントニューラルネットワーク(RNN)に基づくモデルよりも大幅な性能向上を実現している。BERTは、困難な文分類 タスクでは、人間の性能をも凌駕している。
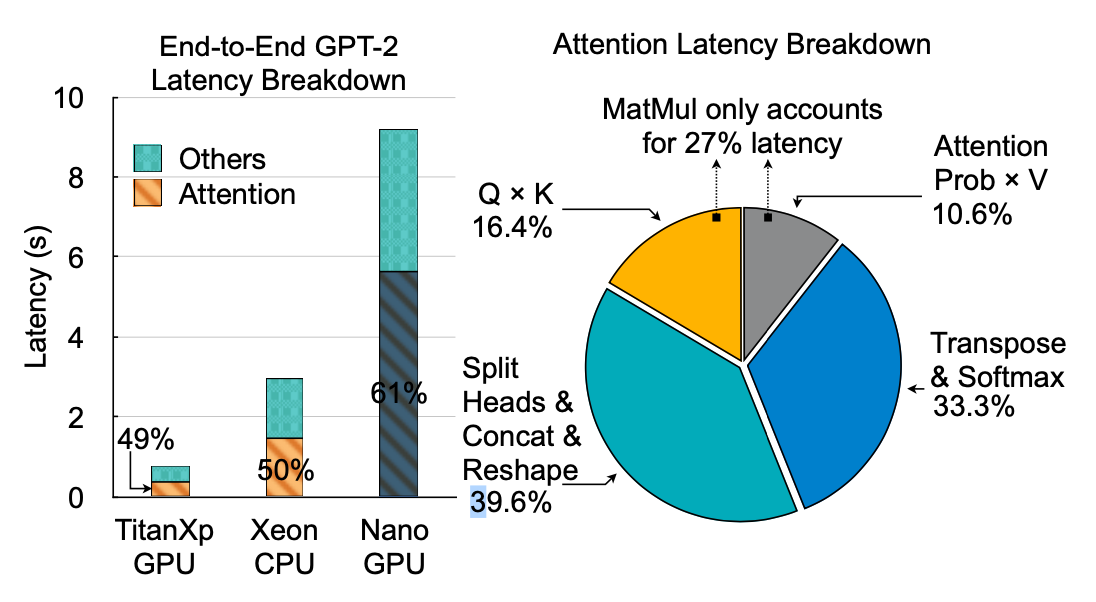
残念ながら、高い精度は、効率性を犠牲にしている。Attentionは、GPUやCPUなどの汎用プラットフォームでは、データの動きが複雑で演算強度が低いため、動作が非常に遅くなる。例えば、わずか30個のトークンで文章を表現する場合、GPT-2モデルはTITAN Xp GPUで合計370ミリ秒でアテンション推論を実行する。
これは画像を分類するのに6ミリ秒しかかからないMobileNet-V2よりも2桁遅い。リソースが限られたRaspberry Pi ARM CPUでは、Attentionに43秒かかり、対話型のアプリケーションは不可能になる。このような効率の悪さが、Attentionモデルをモバイルデバイスに展開することを阻んでいる。CNNやRNNを高速化するために多くのアクセラレータが提案されているが,それらのアクセラレータは動作が異なるため,アテンションに簡単に適用することはできない。
Attentionの入力は、クエリ(Q)、キー(K)、値(V)を含み、それぞれが複数のヘッドに分割される。Attention確率を V で乗算すると 1 つのヘッドの結果が得られ、すべてのヘッドを連結するとAttentionの出力が得られる。生成段階でのAttention度の演算強度は低く、ベクトル行列乗算(Q × K)では1データあたり 2 回の演算(0.5OPS/バイト)のみだ。生成は、GPT-2 モデルにおける全体的な待ち時間の最大の部分を占めている(32 個のトークンを生成する場合は 97%)。BERT の場合、全体的な性能は計算に依存する。
そこで、MITの電気工学・コンピュータサイエンス学科の博士課程の学生であるHanrui WangらはAttention実行時のDRAMアクセスと計算量の両方を削減するために、図1に示すようなカスケード・トークン・プルーニングを提案する。人間の言語は、前置詞、冠詞、副詞などの構造的で無意味なトークンが多く、冗長性が高いことに着想を得て、結果にほとんど影響を与えずに、重要でないトークンを安全に除去することができる。さらに、アテンションは様々な依存関係を捉えるために多くのヘッドを使用するが、その中には冗長なものもある。

この研究は今月、IEEE International Symposium on High-Performance Computer Architectureで発表される予定だ。Wangは論文の主著者であり、共著者には、Zhekai Zhangとその指導教員であるSong Han助教授が含まれている。
Wangらが指摘する課題の1つは、Attentionメカニズムを使ったNLPモデルを実行するための専用のハードウェアがないことだ。CPUやGPUのような汎用プロセッサでは、Attentionメカニズムの複雑なデータ移動や演算のシーケンスに問題がある。そして、NLPモデルが複雑になるにつれて、特に長文の場合には問題は悪化するだろう。増え続ける計算需要を処理するためには、アルゴリズムの最適化と専用のハードウェアが必要だ。
研究者たちは、Attentionをより効率的に実行するために、SpAttenと呼ばれるシステムを開発した。彼らの設計には、特殊なソフトウェアとハードウェアの両方が含まれている。SpAttenの重要な進歩の1つは、カスケード・プルーニング(cascade pruning)、つまり計算から不要なデータを排除することだ。アテンション機構が文のキーワード(トークンと呼ばれる)を選ぶと、SpAttenは重要でないトークンを刈り込み、それに対応する計算やデータの動きを排除する。Attentionメカニズムには、複数の計算枝(ヘッドと呼ばれる)も含まれている。トークンと同様に、重要ではないヘッドは識別され、剪定される。一度ディスパッチされると、不要なトークンやヘッドはアルゴリズムの下流の計算には影響しないため、計算負荷とメモリアクセスの両方を削減することができる。
メモリ使用量をさらに削減するために、研究者は「プログレッシブ量子化」と呼ばれる技術も開発した。この方法では、アルゴリズムはより小さなビット幅のチャンクでデータを処理し、メモリから可能な限り少ないデータをフェッチすることができる。ビット幅が小さくなるほどデータの精度が低くなり、単純な文章には精度が高くなり、複雑な文章には精度が高くなるようになっている。
さらにWangらはDRAMアクセスを削減するために、Attention入力に対してプログレッシブ量子化を提案する。少数のトークンが分布を支配している場合、量子化誤差は小さく、MSBのみが必要となり、フラットな分布の場合はLSBとMSBの両方が必要となる。この現象については、セクションIII-Dで理論的な証明を行う。この観察に基づいて、Wangらは、Attention確率が支配的なAttentionに対してはより積極的に量子化を行い、その他のAttentionに対してはより保守的に量子化を行ったという。メモリアクセスが少なくて済むように計算を行うことができるので、メモリに依存するモデルには有利だ。プログレッシブ量子化により、さらに5.1倍のメモリアクセスを節約することができる。
要約すると、SpAttenは、精度を維持しつつ、スパースおよび量子化されたAttention計算のためのアルゴリズム・アーキテクチャの共同設計を行う。SpAttenは4つの貢献をしている。
- カスケード・トークン・プルーニングは、累積トークン重要度スコアに応じて重要でないトークンを削除し、DRAMアクセスと計算量を最大3.8倍削減する。
- カスケード・ヘッド・プルーニングは、重要でないヘッドを削除し、DRAMアクセスと計算量を1.1倍削減する。
- プログレッシブ量子化では、メモリアクセスが少なくなる代わりに、計算量が少し増える。Attention度の高いヘッドやレイヤーのビット幅をAttention度分布に応じて変更することで、DRAMアクセスを5.1×削減。
- 時間的に複雑なSpecialized High Parallelism top-k Engineを搭載し、オンザフライでのトークンとヘッドの選択を効率的にサポートする。
並列性を重視したハードウェア
これらのソフトウェアの進歩と並行して、研究者らは、メモリアクセスを最小限に抑えながらSpAttenとAttentionメカニズムを実行することに特化したハードウェアアーキテクチャも開発した。このアーキテクチャ設計では、複数の処理要素で複数の演算を同時に処理する「並列性」を重視しており、Attentionメカニズムは一文一文を一度に解析するために有効である。この設計により、SpAttenは、トークンとヘッドの重要度を(潜在的な剪定のために)少ないクロックサイクル数でランク付けすることが可能になった。全体的に、SpAttenのソフトウェアとハードウェアのコンポーネントは、不必要で非効率なデータ操作を排除し、ユーザーの目的を達成するために必要なタスクだけに焦点を当てることができる。
SpAttenの概要を図8の通りだ。トークン/ヘッドの刈り込みをサポートするために、トークン/ヘッドの重要度をランク付けする。刈り込みは計算とメモリトラフィックを削減するが、ランダムアクセスが発生する。このため、クロスバーを適用してアドレスを処理し、各メモリチャネルをビジー状態に保ち、帯域幅利用率を向上させる。プログレッシブ量子化をサポートするために、フェッチされたビットの分割や、MSBとLSBの連結を処理するために、オンチップのビット幅変換器を実装している。
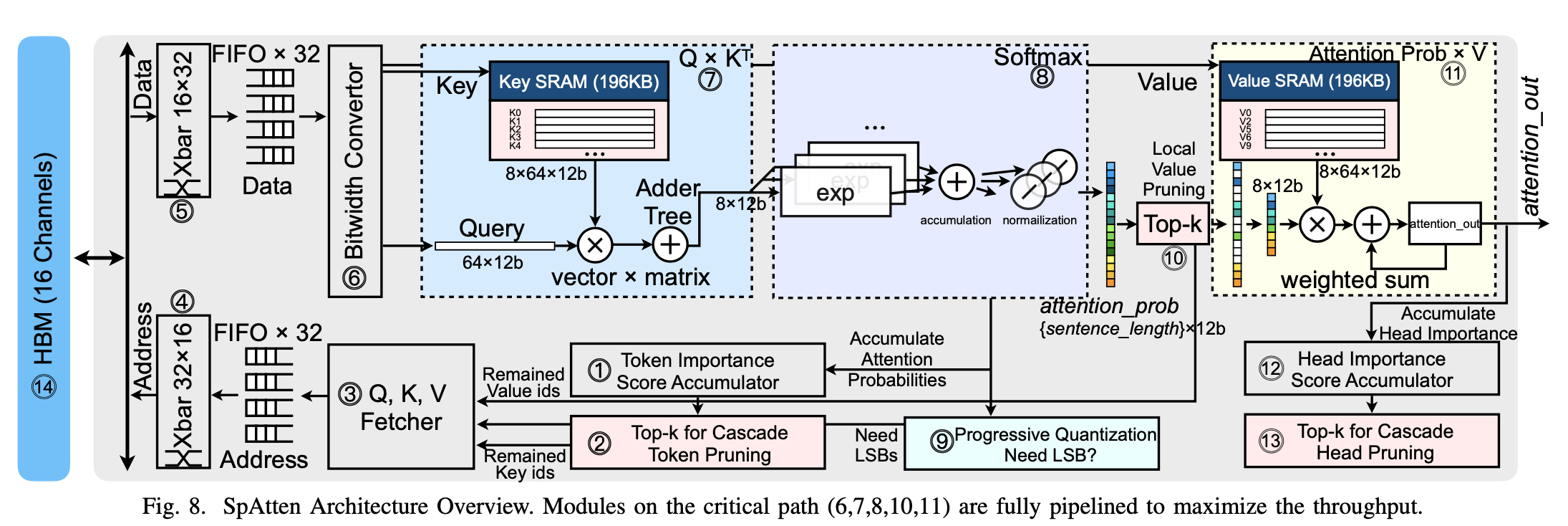
SpAttenは、Attentionをヘッドごとに処理し、クエリごとにクエリを処理することで、プルーニングの粒度とパーセンテージのバランスを良くしている。
1つのヘッドのクエリが一度にパイプラインに供給され、ヘッド単位とレイヤ単位の粒度の両方でトークンの刈り込みが可能になる。インナーヘッド並列化により、チップ上のすべての計算リソースをビジー状態に保つことができるため、ヘッド間並列化は必要ない。要約段階では、カスケードトークン刈り込みに耐えたKとVがオンチップSRAMにフェッチされ、複数のクエリに渡って再利用される。生成段階では、Qは単一のベクトルであるため、KとVの再利用はなく、オンチップSRAMに格納する必要はない。
参考文献
- Hanrui Wang, et al. SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning. arXiv:2012.09852 [cs.AR]. [v2] Mon, 4 Jan 2021 03:49:57 UTC (2,039 KB).
- Daniel Ackerman. A language learning system that pays Attention — more efficiently than ever before. MIT News. Feb 10, 2021.
Photo by Joel Naren on Unsplash
Special thanks to supporters !
Shogo Otani, 林祐輔, 鈴木卓也, Mayumi Nakamura, Kinoco, Masatoshi Yokota, Yohei Onishi, Tomochika Hara, 秋元 善次, Satoshi Takeda, Ken Manabe, Yasuhiro Hatabe, 4383, lostworld, ogawaa1218, txpyr12, shimon8470, tokyo_h, kkawakami, nakamatchy, wslash, TS, ikebukurou, 太郎, bantou.
700円/月の支援
Axionは吉田が2年無給で、1年が高校生アルバイトの賃金で進めている「慈善活動」です。有料購読型アプリへと成長するプランがあります。コーヒー代のご支援をお願いします。個人で投資を検討の方はTwitter(@taxiyoshida)までご連絡ください。


投げ銭
投げ銭はこちらから。金額を入力してお好きな額をサポートしてください。



