スノーフレイク (SNOW) の技術的な企業分析
Snowflakeは、クラウド時代に焦点を合わせた、エンタープライズ利用に好ましいデータウェアハウス。今後もRedshiftなどの競合ともに市場を分け合うことになるだろう。


Snowflake(SNOW)は、2012年に設立されたクラウドベースのデータウェアハウス企業である。カリフォルニア州サンマテオに拠点を置く、同社は9月下旬にニューヨーク証券取引所に上場し、米国での株式公開で過去最大のソフトウェア企業となった。
当初、株式の価格は75ドルから85ドルの間と予想されていたが、同社は120ドルで上場し、取引初日には300ドルにまで急上昇した。これは別の記録を更新した。スノーフレークは、上場初日に株式価値が2倍になった史上最大の企業となり、時価総額は750億ドル近くに達した。
これまで多くの企業データはオンプレミスで保存されてきた。つまり、データは企業が管理する物理サーバーに保存されていた。OracleやIBMなどの現存企業が伝統的にこの領域を支配してきた。
しかし、Snowflakeは根本的に違う。Snowflakeは、データをオンプレミスに保存するのではなく、企業がクラウドにデータを保管するのを支援する。さらに決定的なのは、企業がストレージ(データを保持する場所)とコンピューティング(クエリを実行する行為)を分離するというSnowflakeの重要なイノベーションである。Google、Amazon、Microsoftが独自の同等の製品を持つ前にこのサービスを提供することで、Snowflakeは顧客を惹きつけ、データウェアハウス分野で市場シェアを築くことができた。
SnowflakeのTAM( Total Addressable Market)は巨大だ。同社は目論見書のなかで810億ドルとしているが、それよりも大きいかもしれない。International Data Corporationの計算によると、2018年の世界のデータストレージからの収益は880億ドルで、2023年には約1760億ドルに達すると予想されている。データウェアハウス市場は順調に成長している。2018年には130億ドルと推定されていた市場は、2025年には300億ドルに達すると予測されており、年率12%の複合成長率となっている。新しいデバイスやソフトウェアプログラムの登場により、生成されるデータ量が増加するため、Snowflakeのような洗練されたウェアハウスソリューションの需要が高まると考えられる。
1. 沿革
Snowflake Inc.は、2012年に3人のデータウェアハウス専門家のBenoit Dageville、Thierry Cruanes、Marcin Zukowskiの3人によって2012年にカリフォルニア州サンマテオに設立された。DagevilleとCruanesはOracle でデータアーキテクトとして働いていた経験があり、Zukowskiはオランダの新興企業Vectorwiseの共同設立者だった。同社の初代CEOは、Sutter Hill VenturesのベンチャーキャピタリストであるMike Speiserだった。
Snowflakeは、2014年6月に元Microsoft幹部のBob MugliaをCEOに任命した直後の10月にステルスモードから脱却した。クラウドデータウェアハウスは2015年6月に一般的に利用できるようになり、その時点で80の組織が利用していた。
この製品、Snowflake Elastic Warehouseは、クラウドベースのサービスであり、データウェアハウス・アズ・ア・サービスと呼ばれている。データウェアハウスの概念は、金融サービスやクレジットカード会社などの企業がリレーショナルデータベースから大量のデータを扱い始めた1980年代に様々なシステムからデータを引き出す方法を必要としていたことに遡る。このような初期のシステムは、膨大なリソースとITの助けを必要とし、構築には何年もかかり、構築や保守には費用がかかり、複雑で、クエリの作成や回答の生成には専門家が必要だった。
Snowflakeは、複雑さを軽減し、すべてをクラウドに置くことで、この概念を近代化する機会を得た。ユーザーは必要なだけのコンピュートとストレージリソースにリーズナブルな価格でアクセスでき、IT部門はデータセンターにシステムを構築したりメンテナンスしたりする必要がないため、ハードウェアを排除することができる。
エンドユーザーは、データのロードとクエリの実行以外には何も心配する必要がなく、システムはニーズに合わせてスケールアップまたはスケールダウンすることができる。これは、データストアのサイズに制限されず、ITやDBAの助けを必要としないことを意味する。
Mugliaは「昔のデータウェアハウスはきちんとした行とテーブルのリレーショナルデータベースに頼っていたが、今日のデータは構造化データと半構造化データが混在している」と述べている。顧客にどちらか一方を選択させたり、別々に処理するツールを用意したりするのではなく、Snowflakeは独自のデータベースを構築し、単一のシステムで両方のタイプのデータを処理するようにした。
企業がオープンソースのソリューションを検討し、データを処理する方法を選択し、その上にソリューションを構築する時代にあっては、これは大胆な動きだ。その代わりに、Snowflakeは独自の方法でゼロからシステムを構築した。構造化データと半構造化データの2種類のデータを処理するシステムが必要だったため、そのビジョンに対応するために独自のデータベースを構築する必要があった。
その結果、旧式のデータウェアハウスでは何時間も何日もかかっていたものが、1つの製品で2つのタイプのデータを理解し、クエリに対する回答を最短15分で提供できるようになった。Snowflakeはデータセットのサイズを気にしていない運用を提供することも重視していた。ユーザーは好きなだけデータを提供することができ、Snowflakeがそのデータを処理してくれる。

ステルスモードが終わった2014年10月の『From Our Founders』というブログの中で共同創業者Benoit Dagevilleは、次世代のデータウェアハウスについて以下のような要件を挙げた。
- 低コストで無制限のストレージ容量。
- あらゆる形のデータを保存し、効率的に処理できるように、ゼロから設計され、最適化されていること。
- あらゆる処理需要に対応するために数分以内に同時使用ユーザーをサポートし、クエリが実行されていない場合にはゼロに戻すことも可能な、真の意味での弾力性
- ダウンタイムなし、データ損失なし、どこからでもアクセス可能、完全に安全
「多くの人がHadoopがその革命になることを期待していた。フリーのソフトウェアとコモディティなハードウェアを使用することで、膨大な量のデータを処理するだけでなく、簡単で比較的コスト効率の高いストレージを可能にした」とDagevilleは書いている。「しかし、『無料』には莫大なコストがかかる。Hadoopシステムは、従来のウェアハウスシステムに比べて効率性が桁違いに低いことが多い。インターフェイスはデータ専門家向けであり、何百万人ものユーザーを置き去りにしている。そして、Hadoopは製品ではなくエコシステムであり、非常に複雑であり、非常に高価であることを意味している。そして、より柔軟性があるとはいえ、使用するハードウェアによって制限されることに変わりがない」
Dagevilleが提示した手段は、クラウドだ。「クラウドは理想のデータウェアハウスを生み出す唯一のコンピューティングプラットフォームだ。クラウドは、ハードウェアリソースの入手方法が異なるだけではなく、事実上無限のストレージとコンピュートリソースをオンデマンドで利用できるようになり、ユーザーはすべてのソフトウェアとインフラストラクチャの管理作業から解放される。これは、真に弾力性のあるソフトウェアを構築し、それをサービスとして提供するために必要不可欠な基盤を提供する。しかし、クラウドの素晴らしい機能をフルに活用するためには、ソフトウェアを再発明し、一から構築する必要がある」。
2. スノーフレイクの新規性
クラウドの出現は、ソフトウェアの配信と実行をローカル・サーバ上で行うことから、Amazon、Google、Microsoftなどのプラットフォーム・プロバイダがホストする共有データセンターや「Software-as-a-Service」ソリューションへと移行することを示した。クラウドの共有インフラストラクチャは、規模の経済の向上、優れたスケーラビリティと可用性、予測不可能な時代の需要に適応する従量課金型のコストモデルを約束する。しかし、これらの利点は、ソフトウェア自体がクラウドというコモディティリソースのプール上で弾力的に拡張できる場合にのみ獲得できる。従来のデータウェアハウス・ソリューションは、クラウドよりも前から存在しており、小規模で静的なクラスタ上で動作するように設計されていたため、大規模で動的なクラスタを前提とするクラウドの設計への適合性が悪かった。
プラットフォームだけが変わったわけではなく、データも変化した。以前は、データウェアハウス内のデータのほとんどは、トランザクションシステム、企業資源計画(ERP)アプリケーション、顧客関係管理(CRM)アプリケーションなど、組織内のソースから取得されていたが、データウェアハウス内のデータの構造、量、速度が変化した。データの構造、量、速度はすべて予測可能で、よく知られていた。
しかし、クラウドでは、アプリケーション・ログ、ウェブ・アプリケーション、モバイル・デバイス、ソーシャル・メディア、センサー・データ(モノのインターネット)など、管理が困難な外部ソースからのデータの割合が大幅に増加した。データ量の増加に加えて、このデータはスキーマのない半構造化された形式で提供されることが多い。従来型のデータウェアハウスソリューションは、この新しいデータに苦戦した。これらのソリューションは、深いETL( Extract [抽出] Transform [変換] Load [格納] の略で、データ統合時に発生する各プロセス)のパイプラインと物理的なチューニングに依存しており、基本的には予測可能で動きが遅く、主に内部ソースからのデータを容易に分類することを前提としている。
これらの欠点に対応するために、データウェアハウスのコミュニティの一部では、HadoopやSparkなどの「ビッグデータ」プラットフォームに目を向けるようになった。これらはデータセンター規模の処理タスクを処理するためには、誰でも利用できるツールであり、オープンソース・コミュニティはStinger Initiativeのような大きな改善を続けているが、確立されたデータウェアハウス技術の効率性や機能セットの多くはまだ不足しているのが実情だ。しかし、最も重要なことは、これらのツールをロールアウトして使用するためには、多大なエンジニアリングの努力が必要であるということだ。
Snowflakeは、クラウドの経済性、弾力性、サービスの側面から恩恵を受けることができるものの、従来のデータウェアハウス技術やビッグデータプラットフォームでは十分にサービスを受けられないユースケースやワークロードの大規模なクラスが存在すると考えた。そこで同社は、クラウド専用の全く新しいデータウェアハウスシステムを構築することにした。そのシステムが「Snowflake Elastic Data Warehouse」だ。クラウドデータ管理領域の他の多くのシステムとは対照的に、SnowflakeはHadoopやPostgreSQLなどをベースにしていない。彼らは、最初のステルスモードの2年間からずっと、処理エンジンをはじめほとんどの部分をゼロから開発してきたのだ。
3. Snowflake製品の特徴
Snowflake製品の主な特徴は以下の通りだ。
純粋なSaaS(Software-as-a-Service)体験。ユーザーは、マシンを購入したり、データベース管理者を雇ったり、ソフトウェアをインストールしたりする必要はない。ユーザーは、データをすでにクラウド上に持っているか、アップロードする。ユーザーは、Snowflakeのグラフィカル・インターフェースや ODBC などの標準化されたインターフェースを使用して、すぐにデータを操作したり、クエリを実行したりすることができる。他のデータベース・アズ・ア・サービス(DBaaS)とは対照的に、Snowflake のサービスの特徴は、ユーザー体験全体にまで及んでいる。調整ノブや物理的な設計、ユーザー側でのストレージの手入れなどの作業はない。
リレーショナル。 Snowflakeは、ANSI SQLとACIDトランザクションを包括的にサポートしています。ほとんどのユーザーは、ほとんど変更を加えることなく、既存のワークロードを移行することができる。
半構造化。 Snowflakeは、JSONやAvroなどの一般的なフォーマットをサポートし、半構造化データのトラバース、フラット化、ネストインギングのためのビルトイン関数とSQL拡張機能を提供する。自動スキーマ発見とカラムストレージにより、スキーマレスで半構造化されたデータに対する操作は、ユーザーの努力なしに、プレーンなリレーショナルデータとほぼ同等の速度で実行される。
弾力的なストレージ。 コンピュートリソースは、データの可用性や同時実行クエリのパフォーマンスに影響を与えることなく、信頼性の高いシームレスなスケーリングが可能だ。
高可用性。 Snowflakeは、ノード、クラスタ、さらにはデータセンター全体の障害にも対応する。ソフトウェアやハードウェアのアップグレード中にダウンタイムが発生することはない。
耐久性の高さ。 Snowflakeは、クローニング、アンドロップ、およびクロスリージョンバックアップなどの偶発的なデータ損失に対する特別な保護機能を備えた、非常に高い耐久性を持つように設計されている。
コスト効率の高さ。 Snowflakeは非常に計算効率が高く、すべてのテーブルデータは圧縮されている。ユーザーは、実際に使用するストレージと計算リソースの分だけを支払うことになる。
セキュリティ。一時ファイルやネットワークトラフィックを含むすべてのデータは、エンドツーエンドで暗号化されている。クラウドプラットフォームにユーザーデータが流出することはない。さらに、ロールベースのアクセス制御により、ユーザーはSQLレベルで細かいアクセス制御を行うことができる。
さらに、Snowflakeの設計と主なプリンシプルと、市場で利用可能な他のDWHソリューションとの差別化に焦点を当てると、このようになる。
- ストレージのバックエンドとしてAmazon S3とAzure Storageを使用している。このアプローチにより、SnowflakeDBは、ストレージの容量プロビジョニングとIOスループット保証の両方の面で、クラウドプロバイダーにピギーバックすることができる。これは非常に便利だ。クラウドプロバイダーは、クラウドプラットフォームの主な価値提案の1つであるストレージの防弾性を高めるために多くのお金を投資する傾向があり、新しいクラウドネイティブソリューションを開発する際にそれを利用しないのは愚かなことだ。
- ストレージとコンピュートの分離。従来のMPP(超並列コンピューター)ソリューションでは、データの保存にクラスタノードのローカルHDDを使用しており、効果的に1台のクラスタマシンの分割不可能なスケーリング単位を作成している。また、MPPの設計上、クラスタノード間のリソースのスキューを避けるために、クラスタ内のすべてのマシンが同じハードウェア仕様でなければならないため、コンピュートリソースとストレージの結合は非常に厳しくなる。ベンダーがストレージとコンピュートを分離するために多大な努力をしている例はたくさんある。Exadataや、複数のストレージベンダーがエンタープライズストレージアプライアンスをVerticaやGreenplumのようなより伝統的なMPPソリューションの下に置こうとしている。それは、MPPワークロードを処理するのに十分な弾力性のある分散ストレージを構築するためには、その開発、展開、サポートに膨大な時間と費用を費やす必要があるという単純な理由からだ。これは、すべてのクラウドプロバイダーがクラウドストレージの提供を導入するために行ったことであり、どの企業もオンプレミスでの導入を繰り返す余裕がないことだ。そこでSnowflakeは、ストレージとコンピュートを分離し、クラウドストレージと対話してデータの読み書きを行うステートレスワーカープール(仮想ウェアハウス)の概念を導入した。
- ステートレスなコンピュートノード。クエリの実行は、仮想ウェアハウスで実行されているプロセスによって処理される。仮想ウェアハウスは基本的にステートレスワーカーノードのセットであり、必要に応じてプロビジョニングして拡張することができる。また、クラウドストレージに保存されている同じデータに対して複数の仮想ウェアハウスを実行することができるのは大きなメリットだ。仮想ウェアハウスの各ノードは、クラウドストレージから読み込んだデータをキャッシュするためにローカルディスクを利用しているため、ステートレスとは言い切れない。キャッシングを利用するために仮想ウェアハウスノードへのブロックアフィニティが利用されているが、「盗用」は可能なので、アフィニティは厳密ではない。
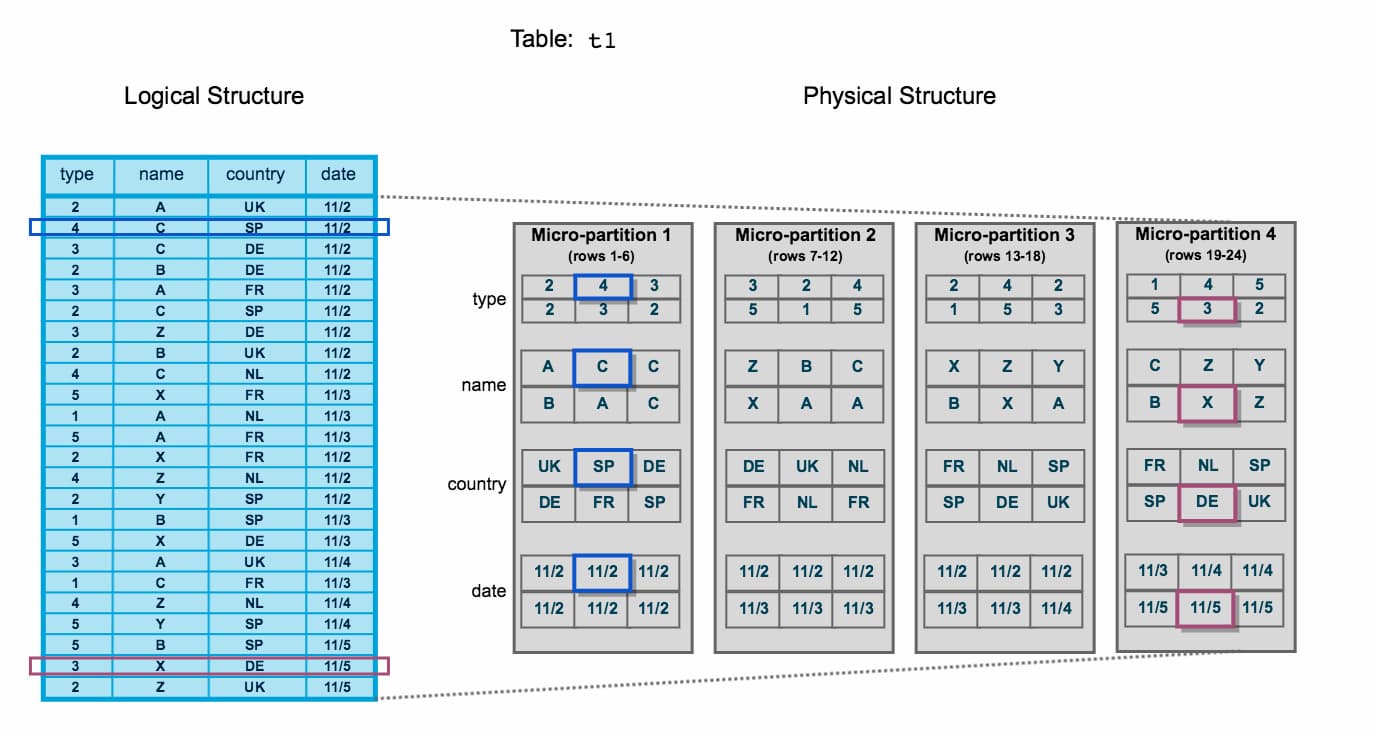
- マイクロパーティション。クラウドストレージに適度な大きさのブロックごとにデータを格納する。SIGMOIDの論文によると、ブロックのサイズは50MB~500MBの非圧縮データ。このブロックをマイクロパーティションと呼ぶ。各ブロックは、テーブルからの行の集合を表し、圧縮された列形式で格納される。各マイクロパーティションは、フィールドのそれぞれについての統計情報のセットを持っている(min-max値、明瞭な値の数、非構造化データに存在するフィールドのブルームフィルタ)。非構造化データの場合、いくつかのフィールドは(ヒューリスティックに基づいて)引き出され、それらに収集された同じフィールドレベルの統計情報を持っている。また、この種のフィールドは、ヒューリスティックベースの型推論の対象となり、余分な統計情報を収集することができる。統計情報はブロック作成時に各ブロックごとに独立して収集される。
- メタデータの一元管理。 SnowflakeDBには、クラウドサービスと呼ばれるコンポーネントがある。実質的に、Snowflakeはこのレイヤーに顧客のすべてのメタデータをシークレットソースのキーバリューストア(KVS)に格納している。メタデータは(Snowflake VPSの顧客を除く)集中管理された方法で格納されているため、ブロックレベルの統計情報やその他のメタデータは、大規模な顧客のセットに対して1つのキーバリューストアに格納されている。このようにメタデータを格納することで、Snowflakeは、テーブルやデータベース全体のメタデータを複製するだけで、テーブルやデータベース全体を複製するような面白いトリックを行うことができる。メタデータは同じマイクロパーティションを参照し続け、メタデータフォークの後、2つのオブジェクトは互いに独立して変更することができる。
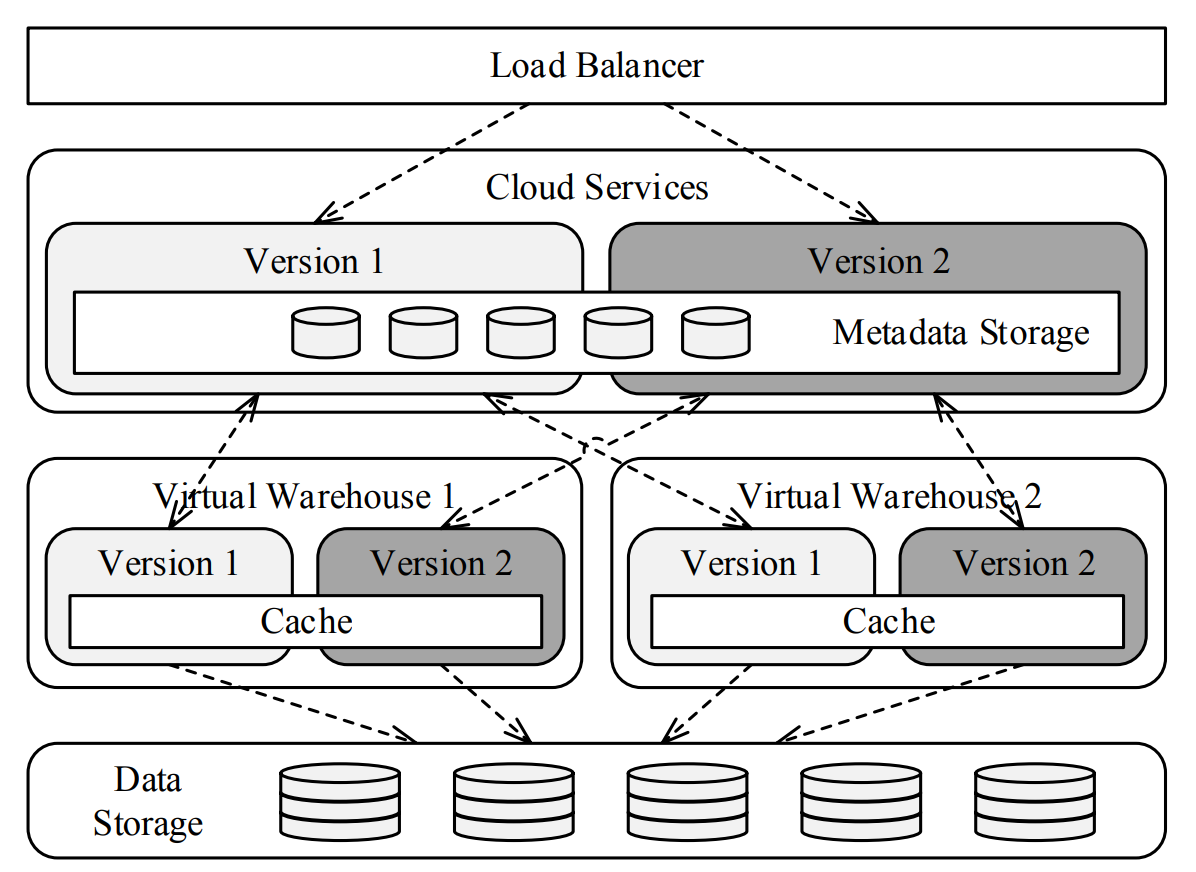
- オンラインアップグレード。 ソフトウェアのアップグレードは透明性が高く、Snowflakeチームが一元的に処理する。これは、ステートレスコンピュートと集中型クラウドストレージを持つことで実現している。Snowflakeは、新旧のソフトウェアバージョンのデュアルランを行うことでこれを処理し、クライアントアプリケーションを新旧のデプロイメントから透過的に移行できるようにする。
- ブロックレベルでのMVCC(多版型同時実行制御)。 Snowflakeのデータブロックは不変、つまりマイクロパーティションは不変。マイクロパーティションに格納されているデータが更新されるたびに、事実上、更新されたデータを含む新しいマイクロパーティションが作成され、このイベントに関するメタデータが集中型メタデータストレージに書き込まれる。このように、MVCCはブロックレベルで実装されている。タイムスタンプXでテーブルTを読み込んだと想像してください。クエリエンジンは、タイムスタンプXの時点でテーブルTに存在していたすべてのブロックを返すようにメタデータストアに要求し、これらのブロックを読み込んだとする。後の瞬間Yにテーブルデータの更新が起こった場合、メタデータはこの変更を反映して更新され、タイムスタンプZのクエリはタイムスタンプXのクエリとは異なるブロックのセットを読み取るようになる。期限切れのブロックはクラウドサービスの補助処理で自動的にクリーンアップされるので、気にする必要はない。
- パーティション、インデックス、チューナブルがない。 これはSnowflakeの主なモットーの1つ。 「箱」から出してすぐに使用できるソリューションであり、(同社のマーケティングによると)最適化やチューニングに時間を費やす必要はない。
4. ベンチマーク
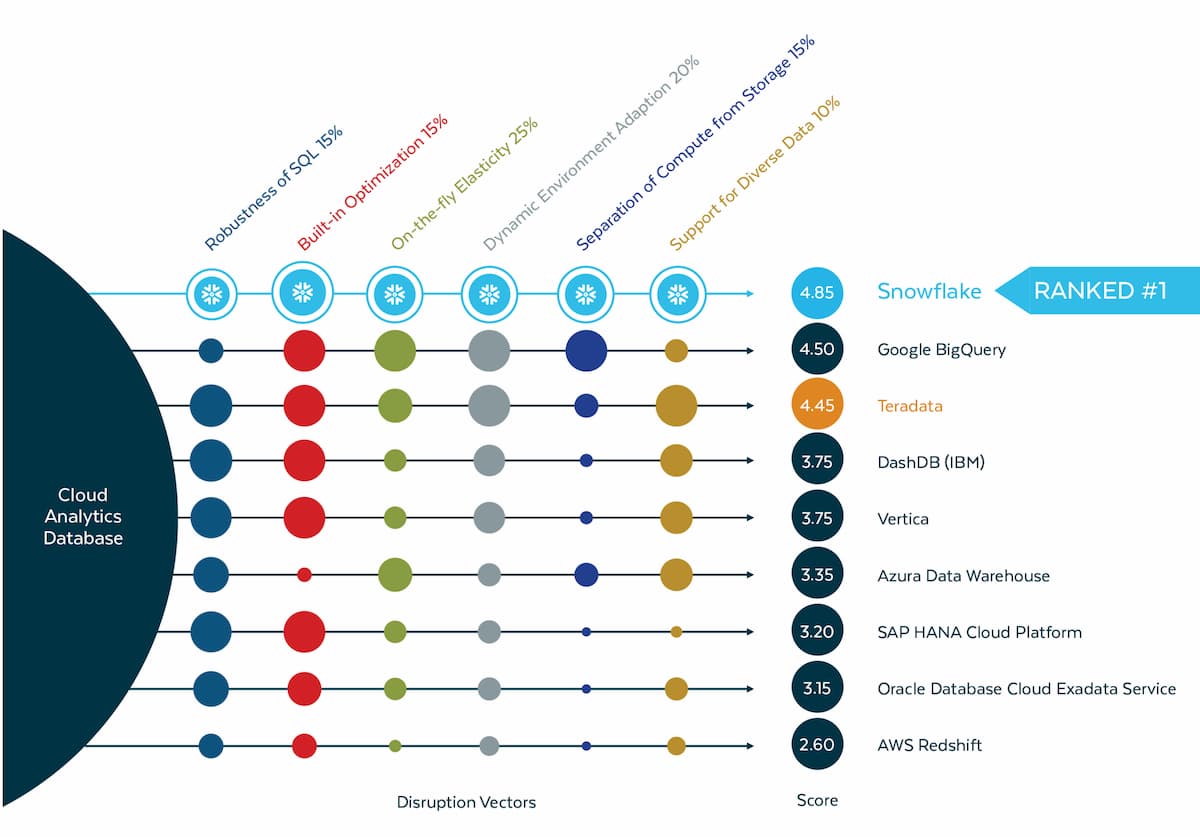
調査会社GigaOmは、2019年の一連のベンチマークテストにおいて、Snowflakeが多くのメトリクスで一貫してBigQueryを上回っていることを明らかにした。テストには、Amazon RedshiftとAzure SQL Data Warehouseという他の2つのクラウドデータウェアハウスオプションも含まれていた。
テストでは、業界標準のTPC-DSデータセットを使用。このデータセットは、電子商取引小売業者の架空のデータに基づいて「汎用的な意思決定支援システム」をモデル化するために使用されるもの。ベンチマーク結果は、制御された複雑なマルチユーザの意思決定支援ワークロードの下で、与えられたハードウェア、オペレーティングシステム、およびデータ処理システム構成について、シングルユーザモードでのクエリ応答時間、マルチユーザモードでのクエリスループット、およびデータメンテナンス性能を測定する。
GigaOm社は、合計30テラバイトのデータセットを対象に、合計103回のテストを実施。Snowflakeは、103個のTPC-DSクエリをすべて完了するのに合計5,793秒を必要としたが、BigQueryはその6倍以上の37,283秒を要した。
もちろん、すべてのユースケースにおいてSnowflakeがBigQueryよりも高速であるというのは、あまりにも単純な結論だ。例えば、GigaOmは、純利益により測定された最もパフォーマンスの高い項目と最もパフォーマンスの低い項目の調査を含むベンチマークテストのクエリーで、BigQueryがSnowflakeを上回ったことを明らかにしてもいる。
さらに、SnowflakeとBigQueryともに活発に開発が行われており、新機能やパフォーマンス強化が定期的に行われている。SnowflakeとBigQueryの現在および今後の変更点は、どちらのデータウェアハウスが真に優れたパフォーマンスを発揮するかという観点を変える可能性がある。
5. スノーフレークの欠点
- 顧客はインフラストラクチャを所有しているわけではない。つまり、緊急時に迅速に対応できるSnowflakeサポートに完全に依存していることになる。別のDWHソリューションの別のオンデマンドデプロイメントを持っていない限り、データリカバリや緩和手順を自分の側で実行することはできない。
- データを所有していない。 メタデータ(暗号化キーを含む)はデータから切り離され、Snowflakeによって別個に保存されます。クラウドサービス層が停電の影響を受けた場合、持っているS3やAzureストレージのブロブはすべて無意味になることを意味する。
- 共有クラウドサービス。クラウドサービス層は複数の顧客(VPSのものを除く)で共有されているため、クラウドサービスに関連するセキュリティインシデントが発生すると、同時に複数の顧客の顧客データが暴露される可能性があることを意味する。共有クラウドサービスのもう一つの問題点は、クラウドサービスの停止は巨大な爆発半径を持つことだ。複数の顧客に影響を与えることになり、このような障害が発生した場合にサポートを受けることは非常に問題となる。
- 顧客数の急激な増加。意外にも、これが問題になる。顧客基盤の急速な成長は、企業のサポート部門やエンジニアリング部門の負荷が急速に増加することを意味する。Snowflakeのような十分に複雑なソフトウェアソリューションの場合、通常、新しく雇われたエンジニアが生産性に達するまでに少なくとも6ヶ月はかかる。そのため、エンジニアリングチームやサポートチームの成長速度には当然限界がある。サポートの質の低下とファーストラインサポートの導入は、これの直接的な結果であり、複数の顧客から欠点として報告されている。
- プロプライエタリなコード。これは、Snowflakeの会社以外のすべてのエンジニアの専門知識のレベルに明確な上限があることを意味する。この角度はSnowflakeによって専門的なサービスの契約を販売するために使用することができるが、それは明らかに顧客、特にApache HadoopおよびApache Sparkのようなオープンソースの解決策に使用されるものにとって苦痛である。
- エコシステムが小さい。Snowflakeは競合他社に比べてまだ若い技術であるため、多くの機能がまだ不足している。地理空間、限られたUI機能、未熟なETLツールの統合などだ。
- クラウドのみ。AWSとAzureだけがデプロイの選択肢。これに追加するものは何もない。
そして、彼らの設計に直接関係するいくつかの技術的な問題が存在する。
- パーティションがない。ファクトテーブルを分割することはできない。これを回避するには、トランザクションの日付のようなフィールドでテーブルデータをソートすることができる。これにより、Snowflakeはマイクロパーティションのmin-max統計を使用して、日付でフィルタリングするクエリのために関連する日付を含まないものを刈り取ることができる。これはクラスタ化テーブルと呼ばれている。Snowflakeは、お客様のために透過的にクラスタ化されたデータを喜んで維持するが、もちろん、これを達成するために必要な計算とストレージリソースの手数料を払う。
- インデックスがない。 マテリアライズドビューがあり、異なるキーでクラスタリングされたベーステーブルのコピーを定義するだけで、高速な顧客検索クエリが得られる。これはデータのフルコピーを維持し、ベーステーブルの各DML操作をシャドーイングするために必要な計算リソースとストレージリソースのコストを犠牲にしている。
- データのバルク・ロードのみ。1つのフィールドを変更するだけでも、データブロック全体がコピーされる。これは事実上、Snowflakeの唯一の最適な運用モードはバルク挿入であり、バッチのサイズが大きいほど、データ処理と最終的なデータレイアウトがより最適になることを意味する。例として、顧客テーブルを持つ運用データストアを持ち、0.1%の顧客テーブルエントリの更新を5分ごとにDWHに配信するCDCを実行することは不可能だ。更新ごとにテーブルのフルスキャンを行う必要があり、更新時にSnowflakeエンジンが各マイクロパーティションのコピーを作成する(変更されたレコードを持つ顧客のIDが均等に分散されており、たまたま各マイクロパーティションにヒットした場合)。
- 限定されたユーザ定義関数。SaaSソリューションであるため、セキュリティ面で大きなポイントがある。これは、解釈された言語のみがユーザー定義関数で可能であることを意味し、現在サポートされているSQLとJSのみである。Pythonにはネイティブのサンドボックスソリューションがないため、Pythonスクリプトに別れを告げることになる。また、SnowflakeはPL/SQLや少なくともPL/pgSQLのようなものを導入するほど成熟していない。
- データの制約がない。NOT NULL以外の制約は強制されない。ロード時のデータ品質を確保するための「check」制約がない。
- 限定的なワークロード管理。トラフィックの一部をより高い優先度で処理したい場合は、別の仮想倉庫に隔離してください。それは機能するが、すべてのユースケースではなく、より大きな分離はより大きなコストを発生させる。Snowflakeを使用すると、クエリがS3に流出しても、OOM(Out Of Memory)障害によって効果的に死ぬことはない。自動スケーリングは、観測された負荷に基づいて自動的にそのサイズを調整する複数の仮想倉庫を実行するコストを削減するのに役立ち、Snowflakeエンタープライズ版で利用可能だ。
結論
Snowflakeは、クラウド時代に焦点を合わせた、エンタープライズ利用に好ましいデータウェアハウス。今後もRedshiftなどの競合とともに市場を分け合うことになるだろう。さらに掘り下げたい方はこちらのブログを読まれることをおすすめする。
 Takushi Yoshida
Takushi Yoshida
参考文献
- "FROM OUR FOUNDERS". Snowflake Blog. Oct 24, 2014.
- . www.geekwire.com. Retrieved Oct 8, 2020.
- Handy, Alex (October 23, 2014). "Snowflake offers cloud data warehouse as a service, cheaply". SD Times. Retrieved November 20, 2014.
- Wingfield, Nick (October 21, 2014). "Longtime Microsoft Executive Opens Cloud Database Start-Up". The New York Times. Retrieved November 11, 2014.
- Bass, Dina (October 21, 2014). "Snowflake Takes Aim at Amazon, Hadoop With New Data Service". Bloomberg.com. Retrieved November 10, 2015.
- Ron Miller. (October 21, 2014). Snowflake Computing Emerges From Stealth With $26M In Funding To Modernize The Data Warehouse. Tech Chrunch.
- Midhul Vuppalapati et al. Building An Elastic Query Engine on Disaggregated Storage. Proceesing of 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’20) February, 2020.
- B. Dageville, T. Cruanes, M. Zukowski, V. Antonov, A. Avanes, J. Bock, J. Claybaugh, D. Engovatov, M. Hentschel, J. Huang, et al. The snowflake elastic data warehouse. In SIGMOD, 2016.
- Key Concepts & Architecture. Snow Flake
- Snowflake CMU presentation slides
- Snowflake CMU presentation recording
- Official Documentation
- Customer Reviews
- Documentation. Saqib Mustafa. ELASTICITY & SEPARATION OF COMPUTE AND STORAGE.



