2D映像を3D空間構造に再配置するTransporter Network、桁違いの学習効率を達成
Googleの研究者たちは、物体を把持するロボットが、オブジェクト中心の仮定なしに、視覚ベースの操作のための空間構造を保持するシンプルなエンドツーエンドモデルアーキテクチャであるTransporter Networksを開発したと発表した。

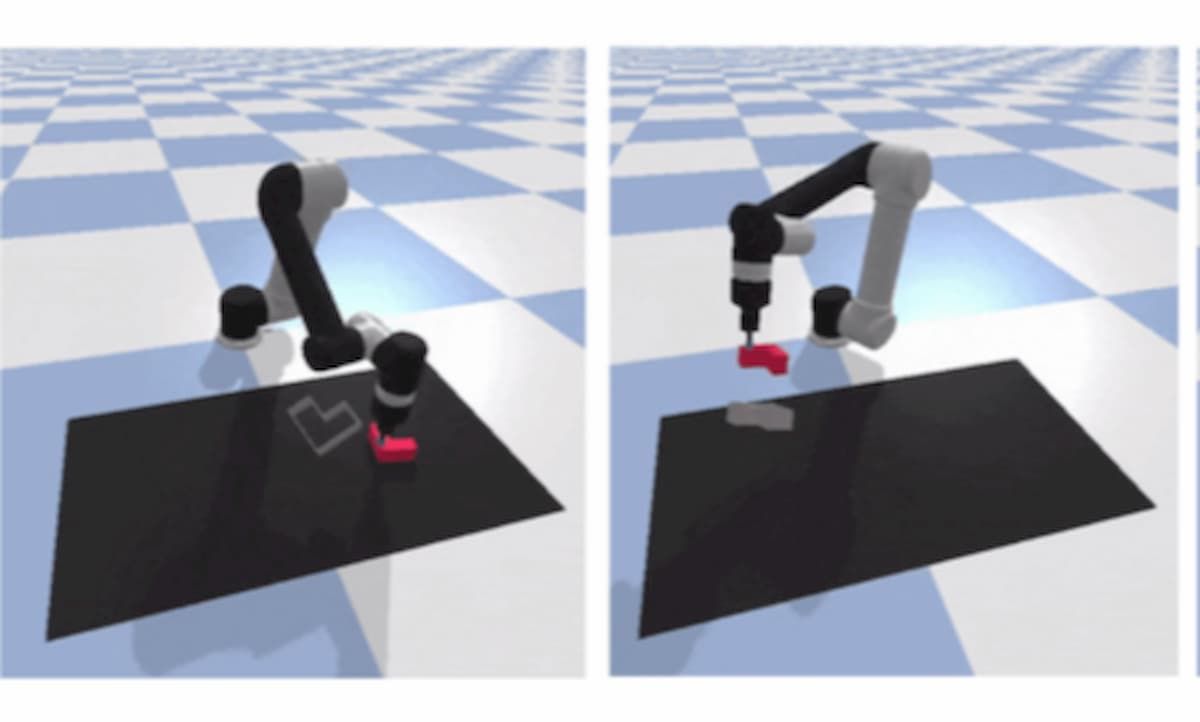
Googleの研究者たちは、物体を把持するロボットが、オブジェクト中心の仮定なしに、視覚ベースの操作のための空間構造を保持するシンプルなエンドツーエンドモデルアーキテクチャであるTransporter Networks(トランスポーター・ネットワーク)を開発したと発表した。実験の間、研究者らは、彼らのTransporter Networksは、ブロックのピラミッドを積み上げる、キットを組み立てる、ロープを操作する、小さな物体の山を押すなど、多くのタスクにおいて「優れた効率性」を達成したと主張している。
Andy ZengらRobotics at Googleのチームによると、Transporter Networksは、操作される対象物の3Dモデル、ポーズ、クラス分類に関する事前の知識を必要とせず、代わりに部分深度カメラデータに含まれる情報のみに頼っているという。また、新しいオブジェクトや構成に一般化することができ、いくつかのタスクでは、単一のデモンストレーションから学習することも可能である。実際に、10のユニークな卓上操作課題について、トランスポーターネットワークは、100の専門家による課題のビデオデモを用いて、新しい構成の物体を使ったほとんどの課題で90%以上の成功を収めたと思われる。
マニピュレーションは物を再配置することを伴うが、これは空間的な配置を変えていくことであると考えることができる。研究チームは、これらの変位を推定することとして、操作のためのビジョンを定式化している。Transporter Net-worksは、1)局所領域に着目し、2)テンプレートマッチングを介してターゲットの空間変位を予測し、マニピュレーションのためのロボットの行動をパラメータ化する学習を行うことで、これを直接最適化する。この定式化により、どの視覚的手がかりが重要であり、シーン内でどのように再配置すべきかという高レベルの知覚的推論が可能となり、その分布はデモンストレーションから学習することができる。
Transporter Networksは視覚入力の3D空間構造を保持する。先行するエンドツーエンドモデルでは、生の画像を用いた畳み込みアーキテクチャを使用することが多く、この場合、貴重な空間情報が遠近法の歪みによって失われる可能性がある。この研究チームの手法は、視覚データを空間的に一貫した表現に入力として投影するために3D再構成を使用しており、これにより、より効率的な学習のためにデータの幾何学的対称性内に存在する帰納的バイアスに対して等値性をよりよく利用することができる、と主張している。
実験では、Transporter Networksは、ロボットの環境の状態を意図的に変化させることを含む多くの卓上操作タスクにおいて、優れたサンプル効率を示した。Transporter Networksは、マルチモーダルな空間行動分布のモデル化に優れており、構造上、物体の回転や移動にまたがって一般化する。これらのネットワークは、操作される対象物の事前知識を必要とせず、デモンストレーションからの部分的なRGB-Dデータに含まれる情報のみに依存し、新しい対象物や構成に一般化することが可能であり、いくつかのタスクでは、単一のデモンストレーションからのワンショット学習も可能である。
研究者らは、1つのタスクにつき1つのデモンストレーションから1,000件までのデモンストレーションのデータセットでトランスポーターネットワークを訓練した。まず、0.5×1メートルの作業スペースを見下ろす吸引グリッパー付きのUniversal Robot UR5e装置で構成される模擬ベンチマーク学習環境であるRavens上に配置した。その後、実際のUR5eロボットと吸引グリッパーとAzure Kinectを含むカメラを使用して、キットの組み立て作業でTransporter Networksを検証した。
パンデミックに関連したロックダウンのため、研究者たちは、人々がロボットを遠隔操作できるようにするUnityベースのプログラムを使用して実験を行った。1つの実験では、遠隔操作者は、5つの小さなボトル入りのマウスウォッシュや9つのユニークな形の木製玩具のキットを、バーチャルリアリティヘッドセットまたはマウスとキーボードのいずれかを使用して、組み立てと分解を繰り返して、ピッキングと配置のポーズをラベル付けした。13人の人間の操作者からのすべてのタスクについて、合計11,633回のピック&プレース動作を用いて訓練されたトランスポーターネットワークは、ボトル入りマウスウォッシュのキットを組み立てることに98.9%の成功を収めた。
「この研究では、視覚入力からロボットの行動をパラメータ化できる、空間的な変位を推測するシンプルなモデルアーキテクチャであるTransporter Networksを発表した」とRobotics at GoogleのZheng研究員らは書いている。「このネットワークは、オブジェクト性の仮定を行わず、空間的対称性を利用し、エンドツーエンドの代替案よりもビジョンベースの操作タスクを学習する際のサンプル効率が桁違いに高い。現在の限界という点では、カメラとロボットのキャリブレーションに敏感であり、トルクと力のアクションを空間的なアクション空間と統合する方法が不明瞭なままである。全体的に、我々はこの方向性に興奮しており、リアルタイムの高速度制御や、工具の使用を含むタスクへの拡張を計画している」。
共著者らは、近い将来、コードとオープンソースのRavens(および関連API)を公開する予定だという。



