ブルームバーグ独自AIの衝撃:金融・メディア業界に激変の兆し、ドメイン特化型LLMの可能性拡張も
ブルームバーグ独自の大規模言語モデル(LLM)は金融とメディア業界を震撼させようとしている。これまで人手を費やしていた仕事が機械に巻き取られ、人類はよりクリエイティブな仕事を要求され得る。同時にLLMを様々なドメインに特化させることが示す莫大な利益の新たな証拠となった。


ブルームバーグ独自の大規模言語モデル(LLM)は金融とメディア業界を震撼させようとしている。これまで人手を費やしていた仕事が機械に巻き取られ、人類はよりクリエイティブな仕事を要求され得る。同時にLLMを様々なドメインに特化させることが示す莫大な利益の新たな証拠となった。
ブルームバーグが3月末に発表した、LLMの「BloombergGPT」について詳述した研究論文は、金融とメディア業界にとってビッグニュースだった。
BloombergGPTは500億パラメータの言語モデルを7,000億トークン(トークンは言語の最小単位を指す)のデータセットで学習させ、金融タスクにおいて現在のベンチマークモデルを大幅に上回る性能を持つ。
BloombergGPTは大手テクノロジー企業ではなくとも活用できるものを組み合わせて作られており、様々なドメイン特化型LLMが参考にできる前例となっている。これまで、LLMは生物学や化学等の分野ですでに応用されており、その成果が期待されているが、BloombergGPTは金融とニュースという新たなジャンルを開拓した。
金融業界は複雑で独特な用語が多いため、金融業界に特化したモデルが必要とされている。論文では、GPT-3や他のLLMとの一連の性能比較を行い、BloombergGPTが一般的なタスク(少なくとも同サイズのモデルと対戦する場合)では独自の性能を発揮し、多くの金融に特化したタスクでは優れた性能を発揮することを明らかにした(図表参照)。
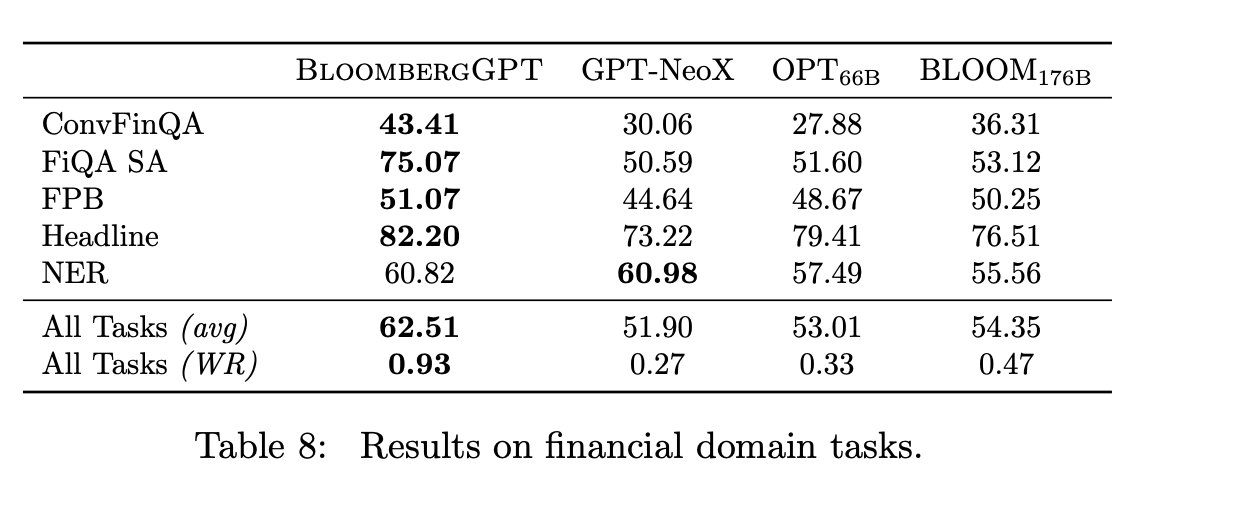
ブルームバーグは、「株式ニュースセンチメント」「株式ソーシャルメディアセンチメント」「株式トランスクリプト(文字起こし)センチメント」の3種類の分析を試した。この3種類を含むカテゴリーにおいては、BloombergGPTは平均して62.47ポイントを獲得し、BloombergGPTに最も近いスコアを出した大規模言語モデルであるOPTは、平均35.76ポイントにとどまった。
BloombergGPTは、オープンソースプロジェクトの「BLOOM」を採用。BLOOMは、46の自然言語と13のプログラミング言語で学習した1760億パラメータの言語モデルで、数百人の研究者の共同作業により開発・公開された。研究チームは、モデルのトレーニングと評価にAmazon AWSのSageMakerサービスを使用した。

ブルームバーグの活用法
BloombergGPT のモデルは公開されていない。パラメータや一般的な情報以外に、モデルの重みなどの詳細は論文では言及されていない。このモデルは数十年にわたるブルームバーグのデータに基づいており、情報の機密性が高いため、オープンソース化されない可能性もある。また、このモデルは、すでに定額でサービスを利用しているブルームバーグ・ターミナルのユーザーをターゲットに設定されていることも、閉鎖的な運営を予期させるものだ。
ブルームバーグは、基本的に金融データプロバイダーであり、1台あたり年間3万ドルの端末契約料が原動力となっている。利用者は端末から情報を引き出すのにブルームバーグ・クエリ言語(BQL)を使うが、論文は、自然言語の質問をBloombegrGPTがBQLに変換する可能性に言及している。つまり、利用者は、平易な英語でクエリを入力するだけでよいのだ。
また、ニュース記事の見出しを提案できるとも論文は言及している。
将来的にはBloombergGPTを基にしたChatGPTのような対話AIとの会話によって、何らかのインサイトを得たりできるようになることは想像に難くない。タスクによっては人間が数時間かけて行っていた処理をGPTが数十秒でこなしてしまう可能性も否定できない。
スタートアップが活躍する余地は十二分に残されていると言えるだろう。ブルームバーグは現状の高価なサブスクビジネスを維持する必要があるが、業界の新参者が同じことをしたらどうなるだろうか。例えば、月額3万ドルを負担できない小口投資家にも、より有益な金融情報が安く、そして平易に提供されることは、一番想像しやすいソリューションだ(ブルームバーグが提供したがらないものだろう)。
あるいは、LLMのセンチメント分析を基に資産を売買するヘッジファンドが登場するかもしれない。金融市場のプレイヤーがより精緻な情報に基づいて取引を行うようになり、市場の効率性が増す金融業界の長期的なトレンドである「機械化」がより促進されることも考えられるだろう。
付記:モデルのサイズ、トレーニングデータ
彼らは、英AI研究所DeepMindのSebastian Borgeaud らが提案したChinchillaのスケーリング法則を採用した(図表参照)。つまり、大手テクノロジー企業が採用する莫大なサイズを負わず、独立的企業として合理的な範囲のサイズでゲームをプレイした。これを可能にしたのは、Chinchillaの貢献とドメイン特化の妙味だろう。
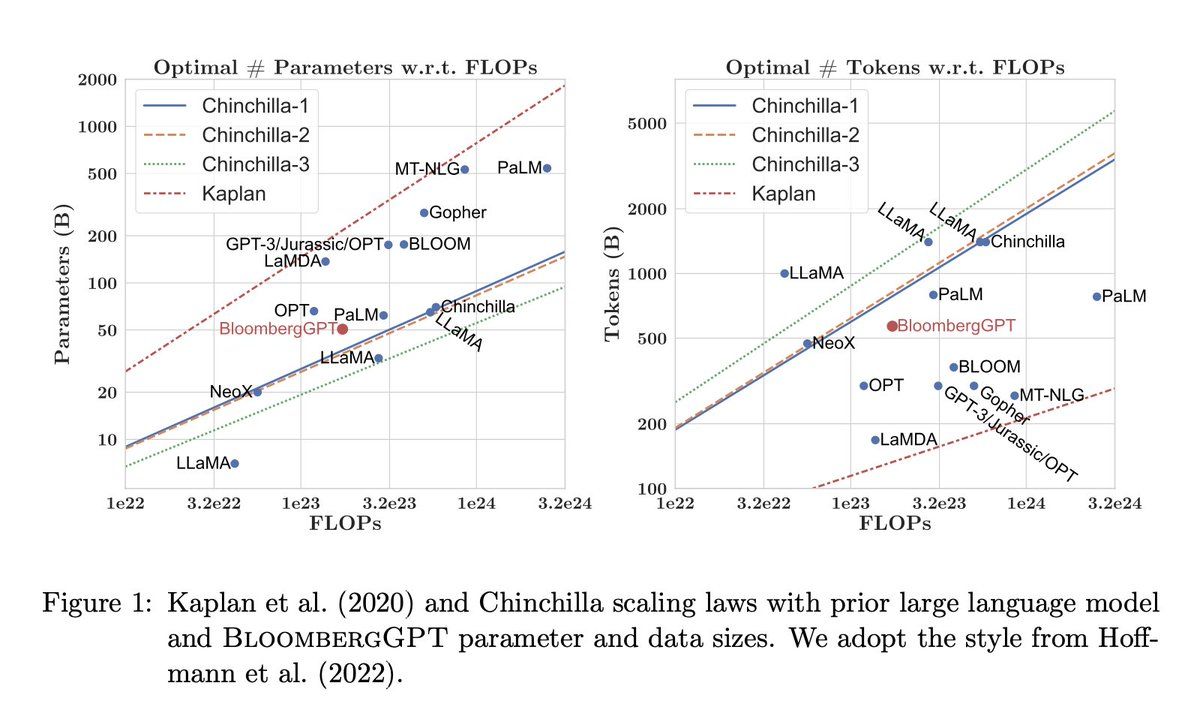
BloombergGPTはどの程度の規模なのでしょうか? 同社によると、7,000億以上のトークン(単語の断片)を含むコーパスを用いて学習させたとのことです。ちなみに、2020年にリリースされたGPT-3は約5,000億で学習された。7,000億以上のトークンのうち、3,630億はブルームバーグが保有する金融データから取得したもので、同社の端末に搭載される情報であり、「ドメイン特化のデータセットとしては過去最大」と同社は述べている。さらに3,450億トークンは、他所から入手した「汎用データセット」からのものだ。
同社所有のデータセットの中にはFinPileと名付けられたものがあるが、これは「Bloombergのアーカイブから抽出したニュース、ファイリング、プレスリリース、ウェブスクレイピングされた財務文書、ソーシャルメディアを含む様々な英語の財務文書」で構成されている。その他、SEC提出書類、ブルームバーグTVの記録、FRBデータ、そして "金融市場に関連するその他のデータ」も含まれるという。ブルームバーグ以外のニュースソースもトレーニングデータに採用されている。



