AIチップメーカーCerebras: 巨大チップによる深層学習への挑戦
1.2兆個のトランジスタ、40万個のプロセッサコア、18ギガバイトのSRAM、1秒間に1,000億ビットを動かすインターコネクトを備えたCerebrasのウェハースケールエンジンは、他のシステムと簡単に比較することができない。チップの面積は他のプロセッサよりも50倍以上大きい。


CS-1のコンピュータの各筐体の約4分の3が冷却システムで占められている。その最後の4分の3の内部にあるのが、真の革命とも言える、1つのチップだけで構成された巨大なコンピュータだ。しかし、この1つのチップの面積は46,255平方ミリメートルにも及び、他のどのプロセッサチップよりも50倍以上も大きい。1.2兆個のトランジスタ、40万個のプロセッサコア、18ギガバイトのSRAM、1秒間に1,000億ビットを動かすことができるインターコネクトを備えたCerebras社のウェハースケールエンジン(WSE)は、他のシステムと簡単に比較することができない。
Cerebrasが引用している統計は驚くべきものだ。同社によると、10ラックのTPU2クラスタ(現在3世代のGoogle AIコンピュータの2番目のクラスタ)は、WSEを搭載した1台のコンピュータの3分の1の性能を実現するために、5倍の電力を消費し、30倍のスペースを必要とするという。単一の巨大なチップが本当にAIコミュニティが待ち望んでいた答えなのかどうかは、今年になって明らかになるはずだ。
シカゴ近郊のスーパーコンピューティング大手アルゴンヌ国立研究所などの顧客は、すでに自社の敷地内にマシンを設置している。
Cerebrasの創設者たち、つまりAMDが買収したSea Microのサーバー事業のベテランたちが2015年に会合を開いたとき、彼らは現代のAIの作業負荷の性質に完全に適合するコンピューターを作りたいと考えていたという。これらの作業負荷は、いくつかのことによって定義されています。多くのデータを素早く移動する必要があること、処理コアに近いメモリが必要であること、他のコアがクランチしているデータを処理する必要がないことだ。
このことは、同社の最高技術責任者であるゲイリー・ラウターバッハを含む、同社のベテランコンピュータアーキテクトたちに、すぐにいくつかのことを示唆していた。第一に、より汎用的なコアを少なくするのではなく、関連するニューラルネットワーク計算を行うように設計された数千、数千の小型コアを使用することだ(ドメイン固有アーキテクチャ = DSA)。第二に、これらのコアは、データを高速かつ低エネルギーで移動させる相互接続スキームで一緒にリンクされなければならない。そして最後に、必要なデータはすべてプロセッサ・チップ上にあり、別個のメモリ・チップではない。
これらのコアとの間でデータを移動させる必要性があることが、WSEのユニークさの大きな部分を占めている。2つのコア間でデータを移動させるための最速かつ低エネルギーの方法は、同じシリコン基板上に2つのコアを配置することだ。データが1つのチップから別のチップに移動しなければならない瞬間、距離が長くなり、信号を運ぶ「ワイヤ」がより広く、より密に詰まっていない必要があるため、速度と電力の面で大きなコストがかかる。
すべての通信をシリコン上に維持するためには、小型コアとローカルメモリへの欲求と相まって、可能な限り大きなチップを作る必要があり、おそらくシリコンウエハ全体と同じくらいの大きさのチップを作る必要がある。
ウェハースケールのチップの先行例
何十年もの間、エンジニアたちは、ウェハースケールのチップは行き詰まると思い込んでいた。結局、IBM System/360メインフレームのチーフアーキテクトである故ジーン・アムダールほどの著名人はいなかったが、トリロジー・システムズという会社はそれにトライしてみたが、見事に失敗した。しかし、アムダールが使っていたウェハーは、今日の10分の1の大きさであり、それらのウェハー上のデバイスを構成する機能は、今日の30倍の大きさだった。
さらに重要なことは、トリロジー社はチップ製造で発生する避けられないエラーを処理する方法を持っていなかった。他のすべての条件が同じであれば、チップが大きくなればなるほど、欠陥が発生する可能性は高くなる。もしチップのサイズがレターサイズの紙一枚分の大きさであれば、チップには欠陥があることを覚悟しなければならない。
しかし、ラウターバッハはアーキテクチャ上の解決策を考えた。彼らがターゲットとしていたワークロードは、何千もの小さな同一のコアを持つことが好まれるため、そのうちの1%でも欠陥による故障を考慮して十分な冗長コアを搭載することが可能であり、それでも非常に強力で非常に大きなチップを実現することができた。
もちろん、Cerebras社は、欠陥に強い巨大チップを構築するために、多くの製造上の問題を解決しなければならなかった。例えば、フォトリソグラフィツールは、特徴を定義するパターンを比較的小さな長方形にキャストするように設計されており、それを何度も何度も繰り返すことになる。この制限だけでは、ウェハ上の異なる場所に異なるパターンをキャストするコストと困難さのため、多くのシステムを1枚のウェハ上に構築することはできない。

しかし、WSEはそれを必要としない。これは、通常製造されているのと同じように、全く同じチップが詰まった典型的なウエハに似ている。大きな課題は、これらの擬似チップをつなぎ合わせる方法を見つけることだった。チップメーカーは、各チップの周りにスクライブラインと呼ばれるブランクシリコンの狭いエッジを残す。ウエハは通常、これらの線に沿ってサイコロ状に切り取られる。Cerebrasは台湾半導体製造(TSMC)と共同で、各擬似チップのコアが通信できるように、スクライブラインをまたいで相互接続を構築する方法を開発した。
すべての通信とメモリを単一のシリコンスライス上で実現したことで、データのやり取りがスムーズになり、コアからコアへの帯域幅は毎秒1,000ペタビット、SRAMからコアへの帯域幅は毎秒9ペタバイトになった。
必要とされた発明は、スクライブライン交差インターコネクトだけではなかった。チップ製造用のハードウェアを変更しなければならなかった。電子設計自動化のためのソフトウェアでさえも、このような大きなチップで作業するためにカスタマイズしなければならなかった。
ウエハースケールの統合は、この40年間、否定されてきたが、Celebrasがそれを成し遂げた今、その扉は他の企業にも開かれているかもしれない。
実際、イリノイ大学とカリフォルニア大学ロサンゼルス校のエンジニアたちは、Cerebrasのチップが、シリコン相互接続ファブリックと呼ばれる技術を使った独自のウェハースケール・コンピューティングの取り組みを後押しするものだと考えている。
CS-1は、もちろんWSEチップ以上のものだが、それ以上のものではない。これは、デザインと必要性の両方によるもの。マザーボードは、チップの上にある給電システムと、その下にある水冷式のコールドプレートで構成されている。驚くべきことに、コンピュータの開発で最大の課題となったのは電源供給システムだった。
WSEの1.2兆個のトランジスタは、プロセッサとしてはかなり標準的な約0.8ボルトで動作するように設計されている。しかし、その数は非常に多く、全体で2万アンペアの電流を必要とする。大幅な電圧降下なしに20,000アンペアの電流をウェハに流すことは、冷却や歩留まりの問題に対処するよりもはるかに困難なエンジニアリング上の課題という。
WSEの端から電力を供給することはできない。インターコネクトの抵抗がチップの中央に到達するずっと前に電圧をゼロに落としてしまうからだ。そこで、上から垂直に電力を供給することにした。Celebrasは、電源制御用の特殊な目的のチップを何百個も収納したグラスファイバー製の回路基板を設計した。100万個の銅製のポストが、グラスファイバー基板からWSE上のポイントまでの1ミリほどの距離を橋渡ししている。
この方法で電力を供給するのは簡単そうに見えるかもしれないが、そうではない。動作中、チップ、回路基板、コールドプレートはすべて同じ温度まで温まりますが、その際に膨張する量が異なります。銅は最も膨張し、シリコンは最も小さく、グラスファイバーはその中間に位置している。このようなミスマッチは、通常サイズのチップでは頭痛の種となります。WSEサイズのチップでは、わずかなパーセンテージの変化でもミリ単位の変化になる。
マザーボードとの熱膨張係数の不一致という課題があり、Cerebrasは、シリコンとグラスファイバーの中間的な熱膨張係数を持つ素材を探した。それだけでは、100万個の給電ポストを接続し続けることはできなかった。しかし、最終的にはエンジニアが自分たちで発明しなければならなかった。
WSEは、NvidiaのTesla V100グラフィックス処理ユニットやGoogleのTensor Processing Unitなど、一般的にニューラルネットワーク計算に使用されている競合チップよりも明らかに大きい。しかし、それは必ずしもより優れているということを意味するわけではない。
2018年、Google、Baidu、そしていくつかのトップアカデミックグループは、システム間での比較を可能にするベンチマークに取り組み始めた。その結果、2018年5月にMLPerfというトレーニングベンチマークが公開されている。
これらのベンチマークによると、ニューラル・ネットワークを学習する技術は、ここ数年で大きな進歩を遂げています。ResNet-50の画像分類問題では、1,500GPUのスーパーコンピュータであるNvidia DGX SuperPODが80秒で終了しました。Nvidia社のDGX-1マシン(2017年頃)では8時間、2015年に発売された同社のK80を使っては25日かかった。
最近では、GoogleのTPUv4とNvidiaのAmpere A 100は、ともにこのベンチマークを基に優位性を主張している。
CerebrasはMLPerfの結果や、その他の検証可能な比較を発表していない。その代わりに、同社は顧客に独自のニューラルネットワークとデータを使ってCS-1を試してもらうことを好んでいる。どの企業も自分のビジネスのために開発した独自のモデルを実行しており、そのモデルに最も相応しいかがAI計算資源の選定理由になる。
初期の顧客であるアルゴンヌ国立研究所には、かなり激しいニーズがある。異なるタイプの重力波イベントをリアルタイムで認識するためのニューラルネットワークを訓練するために、科学者たちは最近、アルゴンヌ国立研究所のメガワットを消費するシータ・スーパーコンピュータのリソースの4分の1を使用したという。
Cerebrasのソフトウェア面
セレブラスは、2019年11月にデンバーで開催されたスーパーコンピューティングカンファレンス「SC19」で、システムのソフトウェア側の詳細を一部公開した。CS-1のソフトウェアは、PyTorchやTensorFlowなどの標準的なフレームワークを使って、ユーザーが機械学習モデルを書くことを可能にする。その後、CerebrasのWafer Scale Engineチップの様々なサイズの部分をニューラルネットワークのレイヤーに割り当てる。これは、最適化問題を解くことで、各レイヤーがほぼ同じペースで作業を完了し、隣のレイヤーと連続していることを保証し、情報が滞留することなくネットワークを流れるようにする。
このソフトウェアは、最適化問題を複数のコンピュータで実行することができ、コンピュータのクラスタを1つの大きなマシンとして機能させることができます。Cerebrasは16台ものCS-1をリンクして、約16倍のパフォーマンスを実現しています。これは、グラフィックス・プロセッシング・ユニット(GPU)に基づくクラスタの動作とは対照的という。
同社のNatalia Vassilievaによるブログ記事によると、40万コアと最大のGPUの60倍のシリコンを搭載したCerebras CS-1は、大規模なスケールアウトによってのみ達成されるアクセラレーションを提供するように設計された単一システムだ。従来のクラスタよりもはるかに小さなバッチサイズで、データ並列レイヤのシーケンシャル実行を、より少ないウェイト同期オーバーヘッドで実行することができる。これは、9.6PB/sのメモリ帯域幅と、すべての計算コアと同じシリコン基板を共有する低レイテンシ、高帯域幅のインターコネクトによって可能になった。これは、大規模なバッチサイズや特別なオプティマイザ、ハイパーパラメータのチューニングを必要とせずに、既存のモデルのデータ並列トレーニングを「ただ機能する」ことを意味する。
スモールバッチのレイヤシーケンシャル・トレーニングを可能な限り高速化することに加えて、CS1はモデルの並列スケーリングを大幅に簡素化する。レイヤーパイプライン実行では、異なる入力サンプルに対して複数のレイヤー(またはレイヤーのブロック)をパイプライン的に並列実行することができる。このモードでは、各「ワーカー」には40万個の処理要素のサブセットが割り当てられます。これらのワーカーは、プロセッサのサブセットに局所的に留まる特定の重みと命令のセットで、特化することができるようになった。各ワーカーは継続的に同じ処理を実行し、必要なすべてのパラメータを高速なローカルメモリに保持する。
重みの冗長コピーを排除することで、より大規模なネットワークの訓練が可能になる。重みやグラデーションを交換する必要がないため、同期化オーバーヘッドを回避することができる。重みやグラディエントの代わりに、各サンプルの活性化は、あるワーカーから次のワーカーにローカルに渡される。大規模なミニバッチでは、グラディエントを交換するよりもメモリ帯域幅を必要とする場合があるため、レイヤ・パイプライン・トレーニングはCS1の高メモリ帯域幅に特に適している。
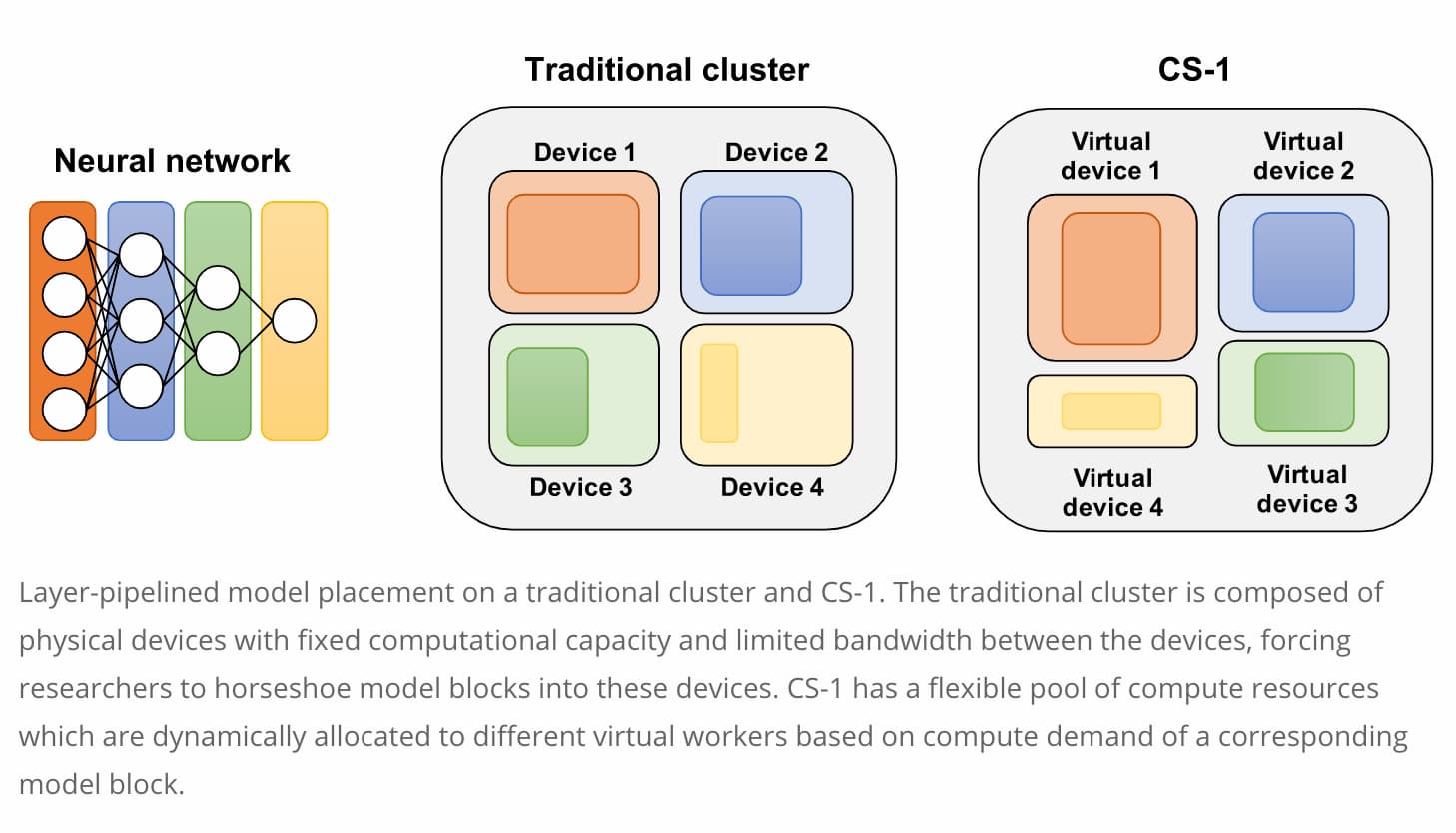
各ワーカーの計算能力が対応するアクセラレータによって定義され、柔軟性がない従来のアクセラレータのクラスターとは対照的に、CS-1は異なる仮想ワーカーに動的に割り当てられる計算リソースの柔軟なプールを提供する。重みの異なるオブジェクトの例え話に戻りますが、CS-1では、これらのオブジェクトを分割するセットの数はあらかじめ定義されておらず、セットごとの総重みが同じである必要もない。CS-1上では、与えられたモデルに必要なだけの仮想ワーカーを割り当てることができ、各ワーカーは、与えられたレイヤまたはレイヤブロックに必要なだけの計算能力(またはコア数)を得ることができる。この最適な割り当ては、Cerebras Software Stackによって自動的に行われる。
確率的勾配降下は、ネットワークに入力のミニバッチを順次投入し、重みを更新して次のバッチを処理する前に、結果として得られるすべての勾配が蓄積されるのを待つことによって、レイヤパイプライン実行のために実装されている。パイプラインは繰り返しサンプルで満たされ、ウェイト更新を実行するためにドレインされる。 各ミニバッチの開始時と終了時には、一部の作業員がアイドル状態のままになる。並列ステージの数に比べてバッチサイズが大きい場合、最も高い利用率が得られる。数十層のレイヤーを持つほとんどの一般的なネットワークでは、これは小さなバッチサイズの場合に当てはまる。そうでないネットワークでは、次のセクションでは、このオーバーヘッドを完全に排除する方法を説明する。
Photo by Cerebras



