GeminiとGPT、どちらが先を行く?
グーグルが12月初旬にGeminiをリリースした。Geminiは実際のプロダクトとして「マルチモーダル」を成立させ、言語モデルの性能競争に過度に集中していたAI界に新たな次元を出現させた。


グーグルが12月初旬にGeminiをリリースした。Geminiは実際のプロダクトとして「マルチモーダル」を成立させ、言語モデルの性能競争に過度に集中していたAI界に新たな次元を出現させた。
OpenAIのチャットボットChatGPTは、GPT(Generative Pre-trained Transformer)として知られるニューラルネットワークに基づいており、大量のテキストデータによって学習されている。一方、GoogleのBardはもともとLaMDA(Language Model for Dialogue Applications)と呼ばれる対話用学習モデルに基づいて開発された。しかし、Googleは12月初旬、BardをGeminiという新しい基盤に基づいてアップグレードした。
Geminiの特徴は、「マルチモーダルモデル」と呼ばれる点だ。これは、Geminiがテキストだけでなく、画像、音声、ビデオといった様々な種類の情報を理解し、扱えることを意味する。つまり、Geminiは多様な方法で情報を受け取り、反応できるということだ。たとえば、テキストで質問をするだけでなく、写真を見せて質問することもできるようになっている。このように、Geminiは様々な形式の情報を組み合わせて使うことが可能な先進的なAIモデルだ。
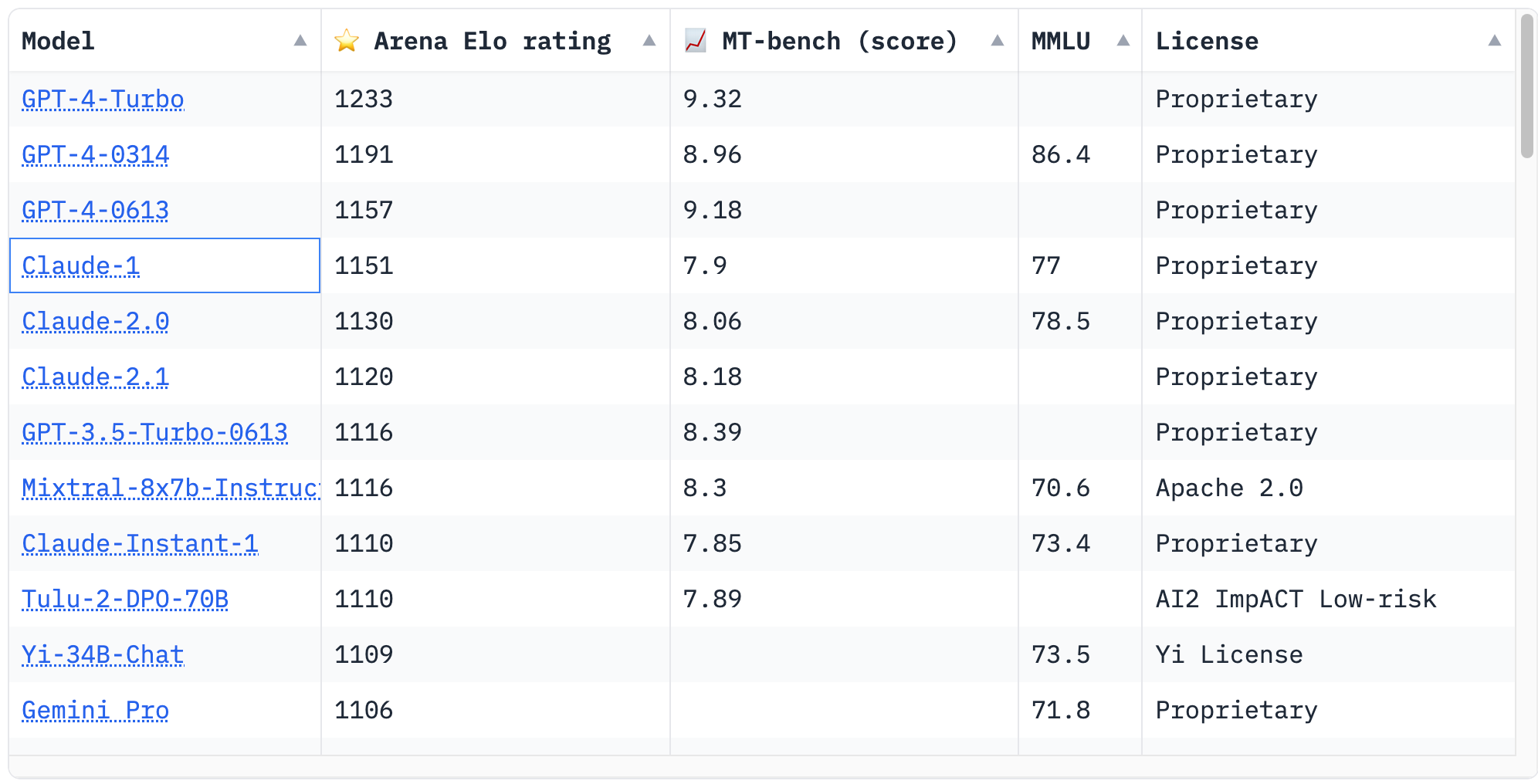
チャットボットの用途に限定すれば、GPTが首位をキープしているかもしれない。機械学習モデルの開発と共有、公開をするためのプラットフォーム「Hugging Face」のchatbot-arena-leaderboardで、3つのベンチマークによる評価では、GPT−4が首位に立ち、元OpenAIの研究者が立ち上げたAnthropicの「Claude」が続いている。フランスの新興企業Mixtralのモデルも検討し、中級モデルGemini Proは現状、その下にいる(下図)。上級モデルGemini Ultraのベンチマークが出た時、GPTとGeminiの決戦の戦況が明確になるだろう。
- Gemini Ultra - 非常に複雑なタスクに対応する最大かつ最も高性能なモデル。
- Gemini Pro - 幅広いタスクのスケーリングに最適なモデル。
- Gemini Nano - オンデバイスタスク向けの最も効率的なモデル。

しかし、より広範なタスクをこなすという意味では、Geminiが大きくリードしたかもしれない。グーグルが公開したGemini UltraとGPT-4のベンチマーク比較では、Gemini Ultraがチャットボット用途を含むテキストから、画像、動画、音声のすべてで、画像、音声、テキストも扱える GPT-4Vision(以下GPT-4V)を凌駕したということになる。そして、9月に発表されたGPT-4Vは、Geminiが約束するような完全なマルチモーダルモデルではないため、マルチモーダルではOpenAIが追う立場に立たされた可能性が高い。

画像用途では伯仲
AI新興企業LangChainは、Gemini Pro VisionをGPT-4Vと対決させ、スライドデッキに基づく質問にどれだけ答えられるかを確かめた。LangChainのチームは「同じOpenClip(*1)埋め込みモデルを使用した場合、GPT-4Vのパフォーマンスに匹敵し、埋め込まれた画像の要約に基づいて検索した場合、1つの質問しか逃さなかった」と結論づけた。
Gemini ✨is natively multimodal, but how does it stack up against GPT-4V?
— LangChain (@LangChainAI) December 13, 2023
We put gemini-pro-vision head-to-head with the reigning champ to see how well it could answer questions based on a multimodal slide deck.
The results? Gemini seems to be a formidable model, matching… pic.twitter.com/L66Y7jePaH
エッジ向けマルチモーデルの未来は?
余り注目を浴びていないが、軽量モデルのGemini Nanoは、すでにGoogleの旗艦スマホPixel 8 Pro上で生成AI機能を強化している。エッジにおけるAIチップの性能も増してきており、テキスト生成や画像生成、自動走行のようなユースケースも見つかりつつある。
スマートフォン上で、データセンターとのやりとりがなくとも、ChatGPTのような言語AIや画像生成AIを動作させられることが当たり前になりそうだ。今後は自動車のようなソフトウェア制御の比重が高まる製品でも同様の変化が見られるだろう。

脚注
*1:「Open CLIP」は、OpenAIが開発した、画像とテキストの関連性をランク付けするニューラルネットワーク



