Uber Eatsでの調理時間、到着時間、配達時間の予測
Uber Eatsでは、デリバリーパートナーには、料理ができた瞬間にレストランに到着してもらう必要があり、時間予測は注文のライフサイクル全体にわたって常に重要な役割を果たす。貪欲なマッチングアルゴリズムでスタートしたが、時間予測を利用したグローバルなマッチングアルゴリズムを使用する。


要点
- Uber Eatsでは信頼性を確保することを最優先事項の一つとしている。デリバリーパートナーには、料理ができた瞬間にレストランに到着してもらう必要があり、時間予測は注文のライフサイクル全体にわたって常に重要な役割を果たしている。
- Uber Eatsの配車システムは、貪欲な(Greedy)マッチングアルゴリズムでスタートしたが、時間予測を利用した包括的な(Global)マッチングアルゴリズムを使用することで、より効率的な配車が可能になった。
- Uberの社内機械学習プラットフォームであるMichelangelo(ミケランジェロ)は、データサイエンティストやエンジニアが機械学習の問題を解決するための全体的なプロセスを簡素化する上で、非常に大きな助けとなった。
- O2O(オンラインツーオフライン)ビジネスモデルでは「基底真実データ」が得難いという最大の課題は、フィーチャーエンジニアリング作業によってラベルデータを推論し、フィードバックループを活用してモデルの再学習を行うことで解決された。推定された納期予測モデルは、様々な段階で新たに浮上した情報の独自性により、様々なシナリオに柔軟に対応できるように設計されている。
Uber Eatsは、2015年12月にトロントでのサービス開始以来、急成長を遂げているフードデリバリーサービスの一つ。2019年11月現在、世界600都市以上で利用可能で、22万店以上のレストランパートナーにサービスを提供しており、2018年の総予約数は80億件に達している。
配達時間を正確に予測できることは、顧客の満足度とリテンション(継続利用)に最も重要な要素だ。さらに、配送パートナーを派遣する時間を計算するため、時間予測は供給側でも重要だ。
Uber Eatsでの機械学習
Uber Eatsは機械学習を活用してこれらの課題に取り組んでいる。
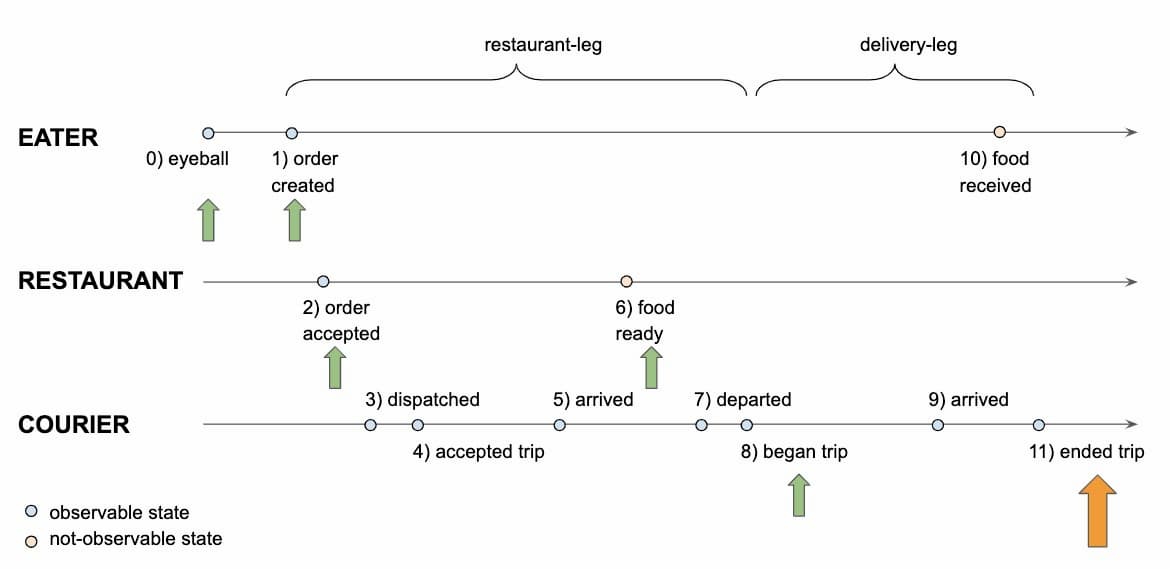
まず、遅延が発生した場合のフラストレーションを回避するために、納期を正確に予測して期待値を設定する必要がある。次に、宅配業者に食材を取りに来てもらうための最適なタイミングを計算しなければならない。理想的には、食材の準備ができた瞬間にレストランに到着するのが理想的だ。あまりにも早く到着すると、レストランの駐車場や食堂のスペースを占領してしまう。一方、到着が遅れると、食品の冷却が悪くなる。このように、時間予測は注文のライフサイクルにおいて常に重要な役割を果たしており、下図のようになっている。
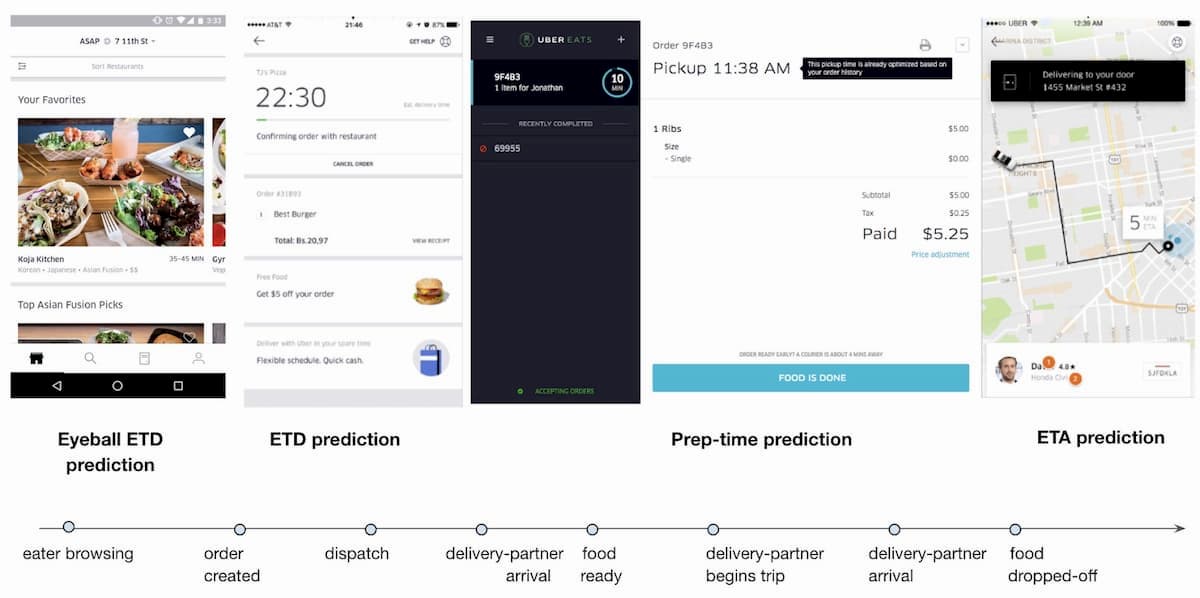
機械学習技術を活用せずに精度を確保する方法は他にない。しかし、そのコアとなる開発には、途中で課題が発生する。他の機械学習の問題と比較すると、最大の課題は、オンライン・ツー・オフライン(O2O)のビジネスモデルではかなり一般的な「基底真実データ」の欠如だ。しかし、規定データは、"garbage in, garbage out"(「『無意味なデータ』をコンピュータに入力すると『無意味な結果』が返される」)という言葉があるように、機械学習において最も重要な要素だ。もう1つは、Uber Eatsが3面(デリバリーパートナー、レストラン、食べる人)のマーケットプレイスとしての独自性を持っていることで、すべてのパートナーを考慮に入れて意思決定を行う必要があるということだ。
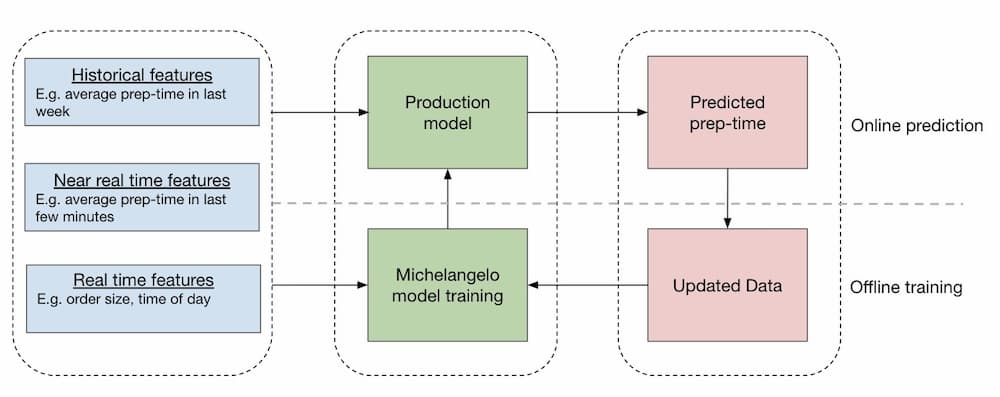
幸いなことに、Uberの社内機械学習基盤であるMichelangeloは、データサイエンティストやエンジニアが機械学習の問題を解決するための全体的なプロセスを簡素化する上で大きな助けとなっている。データ収集、フィーチャーエンジニアリング、モデリング、オフラインとオンラインの両方の予測などのための汎用的なソリューションを提供しており、車輪を再発明するのに比べて多くの時間を節約することができる。
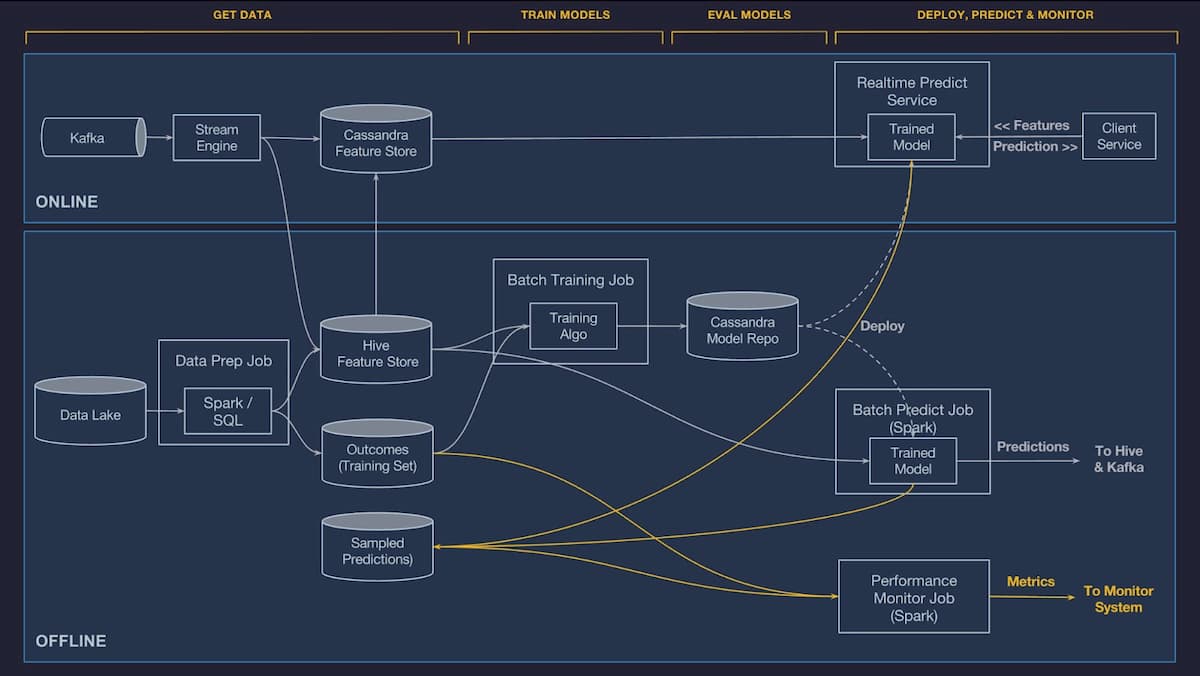
上図は、オンラインとオフラインの両方の予測パイプラインの概要を示している。オンラインの部分は、主にKafkaを介して収集され、SamzaやFlinkなどのストリーミングエンジンで前処理されたリアルタイムやニアリアルタイムのデータを使って予測を行うためのもの。最終的には、それらはCassandraのフィーチャーストアで永続化される。オフラインの部分では、さまざまなソースから収集されたデータはSparkSQLで前処理され、HIVEフィーチャストアに永続化される。その後、Spark MLlibのすべてをサポートしているプラットフォームが提供するアルゴリズム、いくつかのディープラーニングモデルなどに基づいてモデルをトレーニングしていく。
時間予測が派遣システムをどう動かすか
派遣システムがどのように機能しているのか、時代予測をして進化してきたのかを見ていく。高いレベルから見れば、派遣システムがイーツビジネスの頭脳であることは明らかだ。その目的は、最適な需要と供給のマッチングを決定することだ。私たちの文脈では、需要とはイーターの注文であり、供給とはデリバリーパートナーのことだ。タイミングが重要だが、食材の準備ができた瞬間にデリバリーパートナーがレストランに到着するようにする必要がある。
現在の段階に到達するまでに何度も繰り返した、とUberのエンジニアリングマネジャーZi Wangは語っている。最初は、食材を取りに行くために配達相手を派遣するタイミングを決めるための推測値を固定した状態でスタートした。例えば、17時30分に注文した場合、料理の準備に25分、配達員がレストランに着くまでに5分かかると仮定し、17時50分から派遣を開始する。どうやら、1品でも10品でも、そのレストランからの注文に25分を使うのは科学的ではないようだ。その結果、各パートナーの間で混乱が起こり、食べ手が正確に料理を把握できなかったり、デリバリーパートナーがレストランでの待ち時間が長くなったり、料理が冷めている間にデリバリーパートナーがどこにいるのかわからなくなったりするなどの問題が発生していた。
時間予測を導入してからは、主な要因を両方とも仮定から機械学習に基づいた予測に置き換えた。1つ目は、食材の準備時間予測でした。同じレストランからのすべての注文に25分を使うのではなく、訓練された機械学習モデルを使って、次の例では30分というように、注文ごとに予測を行った。
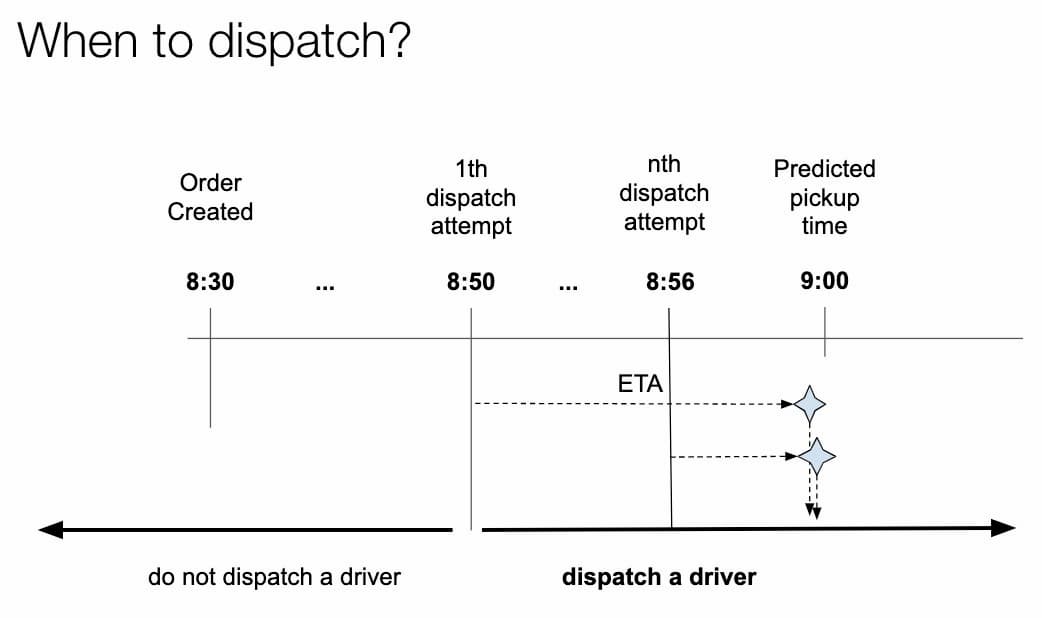
一方、すべての配送パートナーの移動時間を5分とするのではなく、機械学習モデルを使って対象となる配送パートナーの移動時間を推定することで、例の食品準備時間の10分前から派遣を開始した。すべてのパートナーからの満足度が大幅に向上した。注文した人は、明確な期待を持って迅速な配達を受けることができた。レストランと配送パートナーの両方が効率的になり、より多くの注文を時間内に完了できるようになった。
さらに、ディスパッチプラットフォームは、貪欲なマッチングアルゴリズムからグローバルなマッチングアルゴリズムに変更された。
貪欲なマッチングアルゴリズムは、注文が入ってきたときにのみ配送パートナーを探し始める。その結果、1つの注文に対しては最適なのですが、グローバルな視点から見るとシステム内のすべての注文に対しては最適ではない。そこで、注文と配送パートナーのセット全体を1つのグローバル最適化問題として解くことができるように、グローバル・マッチング・アルゴリズムに変更した。
下の図のように簡単に比較してみましょう。左の図は、貪欲なマッチング・アルゴリズムを示している。最初の注文が入ってくると、私たちの派遣システムは、レストランに到着するのに1分かかるであろう最も適格な配送パートナーとそれをマッチングする。次に2番目の注文が入ってくると、システムは5分かかる配送業者とそれをマッチングする。つまり、合計の移動時間は6分。
右の図は、新しい派遣システムが注文と配送パートナーの両方を同時に考慮し、グローバル最適な方法でマッチングするグローバルマッチングアルゴリズムを示している。その結果、両方の配送パートナーの所要時間は2分で、合計の移動時間はわずか4分となる。
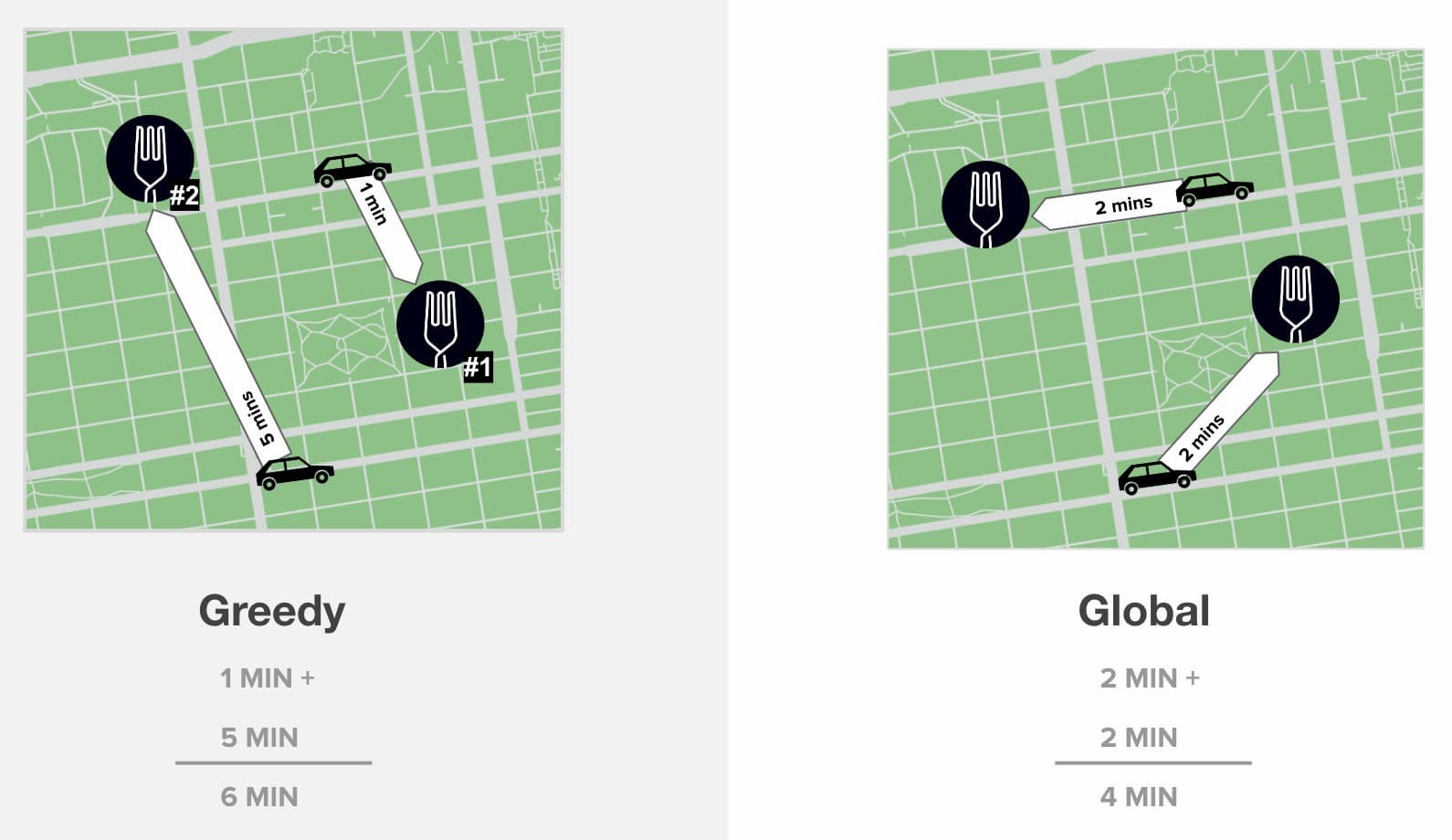
グローバル・マッチング・アルゴリズムの方がはるかに効率的であることは明らかだ。しかし、マッチングの決定を行うためには時間がより敏感で重要であるため、正確な時間予測なしでは生きていけない。これが、時間予測を導入した後でしかグローバル・マッチング・アルゴリズムに切り替えることができなかった主な理由の1つでもある。
時間予測
食材の調理時間予測は、配送先の派遣時期を決定する主な要素であるため、ビジネスにとって極めて重要だ。前述したように、O2Oビジネスモデルに機械学習を適用する際の最大の課題の1つは、地真理の収集であり、ここでは食材の調理時間予測がその典型例となる。私たちは物理的にレストランにいるわけではないし、レストランは関連情報を提供するインセンティブを持っていないため、料理の準備がいつになるかを知ることはほぼ不可能だ。
エンジニアリングチーム配達パートナーやレストランからの他のシグナルを利用して、地に足のついた真実を推測することだ。しかし、駐車場の空き状況や、レストランの入り口を探すために歩いているなど、予測できない状況があるため、必ずしも正確ではない。そこで、私たちは当初から2つの領域に着目した。1つは、フィーチャーエンジニアリングで得られたデータをいかに活用するか、もう1つは、ラベルデータを推論してモデルの精度を高め、フィードバックループを活用してモデルの再訓練を行うかということだ。
フィーチャーエンジニアリングの作業では、過去1週間の平均調理時間のようなヒストリカルフィーチャ、過去10分間の平均調理時間のようなニアリアルタイムフィーチャ、時間帯、曜日、注文サイズなどのリアルタイムフィーチャの3つのセットに分けている。リアルタイム機能とニアリアルタイム機能を必要とした理由は、急激に変化する可能性のある状況に対応するために余分な情報が必要だったからだ。例えば、悪天候の影響を受けて、注文と配送パートナーの間の分布が変化する可能性がある。
私たちの特徴選択の仕事の一例として、料理タイプの特徴に表現学習を活用している。リアルタイムの特徴量では、すでに価格や品数などの注文特有のデータを考慮している。しかし、単に何個入っているかを知りたいだけではなく、ビーフシチューとサラダのように、料理の種類によって料理の準備時間が大きく異なる可能性があるため、どのような料理が入っているかを知りたいと考えている。そこで、料理の種類を考慮してモデルの精度を向上させるために、メニューデータを用いて単語の埋め込みを生成し、それを異なるカテゴリに分類し、リアルタイムの特徴量の一部としている。
一方で、推論ラベルデータの精度を向上させるために、新たな信号を収集する方法を常に模索している。配達相手の携帯電話からのセンサー信号もその一つ。これは主に、複雑な状況下での配送先の状況を検知するためのものだ。例えば、レストランの近くにいるのに集荷が遅れてしまう場合、その原因がレストランの場所がわかりにくいのか、駐車場が見つからないのかを知る必要がある。ここでは、センサーデータをもとに、現在の状態から次の行動を予測する。
使用した方法は、条件付きランダムフィールドモデリングを介して、シーケンスのセットから現在の状態が何であるかを分類するターゲットとの間で行われている。この可能性モデルを活用し、いくつかのトリップのシーケンシャルデータにラベルを付けることで、駐車場から食品の受け取りまでのように、配達相手の次の行動を予測することができる。
一方で、モデル再訓練のために導入したフィードバックループによって、推論されたラベルデータも大幅に改善された。詳細を掘り下げる前に、まず食品調理時間予測モデルについて説明したいと思う。
XGBoostで学習した勾配ブースト決定木を用い、Michelangeloプラットフォームが提供するハイパーパラメータチューニングを活用することで、モデルの精度と学習性能を向上させている。我々の調理時間モデルにおけるハイパーパラメータチューニングのアプローチは、ベイズ最適化である。基本的には、XGBoostが必要とするパラメータのすべての可能な組み合わせの中から、スマートな選択ができるようにしようという考えだ。
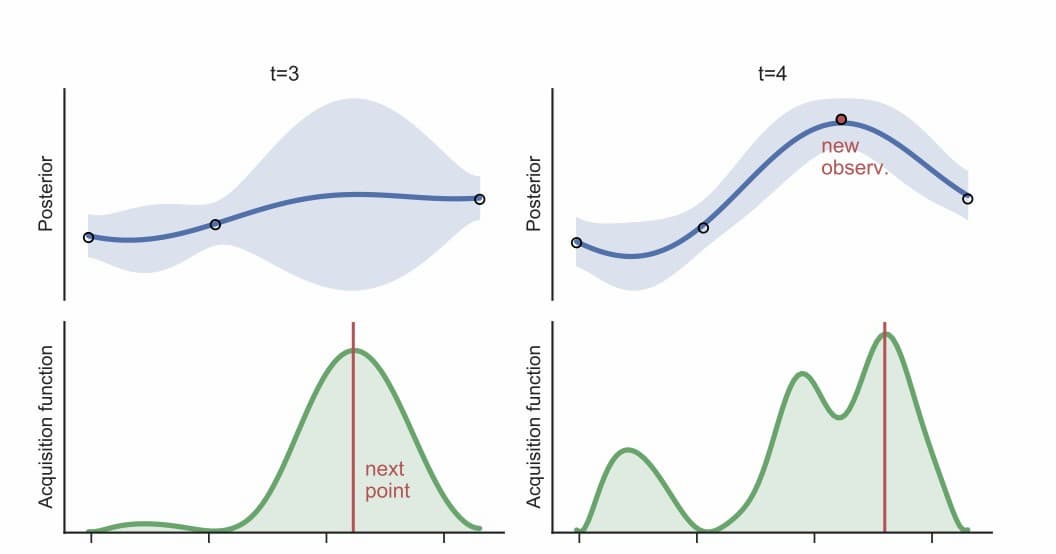
では、どのように機能するのでしょうか?左側のプロットを見ると、事後曲線はこれまでに試した3つのパラメータの組み合わせを示している。真ん中の大きな青い部分は、まだどの組み合わせも試していないので、あまり自信を持っていない部分を示している。次にどのような組み合わせを試すべきかを見極めるために、より良い結果が得られる可能性が高い組み合わせを教えてくれる獲得関数を作成した。右のプロットは、取得関数の推奨する組み合わせを試した後の結果を示している。
さて、何度も述べたフィードバック・ループに戻りましょう。これもまた、根拠のない真実がないために予測精度を向上させるという点で重要な要素だ。真の調理時間を推論しなければならないため、推論したデータと実際のデータの間には常に近似誤差が存在する。この誤差をいかに減らすかが最重要課題だった。我々は、近似誤差を適合させるためにモデルにフィードバックループを導入し、特に利用可能な新しい信号があった場合に、推定された調理時間を修正するのに役立った。例えば、実際の食品準備時間を暗示するために、より多くの情報を収集したかどうかを確認するために、各完了したオーダーをチェックする。そうであれば、その情報を用いて推論値を更新し、将来のモデル再訓練に利用することができる。
予測配達時間
時間予測のもう一つの重要な特徴は、予想配達時間(ETD)であり、これは注文のライフサイクル全体の中で、食べる人の経験に常に影響を与える。例えば、食べる人が自分の料理をどれくらい待つ必要があるのか気になったとき、まずETD予測をチェックすることができる。ETDと調理時間予測は、データ処理や機能工学などの点で多くの類似した技術を共有しているが、両者には多くの違いもある。
ETD予測のユニークな点は、途中で表面化したより多くの情報のために、異なるステージ間での変動があることだ。例えば、食者がレストランを閲覧しているときには、レストランの場所や料理の種類などの情報しかないため、予測することができない。食べる人が注文をするときには、注文した商品の数や価格など、より詳細な情報を得ることができる。注文を受け取る配送業者をマッチングしたときには、配送業者の移動時間の予測など、配送業者からさらに詳細な情報を得ることができる。したがって、当社のETD予測モデルは、ここでのすべてのバリエーションを処理するのに十分な柔軟性を持っている必要がある。
移動時間予測
時間予測で特筆すべき最後の機能は、移動時間の予測。Uber Eatsは、ライドビジネスのすべてのサポートがなければ、これほど短期間で飛躍的に成長することはできなかった。ドライバーを共有するだけでなく、共有プラットフォーム上で技術スタックを構築している。移動時間の推定もその一つです。1回の旅行で1秒1秒が重要なので、ライドにとっては超重要だ。乗り物に乗っている顧客は、旅行を依頼してからピックアップされ、目的地に到着するまでの旅行を追跡することができる。
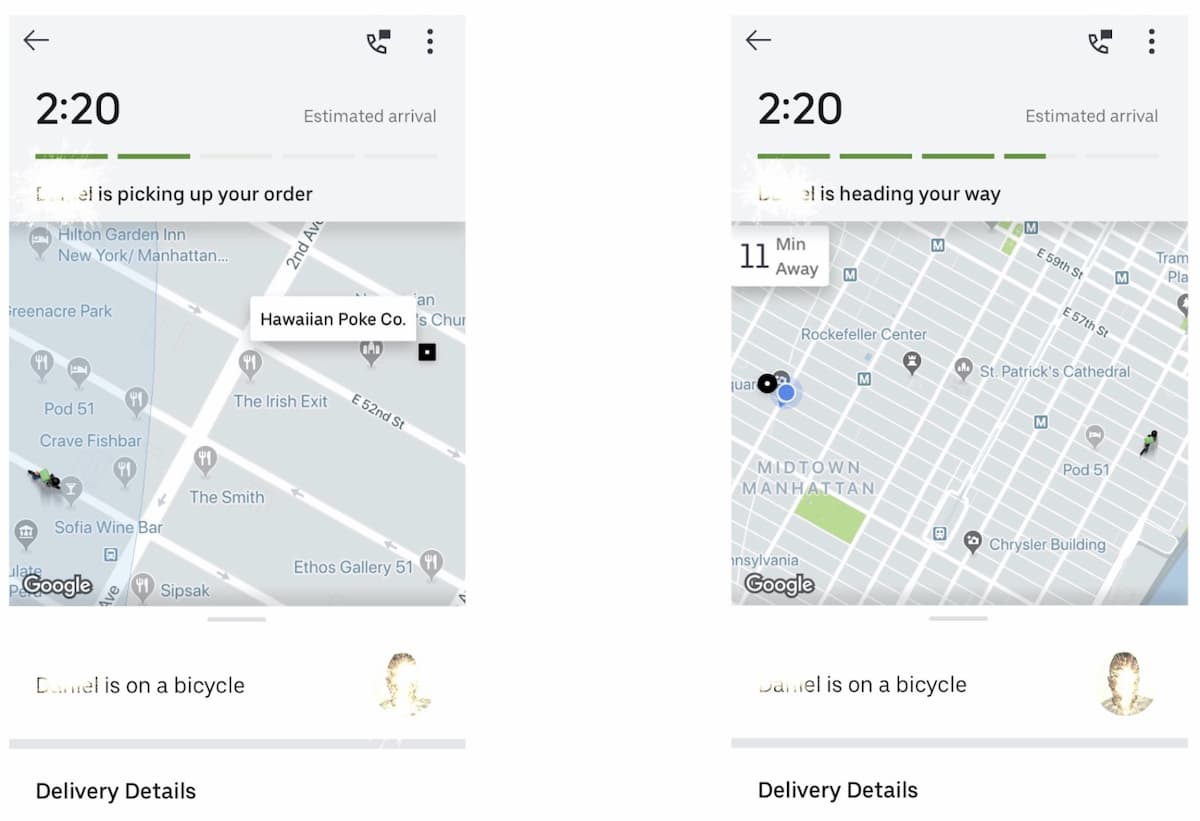
Uber Eatsの最大の違いは、バイカーやウォーカーなど、車以外のデリバリーパートナーがいることだ。ニューヨークやサンフランシスコのような大都市では、混雑や駐車場の問題などを避けるために、バイカーやウォーカーの方がはるかに効率的だ。このようなデリバリーパートナーのために正確な移動時間を予測することは、Eatsのビジネスにとって非常に重要だ。そのために、私たちはUberのMapsチームと協力して車以外のデータを収集し、新しいモデルを別途トレーニングしました。次の図は、バイカーが食べ物をピックアップするためにマッチングされ、彼の移動時間予測は11分であることを示している。
※本稿は、InfoQに掲載された「Predicting Time to Cook, Arrive, and Deliver at Uber Eats」(Zi Wang)を抄訳、編集したもの。
Photo by Uber
Special thanks to supporters !
Shogo Otani, 林祐輔, 鈴木卓也, Mayumi Nakamura, Kinoco, Masatoshi Yokota, Yohei Onishi, Tomochika Hara, 秋元 善次, Satoshi Takeda, Ken Manabe, Yasuhiro Hatabe, 4383, lostworld, ogawaa1218, txpyr12, shimon8470, tokyo_h, kkawakami, nakamatchy, wslash, TS, ikebukurou 太郎.
月額制サポーター
Axionは吉田が2年無給で、1年が高校生アルバイトの賃金で進めている「慈善活動」です。有料購読型アプリへと成長するプランがあります。コーヒー代のご支援をお願いします。個人で投資を検討の方はTwitter(@taxiyoshida)までご連絡ください。

投げ銭
投げ銭はこちらから。金額を入力してお好きな額をサポートしてください。



