
NLP
自然言語処理スタートアップがブーム: AIで最も進歩が早い分野
自然言語処理(NLP)スタートアップがブームだ。NLPはAIで最も進歩の早い分野で、基盤的なモデルを様々なユースケースに適応させる点において、既存ビジネスを塗り替える広範なビジネス機会が望まれている。
自然言語処理は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。形態素解析、N-gram解析、構文解析、意味解析・意味理解、格文法などの他、近年ではディープラーニングの活用により急速な進歩を遂げている。

NLP
自然言語処理(NLP)スタートアップがブームだ。NLPはAIで最も進歩の早い分野で、基盤的なモデルを様々なユースケースに適応させる点において、既存ビジネスを塗り替える広範なビジネス機会が望まれている。

NLP
銀行ではディープラーニングの導入ギャップがあり、その結果、ビジネスニーズを満たすのに十分な速さでAIモデルを構築・導入できていない。これらを解決するための自然言語処理モデルとハードウェアの組み合わせが提案されている。

NLP
メタは、「世界共通の音声翻訳機」を作成する、野心的なAI研究プロジェクトを発表した。機械翻訳がカバーしない言語を話す20%の人々を包含し、メタバースをより包摂的にする狙いがあるようだ。

NLP
DeepMindはさまざまなサイズの変換言語モデルを学習させた。その結果、読解力、ファクトチェック、有害言語の識別など、モデルの規模を大きくすることで継続的にパフォーマンスが向上する分野が明らかになった。

NLP
Google Brainの研究者たちは、より大きく、より良いものを追求し続ける中で、新たに提案したSwitch Transformer言語モデルを、計算コストを抑えながら1.6兆個のパラメータにまでスケールアップした。

NLP
MITの電気工学・コンピュータサイエンス学科の博士課程の学生であるHanrui Wangらは、計算機の性能に深く依存するAttentionの実行時のDRAMアクセスと計算量の両方を削減するためのテクニックとハードウェアを提案した。

NLP
OpenAIとスタンフォード大学の研究者が先週発表した論文は、GPT-3のような大規模な言語モデルが含んでいるマイノリティへのバイアスに対処するための緊急行動を呼びかけた。

NLP
科学検索エンジンの作成者は、研究論文の一文要約を自動的に生成するソフトウェアを発表した。この無料ツール「TLDR」は、ワシントン州シアトルの非営利団体であるアレン人工知能研究所(AI2)が作成した検索エンジン「Semantic Scholar」での検索結果を表示するために最近導入された。
NLP
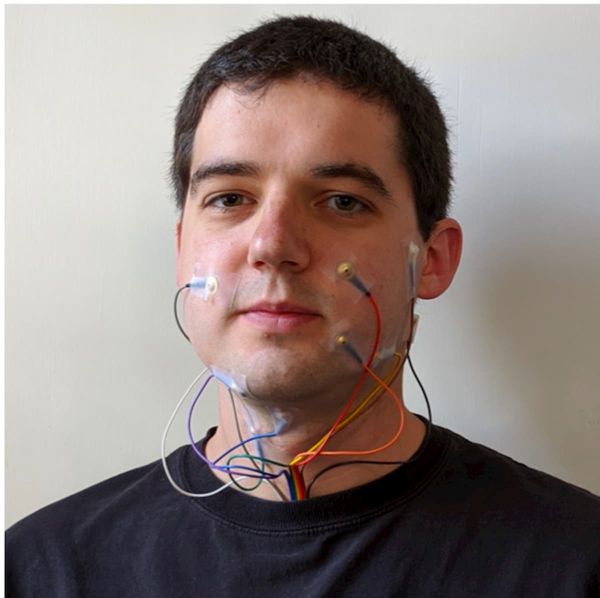
UCバークレー校の研究者らは、顔や喉に電極を当てて筋電図(EMG)を使って、無声発話を検出するAIシステムを開発することに成功した。このモデルは、音を出さずに発話された音声を筋肉感覚で測定することで、無声発話を実現する。特に、デジタルボイシングと呼ばれる、送信や再生のための合成音声を生成する作業に焦点を当てている。

NLP
Googleは、20日に発表されたホワイトペーパーの中で、オープンソースのツールを使用して、米国およびその他の国の1億件以上の特許公報に対してBERTモデルを訓練する方法を概説しており、これを使用して特許の新規性を判断し、分類を支援するための分類を生成することができるとしている。

NLP
MITのコンピュータ科学・人工知能研究所(CSAIL)の研究者たちは、歴史上滅びた言語を解読できるシステムを開発したと主張している。これはわずか数千語の体系化の後に失われた言語でも、解読できるシステムへの一歩だという。

NLP
Facebookは20日、英語データに頼らずに100言語の任意のペア間で翻訳できる初めてのアルゴリズムであるM2M-100をオープンソース化した。2,200の言語ペアで訓練されたこの機械学習モデルは、機械翻訳の性能を評価するために一般的に使用される指標において、英語中心のシステムを表向きは凌駕している。